











Consider the following problem:
Due to neglect, your home is in serious need of repair. Naturally, you go out and get quotes on remodeling and repairing what needs to be done. Let’s assume the four quotes you received look like this:


This would seem pretty reasonable, all things considered. And we might naturally just go with Susan, since she’s giving us the best overall price. However, another solution might be to break down what we need done into individual items. Then we could get prices from our contractors per repair item. This would be more beneficial in two ways:
- We would save time, since all contractors could be working on each repair item concurrently, and accomplish the overall project much more quickly.
- We could also probably get a better price by hiring contractors based on what their lowest item cost is.
Take a look at the following chart, of what these individual prices might look like:


There two things we need to keep in mind as we do this:
- We probably want to only hire one contractor for one job, to maximize time.
- This means that we can’t use the same contractor twice, and naturally, we won’t have two contractors work on the same job at any point.
For example, we might choose the following:


By using this strategy, we would minimize our time, by spreading the work over 4 contractors, but we also minimize our cost, by hiring contractors per repair item. Despite how simple this may appear, it could get quite difficult to calculate if we had a much larger pool of contractors to choose from, or had many more repairs to consider. Luckily, there is a great formula for figuring this type of problem out. I’m going to be using something called the Hungarian Method. The Hungarian method is a combinatorial optimization algorithm that solves the assignment problem in polynomial time and which anticipated later primal-dual methods. It was developed and published in 1955 by Harold Kuhn, who gave the name “Hungarian method” because the algorithm was largely based on the earlier works of two Hungarian mathematicians: Dénes Kőnig and Jenő Egerváry. After solving this problem using pseudo code, I’ll look at how we can use Python to create a function to solve it using the same method. The advantage to using Python, is that we can create a dynamic function that would solve our equation, no matter the grid size. This could be especially handy if, as in our example above, we decided to add more repairs, or get more contractor quotes. Hopefully, as we go through this, other applications of this strategy will become apparent.
The Hungarian Method basically has three steps:
1. Find the lowest value in each column.
- Convert the lowest value in each column to a zero.
- Subtract the lowest value in each column from the other values in the same column.
2. Find the lowest value in each row.
- If the lowest value in the row isn’t a zero already, then convert it to a zero.
- Again subtract the lowest value in each row from the remaining values in each row.
3. Select the rows/columns (as we did in the example above) which are only zeros.
Here’s the reasoning behind this method: In each column, we have our individual jobs. The lowest value in each column represents the minimum price we would have to pay, regardless. So by setting that value to zero, we can then subtract that value from the other column values. The rows represent the price we would have to pay the contractors. The minimum row value represents the minimum price we will have to pay each contractor, and similarly, setting it to zero allows us to subtract it from the other values in the row. Let’s take a look at how this method could be applied to our current problem:
STEP 1: Set the lowest column values to 0.


Here, we can see that each column has a zero. However, only rows 1, 3 and 4 have zeros, and row 4 has 2 zeros. Now, we will subtract the lowest value, which we’ve converted to zero, from the remaining column values. Here, I’ve updated column 1, subtracting the lowest value, 70, from the remaining column values, leaving us with 15, 30, and 80:
STEP 1: subtract the lowest column value from the other column values.

Now, we’ll move through the remaining columns and update them as well:
STEP 1: subtract the lowest column value from the other column values.


Now, we’ll notice that each column contains a zero. However, only rows 1, 3 and 4 have a zero, with row for having 2 of them. From here, we move on to step 2. We cycle through the rows now, and convert the lowest value in each row to a zero, only if the row doesn’t currently have a zero.
STEP 2: Identify the lowest row values in rows that do not contain a 0 value.

And now, repeating the previous step, we’ll subtract that value from the remaining values in the row:
STEP 2: Subtract the lowest row value from the other values in the row.

