









Article is about maps internal structure, hashes and performance. How data is actually stored inside.
Basics overview
Maps (aka associative arrays) is basically key-value storage with really fast lookup. Really basic example:
m := make(map[int]string)
m[42] = "Hello!"
value, exist := m[42]
// value = 42
// exist = trueAlso it is possible to use maps as sets:
set := make(map[int]struct{})
_, exist := set[42]
if exist {
fmt.Println("42 is in the set")
}struct{} is used because of the zero size. Check out small sample here https://play.golang.org/p/Ndn8UqxWYC3
Go deeper
Under the hood maps is a hash table (aka hashmap). Sometimes search tree is also used to organize maps in some other languages and cases.
Main idea of hash map is to have near-constant O(1) lookup time. Formally lookup time is O(n), in case if hash function gives n collisions, which is almost impossible in real situations.
Hash and collisions
By definition hash is a function that transforms any value to fixed-size value. In case of Go, it takes any number of bits and transform it to 64.
Internal hash implementation could be found here:
https://github.com/golang/go/blob/dev.boringcrypto.go1.13/src/runtime/hash64.goWhen hash function produces same results for different values, this is a collision. Most secure hash functions don't have known collisions.
Brief hashmap theory
To store key-value pairs, the most naive approach is to create a list and traverse all pairs each lookup with O(n) complexity. Not good.
More advanced approach is to create balanced search tree and achieve stable O(log(n)) lookup efficiency, which is good for many cases.
Ok, but what if we want to do it even faster? Fastest possible lookup is O(1), we have this speed with arrays. But we do not have keys suitable for array. Solution is to hash keys, and use hashes or part of hashes.
Lets create BN buckets. Each bucket is a simple list. Hash function will transform keys like that: hash(key)->{1..BN}
Adding new key-value to hashmap is inserting it in hash(key) bucket.


Lookup time
Let PN be the number of key-value pairs in hashmap.
If we have PN ≤ BN and zero collisions, this is ideal case, lookup time is O(1).
If PN > BN then at least one bucket will have at least 2 values, so lookup could take 2 steps - locate bucket, and simply iterate through bucket list, till key-value pair is found.
Average number of items in buckets is called load factor. Load factor divided by 2 will be the average lookup time, and collisions rate will define dispersion of it. Formally the complexity is still O(n), but in practice collisions is rare enough and keys will spread to buckets almost evenly.
Hashmap Go implementation
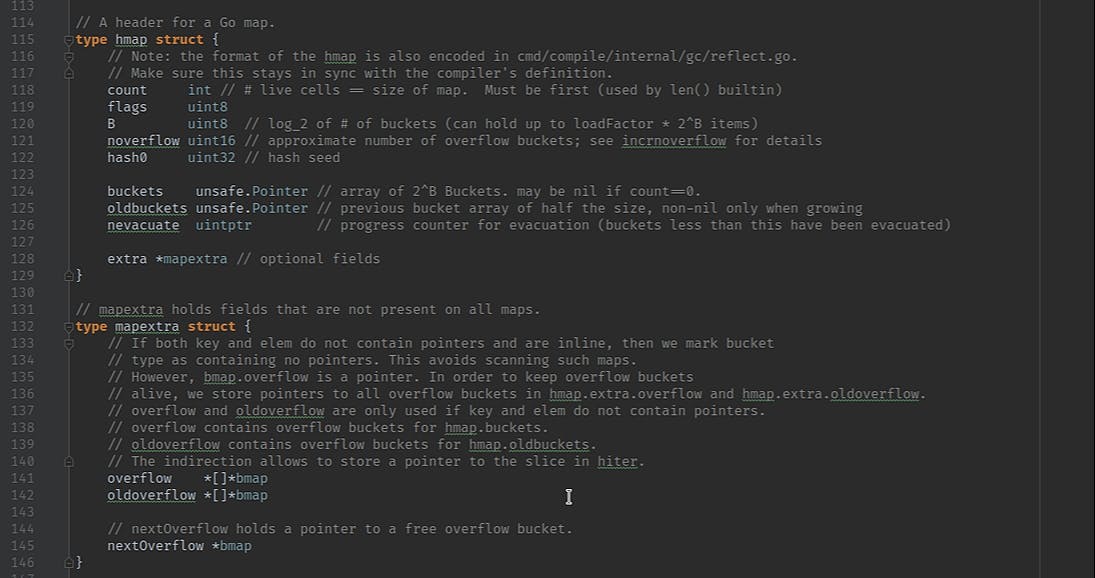
Source code of map is here, and it’s more or less understandable https://github.com/golang/go/blob/master/src/runtime/map.go
Maps is a pointer to hmap structure. It is mutable! If you need a new one, you shall create a copy manually.
