





9,546 reads
Winning arguments with data: Leading with commas in SQL?
by Felipe HoffaJuly 26th, 2017





Too Long; Didn't Read
Proposed SQL style guide:Companies Mentioned



Let’s analyze 320 Gigabytes of open source SQL code to determine if we should use trailing or leading commas. Popularity is not enough — can we determine which style leads to success?
Proposed SQL style guide:
- Prefer opening lines with a comma when needed.
- Don’t go and change all of the existing code just to comply with this rule.
Hypothesis: Writing SQL code with leading commas is efficient — but enforcing standards just for the sake of it kill those efficiencies. Can I prove this?
Background
Many programming languages (C, Python, JavaScript, Go, …) will allow you to leave a trailing comma after the final element in a list. But others won’t, like SQL (or the JSON format). This has lead a vocal minority to advocate in favor of a dreadful practice: Start new lines with a leading comma, in the name of efficient code writing and change management.
Would you prefer SQL code formatted like this:
# trailing commas
SELECT name,
company,
salary,
state,
city
FROM `employees`
WHERE state='CA'
or like this:
# leading commas
SELECT name
, company
, salary
, state
, city
FROM `employees`
WHERE state='CA'
Let’s bring the data
Luckily we all have access to terabytes of open source code ready to be analyzed in BigQuery. There is a huge table with all of the available extracted code — and your first step should be extracting only the code you are interested in, before performing further analysis.
To get all of the code inside “.sql” files out into a new table:
#standardSQL
SELECT a.id id, size, content, binary, copies,
sample_repo_name, sample_path
FROM (
SELECT id
, ANY_VALUE(path) sample_path
, ANY_VALUE(repo_name) sample_repo_name
FROM `bigquery-public-data.github_repos.files` a
WHERE PATH LIKE '%.sql'
GROUP BY 1
) a
JOIN `bigquery-public-data.github_repos.contents` b
ON a.id=b.id
This gives us a table representing a total of 2 million SQL files out of GitHub — more than 320 GB of code!

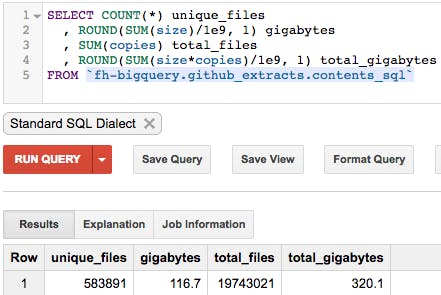
I left an improved public copy of this table in BigQuery —so you can skip this first step.
First approach: Count number of lines, files, repos
My first approach using data backfires:


Findings:
- There are 50 million SQL lines that end with a comma, while only 1.4 million begin with one.
- There are 329,308 unique SQL files with trailing commas, while only 18,312 have leading ones.
- There are at least 72,506 repositories with SQL files containing trailing commas, while only 3,360 repositories with leading ones.
- Summary: Leading commas lose the popularity race. There are way less projects and files using them.
Side note: There are also 5,647 SQL lines in 1,029 files that have commas at the beginning and the end. At least 360 repositories allow these monstrosities.
Second approach: Incorporate success metrics
Losing the popularity race is not the end of the road. We need to ask ourselves: “Which projects are more successful?”
How do we define success in GitHub? Number of stars? Number of stars last year? Number of stars this year? Number of active users? General activity levels? How about all of that!
The rules:
- Each repository gets one vote, regardless of number of lines or files.
- Files present in many repositories get assigned to the one with most stars.
- Repositories will get assigned to one of four groups: Only leading or trailing commas, no commas at the start of end of a line, or a mix of both styles.
These are my results:


What we see here:
- Only a small percentage of projects enforce leading commas, many more allow a mix of styles, and the majority only trailing commas. Most projects (at least 69,665 repos) show only trailing commas at the end of SQL lines. 571 repos show only leading commas, and 2,847 use a mix of both styles.
- Projects that allow a mix of styles show the most success. In average mixed style projects got 29.37 stars, 11.73 people involved, and >150 events during this year. In comparison SQL comma trailing only projects have 13.06 stars, 5.49 people involved, and less than 50 events this year (so far).
- Projects that enforce leading commas don’t show as much success as the mixed ones, but still seem to do better than the only trailing ones.
- The trend is stable throughout the years — comparing the total number of stars, the stars during 2016, and the stars, people, and activity during this ongoing 2017.
Query
#standardSQL
WITH comma_lines_per_files AS (
SELECT sample_repo_name, sample_stars_2016, sample_stars
, REGEXP_CONTAINS(line, r',\s*$') has_trailing
, REGEXP_CONTAINS(line, r'^\s*,') has_leading
, line
FROM `fh-bigquery.github_extracts.contents_sql`
, UNNEST(SPLIT(content, '\n')) line
WHERE line LIKE '%,%'
AND LENGTH(line)>5
), stats_per_repo AS (
SELECT sample_repo_name
, MAX(has_leading) has_leading
, MAX(has_trailing) has_trailing
, ANY_VALUE(line) sample_line
, ANY_VALUE(sample_stars) stars
, ANY_VALUE(sample_stars_2016) stars_2016
, (SELECT COUNT(DISTINCT actor.id) FROM `githubarchive.month.2017*` WHERE sample_repo_name = repo.name AND type='WatchEvent') stars_2017
, (SELECT COUNT(DISTINCT actor.id) FROM `githubarchive.month.2017*` WHERE sample_repo_name = repo.name) actors_2017
, (SELECT COUNT(*) FROM `githubarchive.month.2017*` WHERE sample_repo_name = repo.name) activity_2017
FROM comma_lines_per_files
GROUP BY sample_repo_name
)
SELECT COUNT(DISTINCT sample_repo_name) repos
, IF(has_trailing, IF(has_leading, 'both', 'trailing'), IF(has_leading, 'leading', 'none')) commas
, ROUND(AVG(stars), 2) avg_stars
, ROUND(AVG(stars_2016), 2) stars_2016
, ROUND(AVG(stars_2017), 2) stars_2017
, ROUND(AVG(actors_2017), 2) actors_2017
, ROUND(AVG(activity_2017), 2) activity_2017
, STRING_AGG(sample_repo_name ORDER BY stars DESC LIMIT 3) top_repos
FROM stats_per_repo
GROUP BY commas
ORDER BY repos
repos commas stars stars17 actors17 activity17 top_repos
571 leading 22.99 7.36 10.04 39.89 drone/drone,aspnetboilerplate/aspnetboilerplate,HazyResearch/deepdiv2847 both true 29.37 6.44 11.73 156.63 apache/spark,begriffs/postgrest,mybatis/mybatis-3
5933 none false 20.05 4.8 7.57 54.43 ajaxorg/ace,zulip/zulip,fivethirtyeight/data
69665 trailing false 13.06 3.22 5.49 43.68 Microsoft/vscode,rails/rails,kubernetes/kubernetes
Bibliography
- Dan Nguyen asks about SQL formatting on Twitter.
- Elliott’s first data attempt to answer.
- Reddit discusses early results.
- Go forces a trailing comma.
- More SQL analysis over the GitHub repos in BigQuery.
Next steps
Want more stories? Check my Medium, follow me on twitter, and subscribe to reddit.com/r/bigquery. And try BigQuery — every month you get a full terabyte of analysis for free.

L O A D I N G
. . . comments & more!
. . . comments & more!












