






2,785 reads
What Is Weaviate And How To Create Data Schemas In It
by Laura HamMay 12th, 2021




Too Long; Didn't Read
Weaviate is a search engine that stores data as vectors, with a graph-like data model. A well-defined data Schema is key to meaningful insights of your data. The data schema you need to define is relatively simple and easy to do with a simple class and property. Weaviates uses a class-property structure, inspired by the RDF-inspired RDF Schema, to place data objects into context and derive its meaning. This article is not only a tutorial for creating your own schema, but also explains what a schema is and why you need one.Coin Mentioned



What is a schema, why you need one and how to define one to store your own data.
Weaviate is a vector-native database: data is stored as vectors in a high-dimensional space. In order to store and retrieve vector data, Weaviate uses a data schema which is unique per instance. Once you have started up a Weaviate instance (via docker-compose, Kubernetes or using the Weaviate Cluster Service), you need to create a data schema before you can add and query data.
Like most other databases, a database schema defines the structure described in a formal language. It is a sort of blueprint of how the data is structured in a database. The data schema you need to define for Weaviate is relatively simple. It consists of classes and properties definitions and how they are related to each other. Due to Weaviate’s vectorization modules, the classes and properties you add will be automatically placed in context.
This article is not only a tutorial for creating your own schema, but also explains what a schema is and why you need one. Ultimately, understanding what you’re creating a schema for will help you in making your own.
What is a Weaviate data schema and why do you need one?
RDF-inspired
Just like most databases, Weaviate needs a data schema. Weaviate uses a class-property structure, inspired by the RDF Schema. RDF Schemas have classes with properties and relations, and are used as ontology to represent knowledge. Born out of this RDF-like perspective is the Weaviate schema with classes, properties and relations. Weaviate uses the data schema to place data objects into context and derive its meaning. A schema is thus an essential part for Weaviate to understand your data objects. A well-defined schema (read on to learn best practices for creating a schema) is key to meaningful insights of your data.
Graph-like data model
You can make relations between data objects in Weaviate. You can see the data schema with cross references as a graph-like data model. But keep in mind that Weaviate is not a Graph database. Instead, Weaviate is a search engine that stores data as vectors, with a graph-like data model. Typical graph database tasks like shortest path prediction are not part of Weaviate’s features. In Weaviate, data objects, which are nodes in the graph, get a vector position.
Data is thus stored in a space according to its meaning, and can still be connected to other data entities. Storing the (graph) data as vectors has huge advantages when it comes to automatic classification, prediction of data relations, semantic search and deriving insights.
How to define a Weaviate data schema
Class - property structure
Data objects in Weaviate always belong to a class. A class describes the data object in the form of a noun or a verb. Every class is defined in the schema, and can have one or more properties. Properties define the actual data values of the objects in your dataset. Properties have a
namedataTypestringintSchema design example
Let’s make a data schema for an open wine review dataset from Kaggle. This dataset consists of 150k wine reviews scraped from WineEnthusiast. It contains wine titles, descriptions, points (score 0-100 given by the reviewer), prices, designations, regions, provinces, countries, varieties, wineries and reviewers. To keep the example for this tutorial simple, I’m leaving out the regions and reviewers. Now, let’s see how we can design a good data schema.
An obvious first class to create is
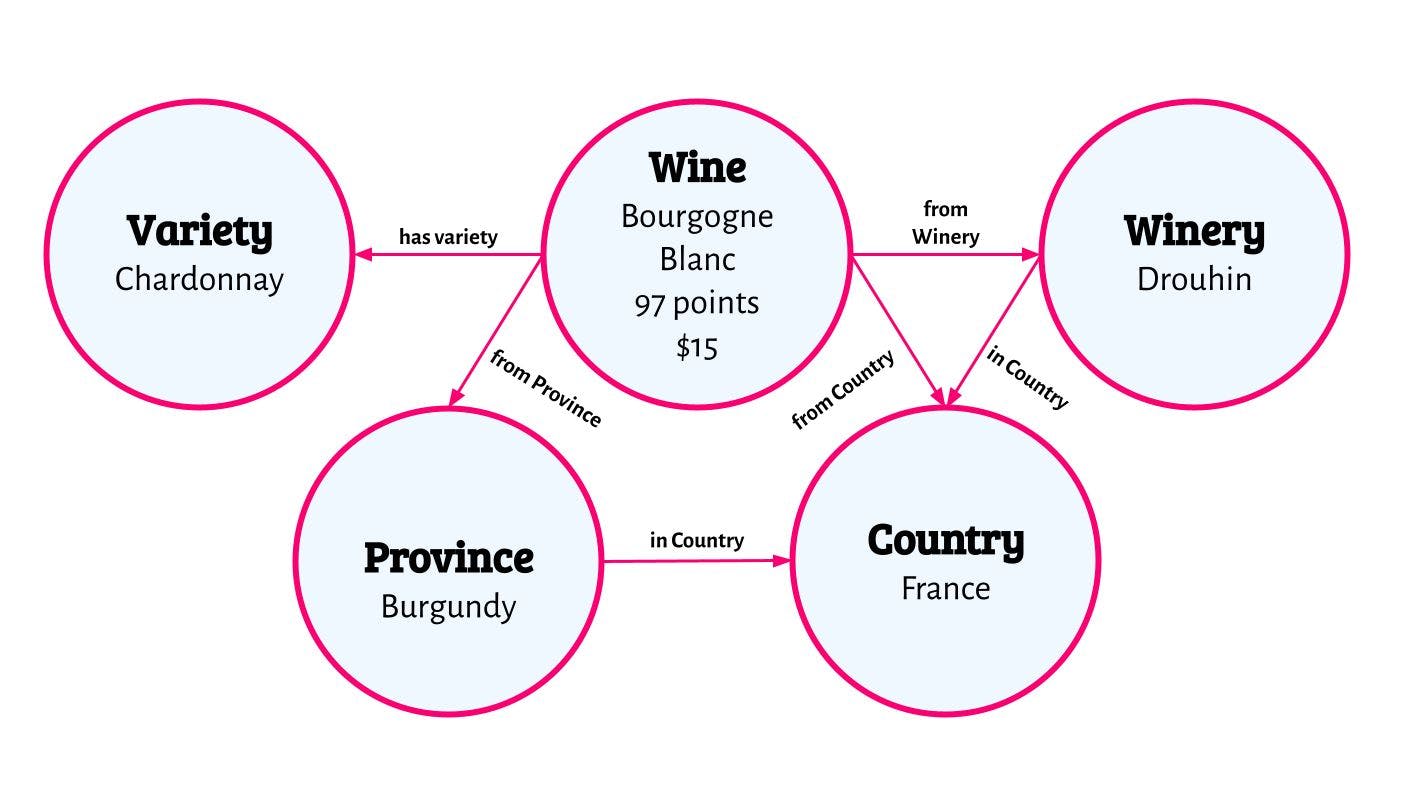
WineWineSimilarly, there is a limited set of wine varieties (e.g. Chardonnay, Pinot Noir, etc). The same holds for provinces and wineries. We decide to let these characteristics have their own class. The figure below shows which classes we have now.