STEP 3: Identify and allocate the lowest jobs to contractors.
After completing step 2 we can see that each row and each column have a zero, which leaves us with the challenge of allocating the appropriate jobs to each contractor. From here, we’ll select only row or column values of zero. In row 4, we could select Susan for either Painting or Flooring. We could select either Diego or Susan for flooring. If we are allocating the appropriate column and row values manually, without the use of Python, or another program, we might simply first choose the values where we have no other choice. Here, column 2 and column 4 give us only one choice, so we can select those first. In deciding between Flooring or Painting for Susan, we can see that if we select Flooring for Susan, we eliminate row 4, which leaves us with no alternative zero for column 1. With that, the only possible solution is Diego for Flooring and Susan for Painting, allowing us to pick a zero for each row and column.
Now, this is originally what we had decided anyway, and with only a 4x4 matrix, it wasn’t that difficult. But imagine if our matrix were much larger. Trying to allocate jobs in this way, in order to minimize both time and expense would be incredibly difficult. This method allows make those calculations much more easily.
Now, let’s look at how we might create a program that would solve this problem for us. My goal here is to not simply write a program to solve this exact problem, but to write code that will solve this problem for any size matrix, allowing me to re-use the code for multiple applications. You can see how doing this could be powerfully useful in a variety of settings.
To start off, I’m going to put our matrix in an array, as that will be a little easier to work with. Then, if I ever need to re-use the code, I can just swipe out the array for a new one.
arr = [100, 130, 115, 55, 150, 75, 35, 110, 85, 50, 120, 120, 70, 150, 25, 90]
Now, it’s good to have a clear idea of what we want to do next. For me, it makes sense to keep track of several things. I have this list of numbers, but keeping in mind how the Hungarian method works, we want to know several things about each number, like what it’s current value is, what it’s modified value is, what row the number is on and what column the number is on. I probably also want to know the index value the value occurs within the list. For me, turning my list of numbers into a list of python dictionaries makes sense. A python dictionary looks a lot like a JavaScript object. Here’s basically what I want to do:

