








This tutorial is the third one from a series of tutorials that would help you build an abstractive text summarizer using tensorflow , today we would discuss the main building block for the text summarization task , begining from RNN why we use it and not just a normal neural network , till finally reaching seq2seq model
About Series
This is a series of tutorials that would help you build an abstractive text summarizer using tensorflow using multiple approaches , you don’t need to download the data nor you need to run the code locally on your device , as data is found on google drive , (you can simply copy it to your google drive , learn more here) , and the code for this series is written in Jupyter notebooks to run on google colab can be found here
We have covered so far (code for this series can be found here)
0. Overview on the free ecosystem for deep learning
- Overview on the text summarization task and the different techniques for the task
- Data used and how it could be represented for our task
so lets get started
Quick Recap
our task is of text summarization , we call it abstractive as we teach the neural network to generate words not to merely copy words .
the data that would be used would be news and their headers , it can be found on my google drive , so you just copy it to your google drive without the need to download it (more on this)
We would represent the data using word embeddings , which is simply converting each word to a specific vector , we would create a dictionary for our words (more on this)
there are different approaches for this task , they are built over a corner stone concept , and they keep on developing and building up , they start from a network called seq2seq then they add up to be different networks that increase the overall accuracy , the code for these different approaches can be found here
Today we would discuss what is seq2seq and why it is used in the first place , so lets start !!


This tutorial has been based by the amazing work of Andrew NG , his course on RNN has been truly useful , i recommend you to see it
1- Why we use complex network structure not a simple neural network
this is truly an important question to be asked , in natural language tasks , it is important for the network to understand the word itself , not to link the word to a specific location , this is what we call (sharing features accross different parts of text)


normal neural network inefficient for nlp
assume our task was identifying named entities within a text , as we can see in the previous gif , a normal neural network won’t be able to identify the name Harry if it is found in different parts of the text
so this is why we would need a new network for this task , this network is called (Recurrent Neural Network) RNN


RNN for nlp
here using a RNN , the network was able to identify the name Harry if found in different parts of text .
RNN is the base of seq2seq , as we would see
2- What is RNN (Recurrent Neural Network)
Recurrent Neural Network is a type of neural network that takes time into consideration , each box (box with circles as seen in the gif)


RNN network
is the actually our network , and we use it multiple times , each time , is a step in time , as each time step we would feed it with a word from our sentence , it also takes the output from the previous time step ,
so to recap , RNN is
- takes time into consideration (runs multiple times in time)
- takes output from previous step


RNN ex 1
here as we see , it takes the input from previous steps


RNN ex 2
and it can understand named entity recognition independent to the location , which is our needed behavior
3- RNN Feed-forward steps
like any other neural network , we would need a feed-forward step


Here we would have
- X vectors (blue vector) (inputs , which would be words from our sentence)
- Y vectors (green vector)(outputs , would would be the words exported from each time step
- A vectors (red vectors) (activaations from each time step)
there are also 3 types of weights
- Wax vectors (blue) (that would be multiplied by input) , same for all time steps
- Wya vectors (green) ,(that would be multiplied by output) ,same for all time steps
- Waa vectors (red) (that would be multiplied by activations) , same for all time steps


the 2 main functions that govern our work are


which calculates the next activation parameter using the previous activation parameter and previous input with a bias , here we use activation function g which is mostly either tanh or relu


a
the other function is for calculating the output from each time step , here we use the activation parameter , with the bias , with also using a g activation function either tanh or relu
then we would need to calculate loss to be used for back propagation
the main used function is (training Loss)


here we use the generated output yhat with the given output y


then we simply add them all to get the total loss


now after that we have talked about training stage , we need to talk about running our network
4- RNN Running stage
now after training our network , we would need to run it ,this stage is also called sampling (here we would sample random words according to trained language model, for illustration of how rnn runs)


as we see , the inputs from a time step is forwarded to the other time step till we reach the final output , we would need a tokken <eot> , end of text then we would stop our running.