Classes
We now have five classes. All classes have a unique name. A class name always starts with a capital letter. A good class name is descriptive of the data objects that you will add to this class. If you want to use multiple words for a class or property name, concatenate the words according to the CamelCase (for class names) or camelCase (for property names) rule. In addition to naming the classes, we can add a
descriptionWine{
"class": "Wine",
"description": "A wine that has been tasted and reviewed",
"properties": []
}
Properties
Leaving relations between the classes out for now, the class Wine has five properties, while the other four classes only have a unique name. Property names always start with a lowercase letter. Again, in addition to naming the properties, we can add a description. With the original dataset in mind, we define the properties. We extend the Wine class with its properties as follows [1] [2].
{
"class": "Wine",
"description": "A wine that has been tasted and reviewed",
"properties": [
{
"name": "title",
"description": "The name of the wine",
"dataType": ["text"]
},
{
"name": "description",
"description": "The review of the wine",
"dataType": ["text"]
},
{
"name": "designation",
"description": "The vineyard within the winery where the grapes that made the wine are from",
"dataType": ["string"]
},
{
"name": "points",
"description": "Points 0-100 given by the reviewer",
"dataType": ["int"]
},
{
"name": "price",
"description": "The price of the wine in dollars",
"dataType": ["number"]
}
]
}Cross-references
As mentioned before, the four classes
VarietyProvinceCountryWineryWineWineWine

