











Google’s MLKit library finds text in images and this works well for simple text but for tabular data such as receipts or tables, it does not. If you’ve ever used an OCR app you might have noticed that it works reasonably well when scanning a page with uniform text but when dealing with any kind of tables or text formatting, it just falls flat.
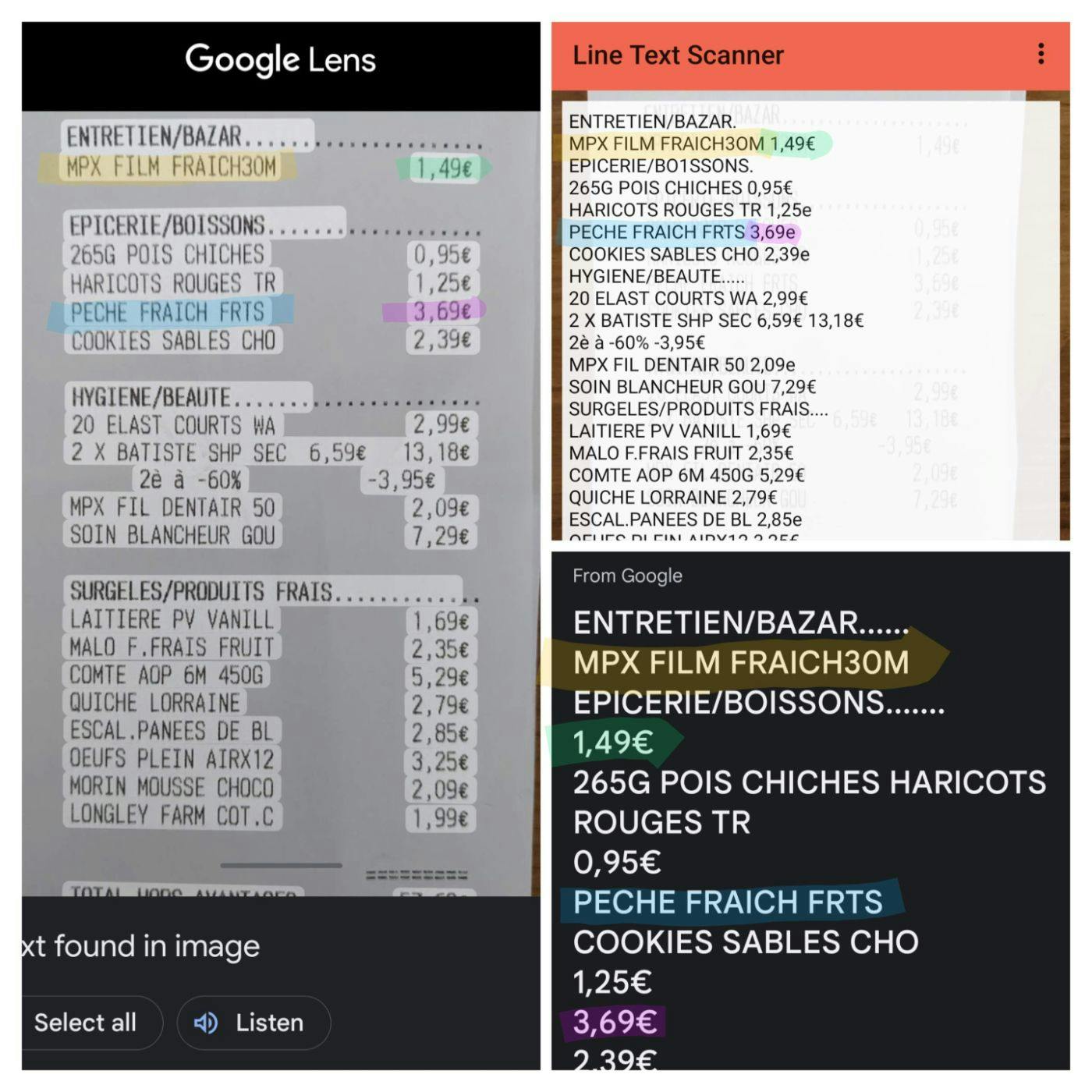
This article discusses an algorithm used in a mobile application I wrote that processes text to keep it in line. We’ll take a common example of a store receipt. In the example below you can see exactly the problem that I’m trying to solve. Google Lens does not prefer lines for text but will rather put together text that is physically closer together. This works sometimes but definitely does not work for receipts and other tabular data. See specifically how Google Lens put the price 1,49€ as a new line because it was physically far away from the lines on the left.
Line Text Scanner is an application developed specifically to scan tabular data and the results of scanning a receipt are in the top right corner. You can see how it respected the horizontal layout of the receipt and put the price together with the correct article.