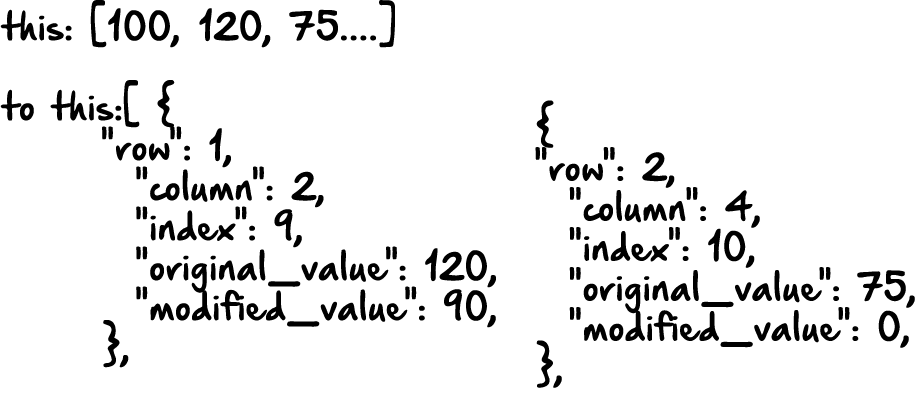
That way, after turning each value into a dictionary, I can then get more information from each number as I cycle through it. Having the modified and original value also helps, because while the modified value will help us allocate which values to use in the end, the original value is the actual price or cost, which we’ll need to refer to in the end.
To start off, I’m going to set some variables that will help me convert my list of numbers to a list of dictionaries:
arr2 = []numberOfRows = 4numberOfColumns = 4column = 0
arr2
— As I loop through my original list, arr, I’ll push the modified dictionaries into my dictionaries into my new list, arr2.
number of Rows & number of Columns
The great thing about these variables is, they’ll help us keep track of where we are in our matrix. Also, it will help us keep our code re-usable. In the future, if we change this matrix, or start a new one, we can just update the list, and the number of rows and columns, and Python will re-calculate the rest. It leaves us very little to change in the future.
column
This variable will give us a starting point to loop through our list. We can increment it as we go, and update our dictionaries accordingly.
Now, we’ll start our for loop, and give it a condition:
for idx, val in enumerate(arr):row = len(arr2)/numberOfRows+1column = column + 1if column > numberOfColumns:column = 1
for idx, val in enumerate(arr):
The enumerate method in Python will allow us to see the value and index number in each list item. This will help us get the index value to add to our object, as well as the original value.
row = len(arr2)/numberOfRows+1
This is how we’ll keep track of which row value we add to the current dictionary. For example, if we’re on the first item in our for loop, we haven’t added anything to arr2 yet. So the length of arr2 will be 0. We know, in this exercise, the numberOfRows is 4, so 0/4+1 = 1. Thus, our row would be 1. But if we are on the very last item, we’ve already added a lot to arr2. The length of arr2 at that point would be 15. So 15/4 = 3 + 1 = 4. The row, then would be 4.
column = column + 1
Here, since our original value is 0, we’re just adding 1, since there isn’t a column 0. After each list item, our column will increment by one.
if column > numberOfColumns:
column = 1
Our condition here helps us keep track of the columns. For example, we can’t continuously increment the columns, as the maximum number of columns is 4, in this case. So, since we are incrementing our columns by one, if, at the beginning of each item in the loop, if the current column number is greater than 4, it will reset back to 1, and begin incrementing again until we get to 5 again, and will reset.
Now, we’ll create our dictionary:
idx = {"row": row,"column": column,"index": idx,"original_value": val,"modified_value": val,}arr2.append(idx)
Here, we’re just using the values we’ve already set, and creating key value pairs to allow us to access these values later. Here’s how that entire block of code looks:
for idx, val in enumerate(arr):row = len(arr2)/numberOfRows+1column = column + 1if column > numberOfColumns:column = 1idx = {"row": row,"column": column,"index": idx,"original_value": val,"modified_value": val,}arr2.append(idx)
Now, I’m going to sort my list by the original value key in our list. Later, I’ll want to access the lowest value in each column, and each row, and if I have them sorted by the lowest original values, this will be much easier. Here’s how we’ll do that:
newlist = sorted(arr2, key=lambda k: k['original_value'])
The variable I’m using now is newlist. From here on out, I won’t need arr or arr2, but I’ll interact instead only with this list, newlist. Here’s what my output is, for reference:
{'column': 3, 'index': 14, 'original_value': 25, 'modified_value': 25, 'row': 4}{'column': 3, 'index': 6, 'original_value': 35, 'modified_value': 35, 'row': 2}{'column': 2, 'index': 9, 'original_value': 50, 'modified_value': 50, 'row': 3}{'column': 4, 'index': 3, 'original_value': 55, 'modified_value': 55, 'row': 1}{'column': 1, 'index': 12, 'original_value': 70, 'modified_value': 70, 'row': 4}{'column': 2, 'index': 5, 'original_value': 75, 'modified_value': 75, 'row': 2}{'column': 1, 'index': 8, 'original_value': 85, 'modified_value': 85, 'row': 3}{'column': 4, 'index': 15, 'original_value': 90, 'modified_value': 90, 'row': 4}{'column': 1, 'index': 0, 'original_value': 100, 'modified_value': 100, 'row': 1}{'column': 4, 'index': 7, 'original_value': 110, 'modified_value': 110, 'row': 2}{'column': 3, 'index': 2, 'original_value': 115, 'modified_value': 115, 'row': 1}{'column': 3, 'index': 10, 'original_value': 120, 'modified_value': 120, 'row': 3}{'column': 4, 'index': 11, 'original_value': 120, 'modified_value': 120, 'row': 3}{'column': 2, 'index': 1, 'original_value': 130, 'modified_value': 130, 'row': 1}{'column': 1, 'index': 4, 'original_value': 150, 'modified_value': 150, 'row': 2}{'column': 2, 'index': 13, 'original_value': 150, 'modified_value': 150, 'row': 4}
[Finished in 0.089s]
It’s a good idea, as we’re moving along to print the results of each list, to make sure we have the data we expect.
Next, I’m going to create to blank lists:
columnsTested = []columnAndValue = []
My idea here is to loop through newlist. Since it’s organized by original value, then I’ll append the lowest values in each column into columnAndValue, and push only the column value into columnsTested. That way, I can make a condition, that will check to see if x column is already in columnsTested. If it is, I’ll skip over it.