Assuming we have the classes
“Wine”“Variety”“Province”“Country”“Winery”“Province”"Country"“inCountry”“Country”{
"class": "Province",
"description": "A defined region in a country",
"properties": [
{
"name": "name",
"description": "The name of the province",
"dataType": ["string"]
},
{
"name": "inCountry",
"description": "The country the province belongs to",
"dataType": ["Country"]
}
]
}Advanced schema configuration
For data classes, you need to define at least the name of the class in
“class”For class properties, defining the
“name”“dataType”“indexInverted”falsetrueUpload data schema
You can upload an entire data schema to a running Weaviate instance at once using the Python client. Alternatively, you can add classes one by one using other clients or with an HTTP request. Make sure classes exist before you use them in a reference property.
Example of importing a full schema with the Python client to Weaviate running on http://localhost:8080.
import weaviate
client = weaviate.Client("http://localhost:8080")
schema = {
"classes": [
{
"class": "Wine",
"description": "A wine that has been tasted and reviewed",
"properties": [
{
"name": "title",
"description": "The name of the wine",
"dataType": ["text"]
}, {
"name": "description",
"description": "The review of the wine",
"dataType": ["text"]
}, {
"name": "designation",
"description": "The vineyard within the winery where the grapes that made the wine are from",
"dataType": ["string"]
}, {
"name": "points",
"description": "Points 0-100 given by the reviewer",
"dataType": ["int"]
}, {
"name": "price",
"description": "The price of the wine in dollars",
"dataType": ["number"]
}, {
"dataType": ["Country"],
"description": "The country the wine is from",
"name": "fromCountry"
}, {
"dataType": ["Province"],
"description": "The province or state that the wine is from",
"name": "fromProvince"
}, {
"dataType": ["Variety"],
"description": "The type of grapes used to make the wine (ie Pinot Noir)",
"name": "hasVariety"
}, {
"dataType": ["Winery"],
"description": "The winery that made the wine",
"name": "fromWinery"
}
]
}, {
"class": "Country",
"description": "A country which produces wine",
"properties": [
{
"dataType": ["string"],
"description": "The name of the country",
"name": "name"
}
]
}, {
"class": "Province",
"description": "A defined region or state of a country",
"properties": [
{
"dataType": ["string"],
"description": "The name of the country",
"name": "name"
}, {
"dataType": ["Country"],
"description": "The country the province lies in",
"name": "inCountry"
}
]
}, {
"class": "Variety",
"description": "The type of grapes a wine is made of",
"properties": [
{
"dataType": ["string"],
"description": "The name of the variety, which is the name of the grape",
"name": "name"
}
]
}, {
"class": "Winery",
"description": "A wine producer",
"properties": [
{
"dataType": ["string"],
"description": "The name of the winery",
"name": "name"
}, {
"dataType": ["Country"],
"description": "The country the province lies in",
"name": "inCountry"
}
]
}
]
}
client.schema.create(schema)Conclusion
In this article, you learned what a Weaviate data schema is, why you need one and how to design one. The full example code can be found here. Learn more about module specific schema configuration here, and other property data types like geo-coordinates, phone numbers and dates here. After designing a data schema, you can start uploading data to Weaviate!
- [1] Note that
is a“designation”
property, while“string”
and“title”
are“description”
properties.“text”
values are indexed as one token, whereas“string”
values are indexed after applying tokenization.“text”
as string would be indexed as“[email protected]”
and also only match that in a GraphQL where filter, whereas as text it would be indexed as“[email protected]”
and also match the individual words.['jane', 'doe', 'foobar', 'com'] - [2] For more property dataType options, check the documentation.

L O A D I N G
. . . comments & more!
. . . comments & more!












