












Inserting large records from a spreadsheet (CSV file) to a database is a very common and hard engineering problem to solve for numerous reasons. Modern data stack ETL tools may solve the problem.
But what if?
-
You are a javascript (NodeJS) person.
-
You don't want to invest money on an ETL tool.
-
You are not a data engineer who knows how to create and maintain data pipelines.
-

Node.js streams are a powerful and flexible mechanism for reading and writing data in a streaming fashion. Streams provide an efficient way to handle large volumes of data by processing it in small chunks, rather than loading it all into memory at once.
So we are going to solve this problem using Node Stream.

How NodeJS Stream is Going to Help Us!!
In Node.js, a stream is an abstract interface that represents a sequence of data. A stream can be thought of as a flow of data that is divided into chunks, and these chunks can be processed incrementally as they become available.
Streams can be used to read or write data from various sources, such as files, network sockets, or even in-memory data structures. Streams in Node.js are implemented using event emitters, which means that they can be used asynchronously and in a non-blocking way.
Current Architecture Used to Solve This Problem?
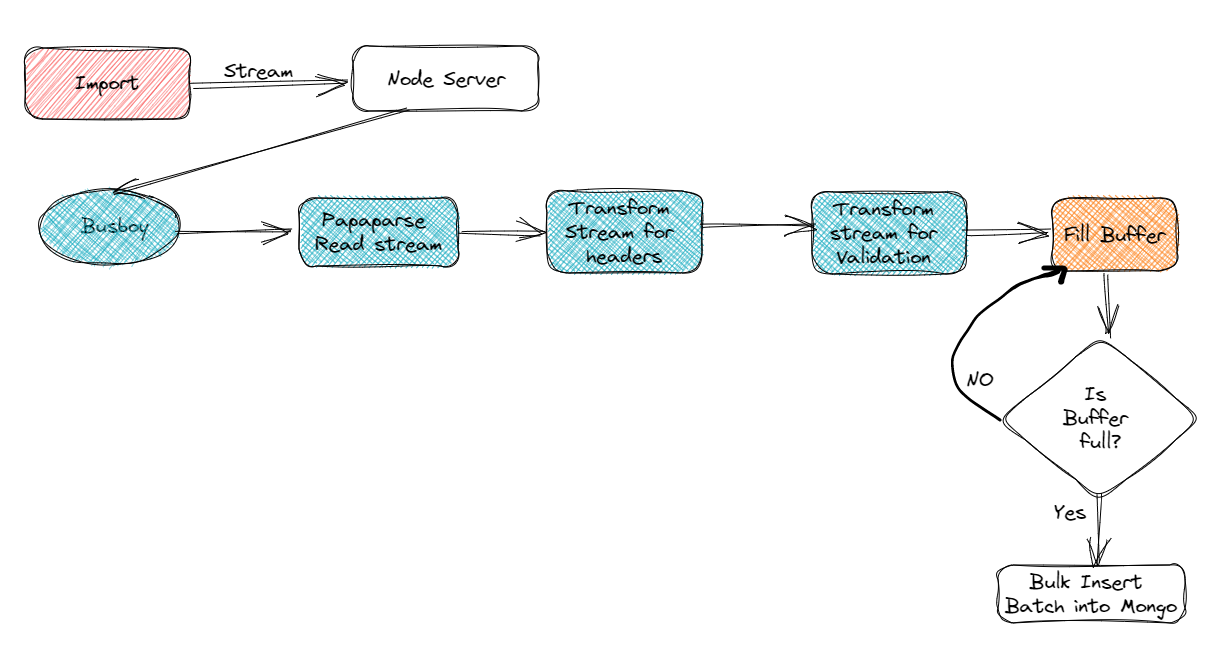
Step 1
A drop zone is created to provision a place to drag and drop the csv file.
const onDrop = useCallback((acceptedFiles) => {
setFiles((prevFiles) => [...prevFiles, ...acceptedFiles]);
}, []);
const { getRootProps, getInputProps, isDragActive } = useDropzone({ onDrop });
return(
<>
<div
className={`px-6 pt-5 pb-6 border-2 border-dashed rounded-lg ${
isDragActive ? "border-green-400" : "border-gray-400"
}`}
{...getRootProps()}
>
<input {...getInputProps()} />
<div className="flex flex-col items-center justify-center text-center space-y-1">
<PlusIcon className="w-8 h-8 text-gray-400" />
<p className="text-sm font-medium text-gray-400">
Drop files here or click to upload
</p>
</div>
</div>
{files.map((file) => (
<p
key={file.name}
className="mt-2 text-sm font-medium text-gray-500 truncate"
>
{file.name} ({file.size} bytes)
</p>
))}
</>)
Step 2
Create the rest api to starting streaming.
busboy.on(
'file',
async function (fieldname, file, filename, encoding, mimetype) {
console.log('The file details are', filename, encoding, mimetype);
}
pipeline(stream1, stream2)
)
Here we have used Busboy library so as to directly stream the data instead of copying it to a location on a server and then moving into MongoDB.
The pipeline function from the node js stream will be used for giving a flow for the parsing, then transforming and inserting into Mongodb.
pipeline(
file,
openCsvInputStream,
headers_changes,
dbClient.stream,
(err) => {
if (err) {
console.log('Pipeline failed with an error:', err);
} else {
console.log('Pipeline ended successfully');
}
}
);
Step 3
Here the papaparse stream is the first stage on the pipeline. Papaparse is a high speed parsing library for parsing huge csvs into json format. But, we need a stream of the huge amount of csv data which will be passed to the next stages of the transformation.
The following code creates a readable stream out of papaparse input stream:
const openCsvInputStream = (fileInputStream) => {
const csvInputStream = new Readable({ objectMode: true });
csvInputStream._read = () => {};
Papa.parse(fileInputStream, {
header: true,
dynamicTyping: true,
skipEmptyLines: true,
step: (results) => {
csvInputStream.push(results.data);
},
complete: () => {
csvInputStream.push(null);
},
error: (err) => {
csvInputStream.emit('error', err);
},
});
return csvInputStream;
};
Step 4
This is where the transformation streams come into the picture.
var headers_changes = new Transform({
readableObjectMode: true,
writableObjectMode: true,
});
headers_changes._transform = async function (data, enc, cb) {
var newdata = await changeHeader({
oldColumns,
newColumns,
});
headers_changes.push(newdata);
cb();
};
This header change transformation changes the old column header names into new header names. The catch is, this is a transformer stream. Once the data is transformed, it is ready for insertion.
Step 5
Here comes the last stage of insertion into Mongo DB. But we need to have a batch insert into MongoDB. This is called a bulk insert.
Here we have to create a batch of records and when the batch is full, insert into the mongodb.
Empty the batch to enable it to give space for new records.
async addToBatch(record) {
try {
this.batch.push(record);
if (this.batch.length === this.config.batchSize) {
await this.insertToMongo(this.batch);
}
} catch (error) {
console.log(error);
}
}
const writable = new Writable({
objectMode: true,
write: async (record, encoding, next) => {
try {
if (this.dbConnection) {
await this.addToBatch(record);
next();
} else {
this.dbConnection = await this.connect();
await this.addToBatch(record);
next();
}
} catch (error) {
console.log(error);
}
},
});
What Did We Achieve?
The stream is a powerful function of NodeJs. Even if you have a laptop with 8gb ram, you can use it to parse a big CSV and stream it to Mongodb with using a very minimal usage of CPU & RAM. But, can it take multiple requests in parallel? Wait for our next write up!
Note: This testing is done on a M1 MAC with 8GB RAM.












