









Introduction
Using Kubernetes for distributed inferences enhances your machine-learning models and optimizes their speed and cost. Such a production environment can be a boon for any enterprise. This blog provides you with some strong rationale to use Kubernetes on large AI/ML datasets on which distributed inferences are performed.
Challenges of performing Distributed Inferences on Large Datasets
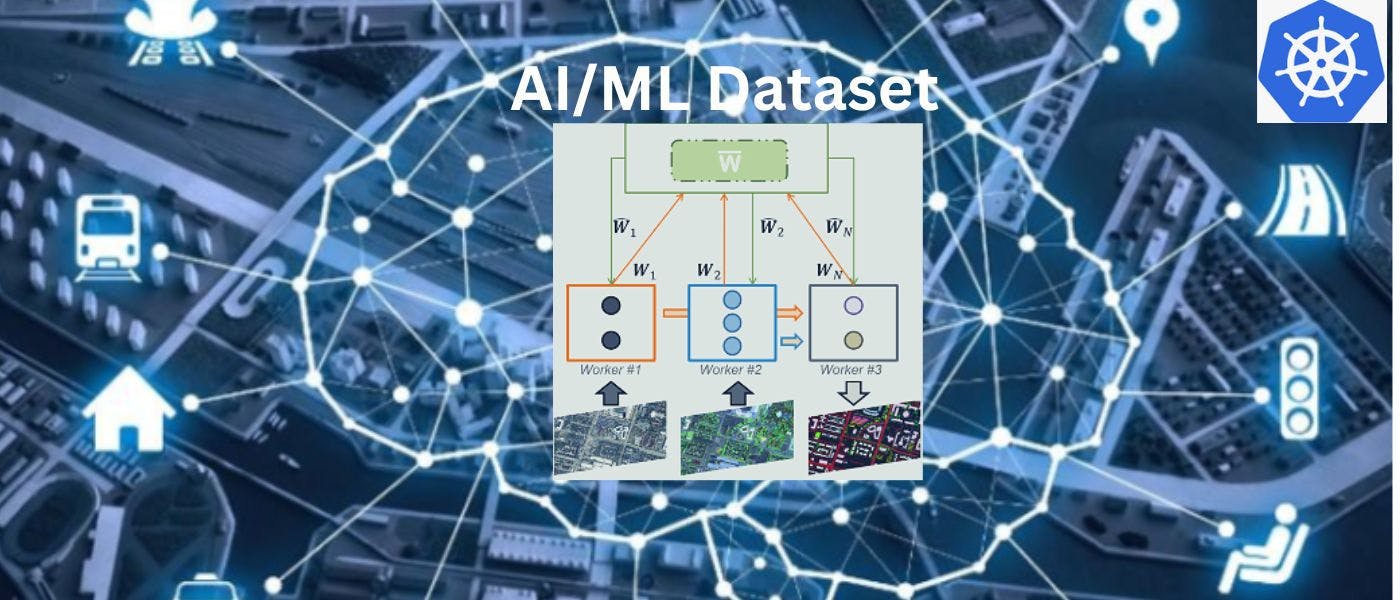
Distributed inferences are typically carried out on big datasets with millions of records or more. A cluster of machines equipped with deep learning capabilities is necessary to process such enormous datasets on time. Through the use of job parallelization, data segmentation, and batch processing, a distributed cluster can process data at high throughput. However, establishing a deep learning data processing cluster is difficult and this is where Kubernetes is helpful:
- Setting up and Managing a Cluster:
This includes deploying and configuring software packages, monitoring nodes, ensuring high availability, and more.
- Management of Resources and Jobs:
Scheduling and monitoring of jobs, data splitting, and handling of failed jobs.
-
Managing Deep Learning Workloads:
The deployment, configuration, and execution of deep learning tasks.
How Kubernetes Helps Your AI/ML Teams With Resource Management and Optimization
The world of machine learning is changing rapidly. AI/ML teams have access to more data than ever before, but they need to be able to process this data in ways that are most relevant to their customers.
Using Kubernetes for distributed inferences gives your AI/ML team lots of ways to manage the resources needed for their work, including using node pools, horizontal pod autoscaler (HPA), role-based access control (RBAC), and custom resource definitions (CRDs). By understanding these options for managing resources on your cluster, you'll be able to optimize how much compute power gets used across multiple nodes or clusters as well as make sure only essential services run at any given time—all while keeping costs low.
Large Datasets
If you want to use Kubernetes for distributed inference on large datasets, the first thing you should do is ensure that your dataset is stored in a file system.
It’s not enough to simply have a distributed file system; it has to be distributed across multiple nodes (or servers) and/or cloud providers.
Node Pools and Cluster Autoscaler
Node Pools allow you to specify a minimum and the maximum number of nodes that are available for use by the cluster. These values can be set independently on each machine, which means they can be used in different ways depending on how much data needs to be processed at any given time.
Cluster Autoscaler automatically adjusts the number of nodes in your Kubernetes cluster based on the current workload, so if you have fewer machines available than what you expect (for example, due to maintenance), it will automatically add more machines until there are enough resources available again.
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler is a feature that automatically scales the number of pods in a replication controller based on CPU and memory usage, as well as custom metrics. To use this feature, you need to set up a custom label for horizontal pod autoscaler. The following examples show how to configure this label:
[horizontal-pod-autoscaler-label] = "cpu"
The above value indicates whether or not your cluster should scale based on CPU utilization. If it's present, then horizontal pod autoscaler will be enabled when more than 50% instances are running on CPUs at any given moment; otherwise, it won't be enabled unless requested by an administrator (for example during disaster recovery).
[horizontal-pod-autoscaler] = "memory"
The above value indicates whether or not your cluster should scale based on memory utilization. If it's present, then horizontal pod autoscaler will be enabled when there are more than 50% instances running in memory; otherwise, it won't be enabled unless requested by an administrator (for example during disaster recovery).
Custom Resource Definitions
Custom Resource Definitions (CRDs) are a way to define new resources for Kubernetes. They provide a simple, flexible way to add new types of resources to your apps without having to write code or build them from scratch.
An example of a CRD that could be used for AI models looks something like this:
```yaml apiVersion: v1 kind: ClusterSpec metadata: name: my-cluster spec: replicas : 1 templates : - metadata : labels : app : kube - apiVersion : apps/v1 kind : App name : example-app --- apiVersion: apps/v1 kind: Job name : example-job sourceFunctionality : --sourceFunctionality "models" --- apiServerPortNames:[443](*) appName:"example-"
Role-based Access Control
A role-based access control (RBAC) model is a way to control access to Kubernetes resources. For example, you can allow one user to create deployments but not others.
Roles are groups of permissions that define the level of access a user has within your cluster. For example, you may have users who are allowed only read-only operations on a particular pod or service while others have full control over it. You can create different roles for each type of operation so that if one user tries to perform an action with which they do not have permission, another user will be able to take over their role and continue working instead!
Kubernetes gives your AI/ML team lots of ways to manage the resources needed for their work.
Kubernetes is an open-source system for automating the deployment, scaling, and management of containerized applications. It's a good fit for AI/ML applications because it can manage the resources needed to run them.
Kubernetes gives your AI team lots of ways to manage the resources needed for their work.
Conclusion
When you're working on AI/ML applications that require large datasets and applying distributed inferences; it can be tempting to use them directly. However, this is not always the best option. By using Kubernetes and other management & monitoring tools, you can manage your data more efficiently and reliably so that it doesn't get lost or become too large for your application.