for i in newlist:testObj = {"column": i['column'],"minVal": i['original_value']}
To start my list, I’m creating an object of the column and original value, and later I’ll test this object against my newlist list. I can say, at that point that if the column in this testObj matches the column of my newlist item, I’ll subtract the minVal in testObj from the modified value in newlist. Just to let you know what my plan is for having this.
Next, I’ll add my condition:
if i['column'] not in columnsTested:columnAndValue.append(testObj)columnsTested.append(i['column'])
Now, the first 6 or 7 items in newlist, might be in different columns, but since it’s organized from lowest value, it might grab the item and index 3, which is in column 2. Then the value at index 4 might also be in column 2. But it won’t get the second value, since a value from column 2 already exists in columnsTested. And the first value it appended to columnAndValue is lower than the second one.
Here’s how this block of code looks all together:
columnsTested = []columnAndValue = []for i in newlist:testObj = {"column": i['column'],"minVal": i['original_value']}if i['column'] not in columnsTested:columnAndValue.append(testObj)columnsTested.append(i['column'])
Now, I’m going to do a nested for loop to test the dictionaries in newlist against the dictionaries in columnAndValue. If the columns in each match, I’ll subract the minVal from columnAndValue, from the modifiedValue in newlist. At this point, modifiedValue and originalValue are the same, but this will give us the difference we want in the two values.
for i in newlist:for j in columnAndValue:if i['column'] == j['column']:i['modified_value'] = i['modified_value'] - j['minVal']
Pretty straight forward right? Again, it’s a good idea to check, and make sure we have the data we expect by printing the contents of newlist. Our output likely looks something like this:
{'column': 3, 'index': 14, 'original_value': 25, 'modified_value': 0, 'row': 4}{'column': 3, 'index': 6, 'original_value': 35, 'modified_value': 10, 'row': 2}{'column': 2, 'index': 9, 'original_value': 50, 'modified_value': 0, 'row': 3}{'column': 4, 'index': 3, 'original_value': 55, 'modified_value': 0, 'row': 1}{'column': 1, 'index': 12, 'original_value': 70, 'modified_value': 0, 'row': 4}{'column': 2, 'index': 5, 'original_value': 75, 'modified_value': 25, 'row': 2}{'column': 1, 'index': 8, 'original_value': 85, 'modified_value': 15, 'row': 3}{'column': 4, 'index': 15, 'original_value': 90, 'modified_value': 35, 'row': 4}{'column': 1, 'index': 0, 'original_value': 100, 'modified_value': 30, 'row': 1}{'column': 4, 'index': 7, 'original_value': 110, 'modified_value': 55, 'row': 2}{'column': 3, 'index': 2, 'original_value': 115, 'modified_value': 90, 'row': 1}{'column': 3, 'index': 10, 'original_value': 120, 'modified_value': 95, 'row': 3}{'column': 4, 'index': 11, 'original_value': 120, 'modified_value': 65, 'row': 3}{'column': 2, 'index': 1, 'original_value': 130, 'modified_value': 80, 'row': 1}{'column': 1, 'index': 4, 'original_value': 150, 'modified_value': 80, 'row': 2}{'column': 2, 'index': 13, 'original_value': 150, 'modified_value': 100, 'row': 4}
[Finished in 0.107s]
Now, we’ll repeat the last two steps, but target the rows instead of the columns, but all the building blocks of that code will be exactly the same:
rowsTested = []rowAndValue = []for i in newlist:testObj = {"row": i["row"],"minVal": i["modified_value"],"modified": i["modified_value"]}if i['row'] not in rowsTested:rowAndValue.append(testObj)rowsTested.append(i['row'])
for i in newlist:for j in rowAndValue:if i['row'] == j['row'] and j['modified'] > 0:i['modified_value'] = i['modified_value'] - j['minVal']
Voila! Now, if we print newlist, we can see that the four values with 0’s are at the top of our list, and we can easily select the ones that don’t occur in duplicate rows or columns. Our output should look like this:
{'column': 3, 'index': 14, 'original_value': 25, 'modified_value': 0, 'row': 4}{'column': 3, 'index': 6, 'original_value': 35, 'modified_value': 0, 'row': 2}{'column': 2, 'index': 9, 'original_value': 50, 'modified_value': 0, 'row': 3}{'column': 4, 'index': 3, 'original_value': 55, 'modified_value': 0, 'row': 1}{'column': 1, 'index': 12, 'original_value': 70, 'modified_value': 0, 'row': 4}{'column': 2, 'index': 5, 'original_value': 75, 'modified_value': 15, 'row': 2}{'column': 1, 'index': 8, 'original_value': 85, 'modified_value': 15, 'row': 3}{'column': 4, 'index': 15, 'original_value': 90, 'modified_value': 35, 'row': 4}{'column': 1, 'index': 0, 'original_value': 100, 'modified_value': 30, 'row': 1}{'column': 4, 'index': 7, 'original_value': 110, 'modified_value': 45, 'row': 2}{'column': 3, 'index': 2, 'original_value': 115, 'modified_value': 90, 'row': 1}{'column': 3, 'index': 10, 'original_value': 120, 'modified_value': 95, 'row': 3}{'column': 4, 'index': 11, 'original_value': 120, 'modified_value': 65, 'row': 3}{'column': 2, 'index': 1, 'original_value': 130, 'modified_value': 80, 'row': 1}{'column': 1, 'index': 4, 'original_value': 150, 'modified_value': 70, 'row': 2}{'column': 2, 'index': 13, 'original_value': 150, 'modified_value': 100, 'row': 4}
[Finished in 0.082s]
And the great thing, is although this takes some time to set up, we can now evaluate any matrices we want, for any similar problems.












