






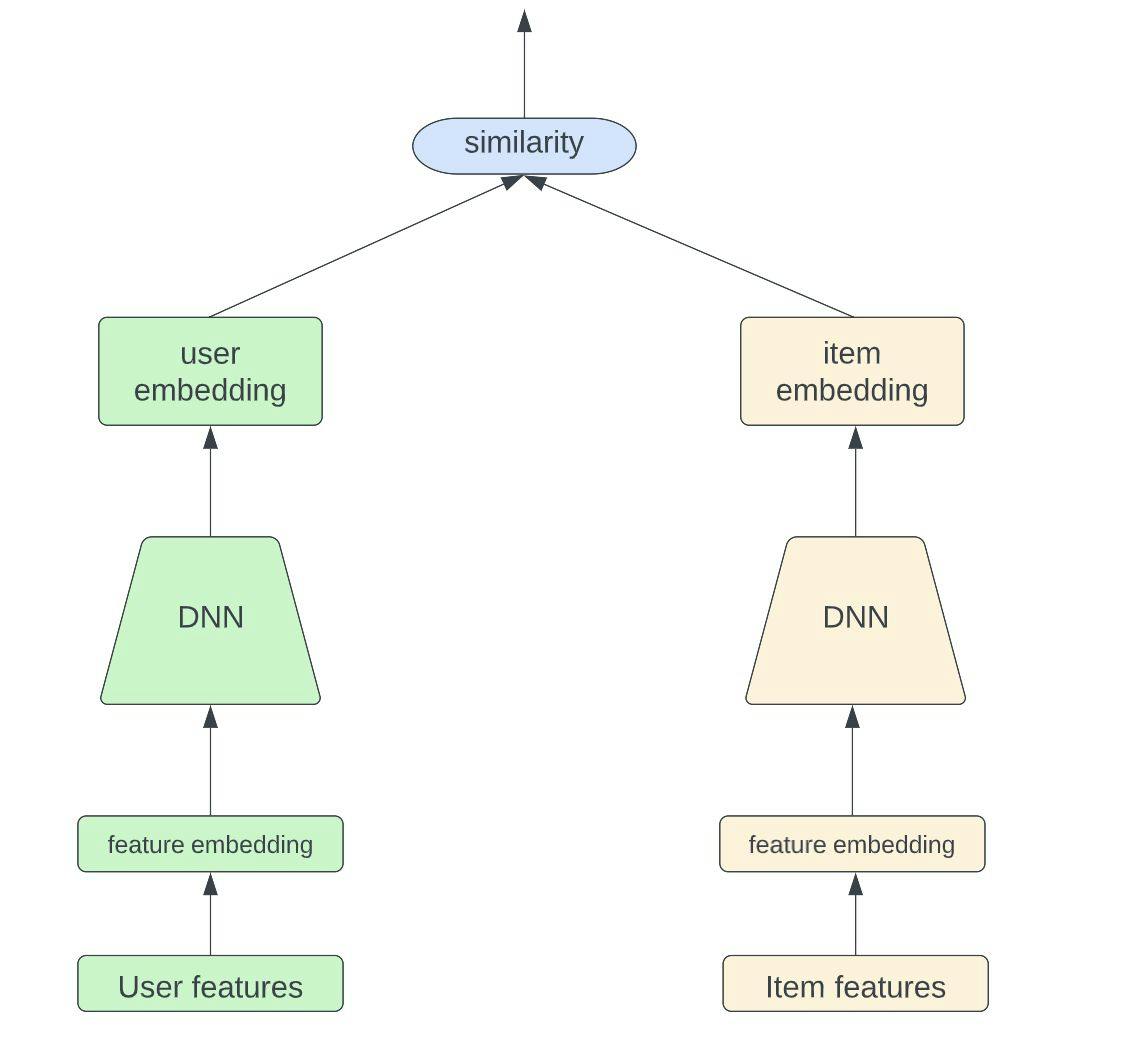

Nowadays, the Two-Tower model is widely used in the recommendation system retrieval stage. The idea is quite simple for this model architecture; it consists of two fully separated towers, one for the user and one for the item, as shown in the figure below. Through deep neural networks, the model is able to learn high-level abstract representations for both a user and an item with past user-item interactions. The output is the similarity between user embedding and item embedding, which represents how interested the user is in the given item.
To further accelerate online serving, user embeddings and item embeddings can be precomputed and stored offline. Thus, we only need to compute the similarity between user and item embeddings during online serving.

Cosine similarity and Euclidean similarity are the two most common ways to define similarity between two embeddings:
-
Cosine similarity


- Euclidean similarity


What is the exact difference between these two and how do we choose one from the other?
Theoretically, Cosine similarity is within the range [-1,1] where the higher the number, the more similar the two inputs. Because when Cosine similarity equals 1, the angle between inputs is 0 degrees, however when Cosine similarity equals -1, the angle between inputs is 180 degrees, which means that two vectors are in two completely different directions.
While for Euclidean similarity, the output is within the range [-∞,+∞]. The closer the output is to 0, the more similar inputs are.
The biggest difference is that Cosine similarity is insensitive to the absolute distance in the space, only directional difference matters. What does this mean? Let’s use one example to illustrate. Let’s say that we have user A who rates 2 movies as (4,4) and user B who rates 2 moves as (5,5). If we compute Cosine similarity and Euclidean similarity separately for these two users, it’s obvious that Cosine similarity is 1, which means that there is no difference between these two users. However, the Euclidean similarity is 1.4, which means that user A and user B are still different from each other. Thus Euclidean similarity is more strict than Cosine similarity because Euclidean similarity not only requires users to have the same taste in movies but also to have the same level of ‘like’ for every movie.


However, what if different users have different bars of rating? For example, user A gives a rating (3,3) and user B gives a rating (4,4). User A has quite a strict bar when rating and the top score for this user is 3, while user B has a very loose bar when rating, and the user gives 5 for more than 80% of the recommended movies. In this situation, the intuition is that user A likes these 2 movies a lot, however, user B really doesn’t like them. But Cosine similarity can’t reflect this. To calibrate cosine similarity, we can introduce the Pearson correlation coefficient where we use the user's average rating to calibrate every score given by the user.
In the above example, let’s assume that the average score from user A is 2 and the average score from user B is 5. To calibrate, we subtract the user's average score computed from past behaviors from each dimension. Then after the calibration, user A is (1,1) and user B is (-1,-1). Now the cosine similarity between these two users is -1, indicating that they are two very different users. There is also another way to carryout the Pearson correlation coefficient.
Instead of calibrating on the user level, we could also calibrate on the item level. Let’s say that user A gives a rating (3,3) and user B gives a rating (4,4). And we have 1000 users that gave ratings for these two movies and the average score for both movies is 3.5. If we subtract every item’s rating given by a user from the average score of the item computed from 1000 users, we have user A as (-0.5,-0.5) and user B as (0.5,0.5), which also shows that user A and user B are actually very different users since their similarity is -1.












