










Table of Links
- Abstract and Introduction
- Related Work
- Problem Definition
- Method
- Experiments
- Conclusion and References
A. Appendix
A.1. Full Prompts and A.2 ICPL Details
A.6 Human-in-the-Loop Preference
A.6 HUMAN-IN-THE-LOOP PREFERENCE
A.6.1 ISAACGYM TASKS
We evaluate human-in-the-loop preference experiments on tasks in IsaacGym, including Quadcopter, Humanoid, Ant, ShadowHand, and AllegroHand. In these experiments, volunteers only provided feedback by comparing videos showcasing the final policies derived from each reward function.
In the Quadcopter task, humans evaluate performance by observing whether the quadcopter moves quickly and efficiently, and whether it stabilizes in the final position. For the Humanoid and Ant tasks, where the task description is "make the ant/humanoid run as fast as possible," humans estimate speed by comparing the time taken to cover the same distance and assessing the movement posture. However, due to the variability in movement postures and directions, speed is often estimated inaccurately. In the ShadowHand and AllegroHand tasks, where the goal is “to make the hand spin the object to a target orientation,” The target orientation is displayed nearby the robot hand so that human can estimate difference between the current orientation and the target orientation. Besides, since the target orientation regenerates upon being reached, the frequency of target orientation changes can also help to evaluate performance.
Due to the lack of precise environmental data, volunteers cannot make absolutely accurate judgments during the experiments. For instance, in the Humanoid task, robots may move in varying directions, which can introduce biases in volunteers’ assessments of speed. However, volunteers are still able to filter out extremely poor results and select videos with relatively better performance. In most cases, the selected results closely align with those derived from proxy human preferences, enabling effective improvements in task performance.
Below is a specific case from the Humanoid task that illustrates the potential errors humans may make during evaluation and the learning process of the reward function under this assumption. The reward task scores (RTS) chosen by the volunteer across five iterations are 4.521, 6.069, 6.814, 6.363, 6.983.
n the first iteration, the ground-truth task scores of each policy were 0.593, 2.744, 4.520, 0.192, 2.517, 5.937, note that the volunteer was unaware of these scores. Initially, Initially, the volunteer reviewed all the videos and selected the one with the worst behavior. The humanoid in video 0 and video 3 exhibited similar spinning behavior and the volunteer chose video 3 as the worst video. Subsequently, the volunteer evaluated the remaining videos based on the humanoids’ running speed. The humanoids in video 1 and video 4 appeared to run slightly slower, while those in video 2 and video 5 ran faster. Ultimately, the volunteer chose video 2 as the most preferred, demonstrating that human decision-making may lead to suboptimal choices.
Thus, the reward function selected in iteration 1 consists of several key components: velocity reward, upright reward, force penalty, unnatural pose penalty, and action penalty. These components not only promote faster training, which is the primary objective, but also encourage the maintenance of an upright pose. Additionally, the function penalizes excessive force usage, extreme joint angles, and large action values to foster smoother and more controlled movements.
In subsequent iterations, the volunteer correctly identified the best and worst videos. Adjustments were made to the weights of each component, and specific temperature values were introduced for each. These modifications resulted in a more balanced reward structure, ensuring that critical aspects exert a stronger influence, thereby allowing for greater control over the learning dynamics and improving the agent’s performance in achieving the task. Even in Iteration 4, the volunteer did not select the reward function with the highest RTS (6.813) but instead opted for the second-highest reward function (RTS = 6.363). Nevertheless, the generated reward function exhibited consistent improvement during these iterations.
Here we show the full reward function during the process.














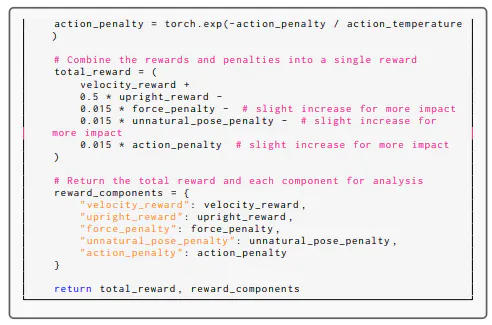







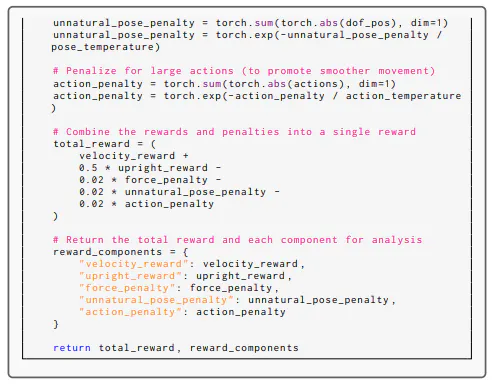
A.6.2 HUMANOIDJUMP TASK
In our study, we introduced a novel task: HumanoidJump, with the task description being “to make humanoid jump like a real human.” The prompt of environment context in this task is shown in Prompt 5.



Reward functions. We show the reward functions in a trial that successfully evolved a human-like jump: bending both legs to jump. Initially, the reward function focused on encouraging vertical movement while penalizing horizontal displacement, high contact force usage, and improper joint movements. Over time, the scaling factors for the rewards and penalties were gradually adjusted by changing the temperature parameters in the exponential scaling. These adjustments aimed to enhance the model’s sensitivity to different movement behaviors. For example, the vertical movement reward’s temperature was reduced, leading to more precise rewards for positive vertical movements. Similarly, the horizontal displacement penalty was fine-tuned by modifying its temperature across iterations, either decreasing or increasing the penalty’s impact on lateral movements. The contact force penalty evolved by decreasing its temperature to penalize excessive force usage more strongly, especially in the later iterations, making the task more sensitive to leg contact forces. Finally, the joint usage reward was refined by adjusting the temperature to either encourage or discourage certain joint behaviors, with more focus on leg extension and contraction patterns. Overall, the changes primarily revolved around adjusting the sensitivity of different components, refining the balance between rewards and penalties to better align the humanoid’s behavior with the desired jumping performance.












Authors:
(1) Chao Yu, Tsinghua University;
(2) Hong Lu, Tsinghua University;
(3) Jiaxuan Gao, Tsinghua University;
(4) Qixin Tan, Tsinghua University;
(5) Xinting Yang, Tsinghua University;
(6) Yu Wang, with equal advising from Tsinghua University;
(7) Yi Wu, with equal advising from Tsinghua University and the Shanghai Qi Zhi Institute;
(8) Eugene Vinitsky, with equal advising from New York University ([email protected]).
This paper is available on arxiv under CC 4.0 license.











