










Table of Links
2 Related Work
2.1 Neural Codec Language Models and 2.2 Non-autoregressive Models
2.3 Diffusion Models and 2.4 Zero-shot Voice Cloning
3 Hierspeech++ and 3.1 Speech Representations
3.2 Hierarchical Speech Synthesizer
4 Speech Synthesis Tasks
4.1 Voice Conversion and 4.2 Text-to-Speech
5 Experiment and Result, and Dataset
5.2 Preprocessing and 5.3 Training
5.6 Zero-shot Voice Conversion
5.7 High-diversity but High-fidelity Speech Synthesis
5.9 Zero-shot Text-to-Speech with 1s Prompt
5.11 Additional Experiments with Other Baselines
7 Conclusion, Acknowledgement and References
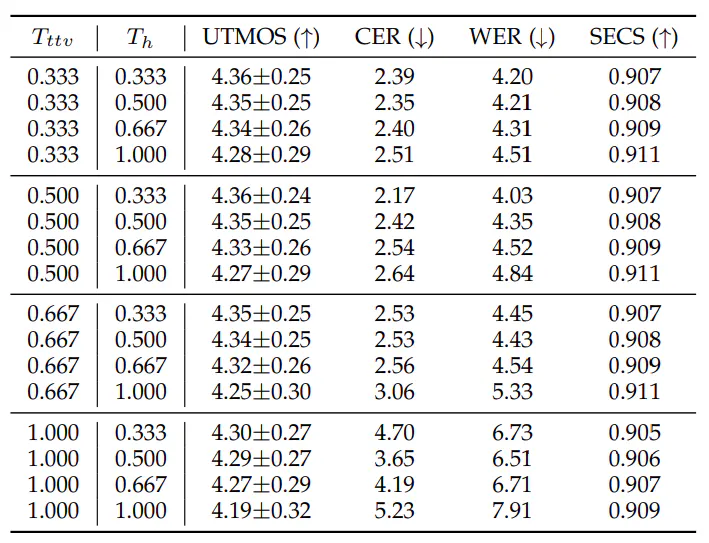
5.6 Zero-shot Voice Conversion
We compared the voice style transfer performance of HierSpeech++ with other basemodels: 1) AutoVC [66], which is an autoencoder-based non-autoregressive VC model using an information bottleneck to disentangle the content and style, 2) VoiceMixer [46], which is a GAN-based parallel VC model using similarity-based information bottleneck, 3- 5) Diffusion-based models (DiffVC [64], Diff-HierVC [11], and DDDM-VC [10]), 6) YourTTS [7], VITS-based end-to-end VC models utilizing phoneme sequences to extract content information, 7) HierVST [45], hierspeech-based end-to-end VC model using hierarchical style adaptation. For a fair comparison, we trained all model with the same dataset (LT460, train-clean-460 subsets of LibriTTS) without YourTTS. We utilized the official implementation of YourTTS which was trained with an additional dataset. We also trained the model with a large-scale dataset such as LT-960, all training subsets of LibriTTS) and additional datasets to verify the effectiveness of scaling-up the dataset.
For the subjective objective, TABLE 5 demonstrates that our model significantly improves the naturalness and similarity of the converted speech in terms of nMOS and sMOS. We found that our model with a large-scale dataset showed a better naturalness than ground-truth speech.
However, the results also showed that increasing the dataset without filtering noisy data slightly decreased an audio quality in terms of nMOS and UTMOS but the similarity increased consistently according to the data scale. In addition, WER also showed better performance than the other models. Furthermore, the results of the similarity measurement show that our models perform better in terms of the EER and SECS. Moreover, the results verified that HierSpeech++ which was trained with a large-scale dataset is a much stronger zero-shot speech synthesizer.
We will include zero-shot cross-lingual voice style transfer results and additional zero-shot voice conversion results with noisy speech prompts on our demo page. We highly recommend listening to the demo samples and will release the source code of the hierarchical speech synthesizer for a strong zero-shot speech synthesizer. Furthermore, we can also upsample the audio using SpeechSR from 16 kHz to 48 kHz, which can simply improve the perceptual audio quality as described in Section 5.10.

This paper is available on arxiv under CC BY-NC-SA 4.0 DEED license.
Authors:
(1) Sang-Hoon Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(2) Ha-Yeong Choi, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(3) Seung-Bin Kim, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea;
(4) Seong-Whan Lee, Fellow, IEEE with the Department of Artificial Intelligence, Korea University, Seoul 02841, South Korea and a Corresponding author.