Google OCR library
Here is a quick overview of how to use the OCR library: load an image and get text. Recognition of characters happens entirely on Google’s side.
InputImage image = InputImage.fromBitmap(mSelectedImage, 0);
TextRecognizer recognizer = TextRecognition.getClient();
recognizer.process(image)
.addOnSuccessListener(
new OnSuccessListener<Text>() {
@Override
public void onSuccess(Text texts) {
processTextRecognitionResult(texts);
}
})
.addOnFailureListener(
//
});
Full documentation is here and the diagram below is from this link.
Once we have the Text object we can begin our own logic. We’ll try to process Text to do better than Google Lens. First, we need to look at the Text object. Text is a hierarchical representation of the scanned text as seen in the following diagram from Google’s documentation.


The algorithm looks for characters and words in physical space and puts them into a hierarchical structure. As mentioned, this works well for easy text as in the diagram above but for tabular data like a receipt it does not. Below we have the full text of the receipt scanned by Google Lens.
ENTRETIEN/BAZAR......
MPX FILM FRAICH30M
EPICERIE/BOISSONS.......
1,49€
265G POIS CHICHES HARICOTS ROUGES TR
0,95€
PECHE FRAICH FRTS
COOKIES SABLES CHO
1,25€
3,69€
2,39€
HYGIENE/BEAUTE.......
2,99€
20 ELAST COURTS WA
2 X BATISTE SHP SEC 6,59€ 13,18€
2è à -60%
-3,95€
MPX FIL DENTAIR 50 SOIN BLANCHEUR GOU
2,09€
7,29€
SURGELES/PRODUITS FRAIS...........
LAITIERE PV VANILL
1,69€
MALO F.FRAIS FRUIT COMTE AOP 6M 450G
2,35€
5,29€
QUICHE LORRAINE ESCAL.PANEES DE BL
2,79€
OEUFS PLEIN AIRX12
2,85€
MORIN MOUSSE CHOCO
3,25€
2,09€
LONGLEY FARM COT.C
1,99€
TOTAL HORS AVANTAGES
57,62€
18
NOMBRE D'ARTICLES
I think that you’ll agree that this is not very useful. The algorithm picked the columns first rather than the rows. It made new lines for text that was far away. This is the difference in text processing that this article explores.
Processing Text
To demonstrate what MLKit does I’ve modified the application to only output the index of Text Elements (those are boxes with dark green border in the diagram from Google). In the screen below we can see text blocks 0 to 31. We can see how the MLKit library prefers physical distance to group words together into phrases. This is not exactly what Google Lens has outputted. We can see that Google Lens made the price of 1,49€ below the first three lines. It treated the text blocks differently but didn’t manage to output clear lines.


As seen from this output, the OCR library makes up block 0 as ‘Entrentien/Bazar. MPX FILM FRAICH30M’. The second block is made up of multiple lines of the left column. The library continues to create text blocks from the left column and then moves to the right column to create the text blocks from prices.
The image is correctly converted into characters and words. We’ll use these words but do it using a different algorithm to prefer lines to make our sentences. It’s clear that Google Lens also processes these blocks but obviously in yet another way.
Breaking boxes
Now to our algorithm. The first thing we’ll do is process all the TextBlocks from Text to extract the individual lines. Each line has one or more Text.Element object and we extract them all and put them into a single list.
List<Text.Element> textElements = new ArrayList<>();
for (int i = 0; i < blocks.size(); i++) {
Rect rect = blocks.get(i).getBoundingBox();
List<Text.Line> lines = blocks.get(i).getLines();
for (int j = 0; j < lines.size(); j++) {
List<Text.Element> elements = lines.get(j).getElements();
for (int k = 0; k < elements.size(); k++) {
Text.Element e = elements.get(k);
textElements.add(e);
}
}
At this point, we have an array of Text.Element objects which all contain some text. In our example, the four Text.Elements in block 0 are 'ENTRETIEN/BAZAR......’, ‘MPX’, ‘FILM’, and ‘FRAICH30M’. All of the elements are put into a list.