Here we would calculate the cost of this run
the main function for this is


were we would use both the generated output and the original output
then we simply add them up to get the total output




In All of the above we only talked about one type of RNN , which is many-to-many architectures with same lengths for both input and output , this won’t be our case
As for text summarization , we need to have the ability to have different lengths for input and for output , for this we would finally talk about Seq2Seq
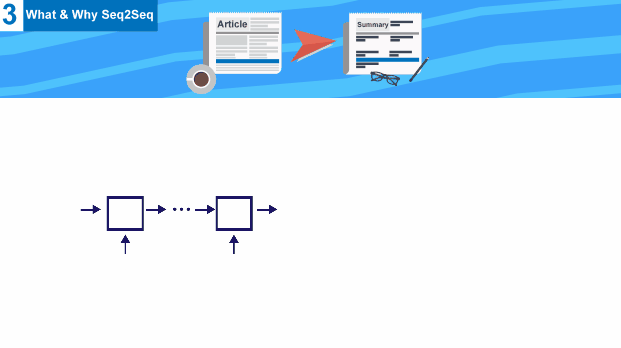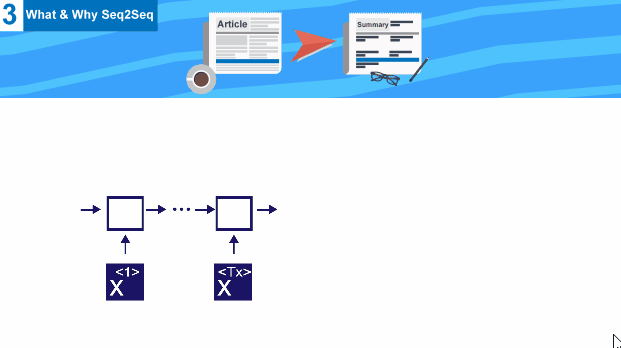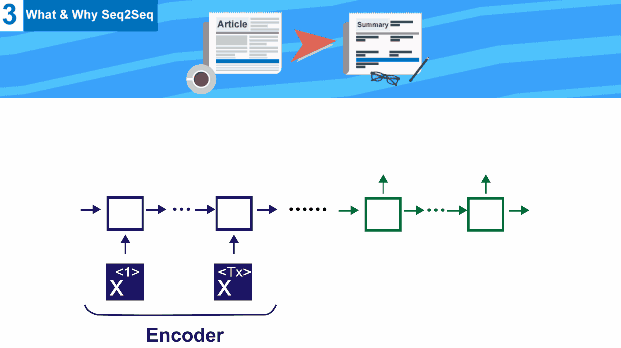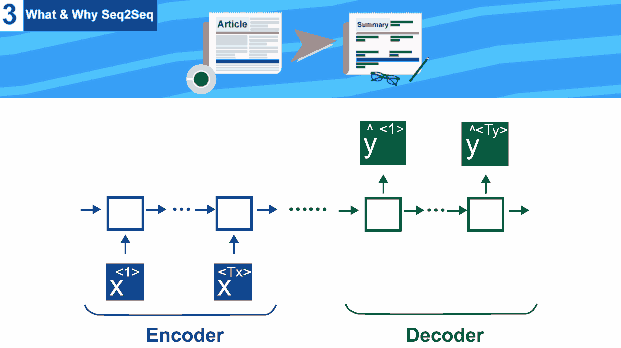
5- We Finally Reached Seq2Seq
we need a special network that takes input of length (Tx) , and generates another output of another different length (Ty) , this architecture is called Encoder Decoder .
Both Encoder Decoder here are RNN network , but encoder uses input , and generates an output state that is then used as input to decoder stage


This architecture is used for both tasks
- Machine translation
- Text Summarization
Recap
Today we have discussed
- why we use RNN for text summarization and not a simple neural network ,
- what is RNN (feed forward , running)
- Then we finally reached seq2seq architecture using encoder decoder
But we can even have a better architecture for text summarization , we can add modifications to RNN to increase its efficiency , and to solve some of its problems , we can also add attention mechanism which proved extremely beneficial for our task , we could also use beam search
All of these concepts would be discussed in the coming tutorial If GOD wills it .
I truly hope you have enjoyed reading this tutorial , and i hope i have made these concepts clear , all the code for this series of tutorials are found here , you can simply use google colab to run it , please review the tutorial and tell me what do you think about it , hope to see you again