Sorting boxes
So now that we have all these Text.Element objects in a list, how do we determine what goes after what? As seen from above, the OCR algorithm just recognized blocks of text but it made no effort to make correct sentences. First, we need to realize that Text.Element object is bound by Rect object which has coordinates and dimensions. We use this fact to sort the Text.Elements.
We take the top and left coordinates of the rectangles and sort them:
public int compare(Text.Element t1, Text.Element t2) {
int diffOfTops = t1.getBoundingBox().top - t2.getBoundingBox().top;
int diffOfLefts = t1.getBoundingBox().left - t2.getBoundingBox().left;
int height = (t1.getBoundingBox().height() + t2.getBoundingBox().height()) / 2;
int verticalDiff = (int)(height * 0.35);
int result = diffOfLefts;
if (Math.abs(diffOfTops) > verticalDiff) {
result = diffOfTops;
}
return result;
}
The main decision in this algorithm is to decide whether one rectangle should go after another based on whether it is more to the right of it or more below it. The horizontal difference is easy, if one rectangle has coordinates more to the left of another rectangle then it will come before it. But this will be taken into consideration only if the difference in the tops is more than 35% height of the line. Basically, we allow for some skew in the picture-taking where the text might not align perfectly. But if a rectangle is 35% the height of the current rectangle below the next rectangle then we consider it as another line.
Overall, in our algorithm, we prefer horizontal lines along which we can find the Text.Element objects.
Making lines
In this final processing step, we will make lines by processing the list above. Remember that the list just has rectangles and so we need to add a condition based on coordinates to decide whether to start a new line. To do this, we get the difference between the top of the boxes and take the average of their height. We don’t check the difference in location on the horizontal axis as we already did that when sorting boxes. Here we just have one decision to make: whether or not to make a new line.
private boolean isSameLine(Text.Element t1, Text.Element t2) {
int diffOfTops = t1.getBoundingBox().top - t2.getBoundingBox().top;
int height = (t1.getBoundingBox().height() + t2.getBoundingBox().height()) * 0.35;
if (Math.abs(diffOfTops) > height ) {
return false;
}
return true;
}
This finally gives us the well-formatted tabular text.


Here is the full text again.
ENTRETIEN/BAZAR.
MPX FILM FRAICH3OM 1,49€
EPICERIE/BO1SSONS.
265G POIS CHICHES 0,95€
HARICOTS ROUGES TR 1,25e
PECHE FRAICH FRTS 3,69e
COOKIES SABLES CHO 2,39e
HYGIENE/BEAUTE.....
20 ELAST COURTS WA 2,99€
2 X BATISTE SHP SEC 6,59€ 13,18€
2è à -60% -3,95€
MPX FIL DENTAIR 50 2,09e
SOIN BLANCHEUR GOU 7,29€
SURGELES/PRODUITS FRAIS....
LAITIERE PV VANILL 1,69€
MALO F.FRAIS FRUIT 2,35€
COMTE AOP 6M 450G 5,29€
QUICHE LORRAINE 2,79€
ESCAL.PANEES DE BL 2,85e
OEUFS PLEIN AIRX12 3,25€
MORIN MOUSSE CHOCO 2,09e
LONGLEY FARM COT.C 1,99e
TOTAL HORS AVANTAGES 57,62e
NOMBRE D'ARTICLES 18
Conclusion
The solution to process the text in lines in this article is not without faults. The text should be relatively straight and not skewed too much. With some effort, we could calculate the vectors of lines even in the most crumpled receipt but that would be for another article. Here we show how a small tweak in treating the output of a large library can have a big effect for a very specific purpose. If you think that this is useful to you, the app is available in the Google Play Store.