Another important thing, is that hash is based on random seed, so each map is built differently.
h.hash0 = fastrand()I think, the idea behind this randomization is to avoid potential vulnerabilities when malicious actor will flood hashmap with collisions and to prevent any attempts to rely on map iteration order. Map is iterable, but not ordered. Even every new iterator of the same map is randomized.
m := make(map[int]int)
for j := 0; j < 10; j++ {
m[j] = j * 2
}
for k, v := range m {
fmt.Printf("%d*2=%d ", k, v)
}
fmt.Printf("\n - - -\n")
for k, v := range m {
fmt.Printf("%d*2=%d ", k, v)
}
// Second loop of the same map would produce different order of elementsThis code will print results in random order. Check out more code here https://play.golang.org/p/OzEhs4nr_30
Default map size is 1 bucket, bucket size is 8 elements. IRL hash functions usually return 32, 64, 256… bits. So we will take only part of this bits to use as a bucket number. So with 8 buckets, we need only log2(8)=3 low-order bits, (8=2³, for 16 log2(16)=4, 16=2⁴ and so on.
bucket := hash & bucketMask(h.B)where h.B is log_2 of BN. Same as 2^h.B = BN
bucketMask(h.B) is a simple h.B bits mask, like 00…011…1, where number of 1 bits is h.B
Map grow
If map grows beyond certain limits, Go will double the number of buckets. Each time number of bucket is increased, it is required to rehash all map content. Under the hood, Go uses sophisticated map grow mechanism for optimal performance. For some time Go keeps old buckets along with new ones, to avoid load peaks and assure that already started iterators would finish safely.
Conditions of map grow from source code:
overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)First is a load factor check. Average load of a buckets that triggers growth is 6.5 or more. This value is hard-coded and based on Go team benchmarks.
Second check is about overflow buckets count. “Too many” means (approximately) as many overflow buckets as regular buckets. Single bucket hard-coded capacity is 8 elements. When limit is reached, new overflow bucket is chained to full bucket.
Interesting thing, that grow trigger is a bit randomized for large maps with ≥2¹⁶ buckets.
func (h *hmap) incrnoverflow() {
// We trigger same-size map growth if there are
// as many overflow buckets as buckets.
// We need to be able to count to 1<<h.B.
if h.B < 16 {
h.noverflow++
return
}
// Increment with probability 1/(1<<(h.B-15)).
// When we reach 1<<15 - 1, we will have approximately
// as many overflow buckets as buckets.
mask := uint32(1)<<(h.B-15) - 1
// Example: if h.B == 18, then mask == 7,
// and fastrand & 7 == 0 with probability 1/8.
if fastrand()&mask == 0 {
h.noverflow++
}
}Hack map with Unsafe
To gather more information, we need to access map internal values, like h.B and buckets content. This will work as is only if internal structure of hmap wont change, this tested for 1.13.8
We need to convert map builtin to hmap struct, in order to gather map internal data. The trick is to use unsafe.Pointer and empty interface. First we convert map pointer &m to unsafe.Pointer, then convert to emptyInterface struct, this struct matches actual empty interface internal struct. From that struct we could acquire type of map as and hmap struct.
type emptyInterface struct {
_type unsafe.Pointer
value unsafe.Pointer
}
func mapTypeAndValue(m interface{}) (*maptype, *hmap) {
ei := (*emptyInterface)(unsafe.Pointer(&m))
return (*maptype)(ei._type), (*hmap)(ei.value)
}And use it like this:
m := make(map[int]int)
t, hm := mapTypeAndValue(m)We need to copy maptype, hmap some constants, structs and functions from Go sources src/runtime/map.go, sources version should match compiler version.
Now we can trace, how map structure buckets number changes with adding new elements.
m := make(map[int]int)
_, hm := mapTypeAndValue(m)
fmt.Printf("Elements | h.B | Buckets\n\n")
var prevB uint8
for i := 0; i < 100000000; i++ {
m[i] = i * 3
if hm.B != prevB {
fmt.Printf("%8d | %3d | %8d\n", hm.count, hm.B, 1<<hm.B)
prevB = hm.B
}
}Code snippet - https://play.golang.org/p/NaoC8fkmy9x
Elements | h.B | Buckets
9 | 1 | 2
14 | 2 | 4
27 | 3 | 8
53 | 4 | 16
105 | 5 | 32
209 | 6 | 64
417 | 7 | 128
833 | 8 | 256
1665 | 9 | 512
3329 | 10 | 1024
6657 | 11 | 2048
13313 | 12 | 4096
26625 | 13 | 8192
53249 | 14 | 16384
106497 | 15 | 32768
212993 | 16 | 65536
425985 | 17 | 131072
851969 | 18 | 262144
1703937 | 19 | 524288
3407873 | 20 | 1048576
6815745 | 21 | 2097152
13631489 | 22 | 4194304
27262977 | 23 | 8388608
54525953 | 24 | 16777216Now let's see how buckets are filled! I will ignore overflow buckets content, for relative simplicity. Hmap struct contains pointer buckets to where cells stored in memory. Next we traverse trough memory to acquire all values inside map buckets. Here we need keysize and bucketsize from maptype to calculate right offsets for buckets and cells.
func showSpread(m interface{}) {
// dataOffset is where the cell data begins in a bmap
const dataOffset = unsafe.Offsetof(struct {
tophash [bucketCnt]uint8
cells int64
}{}.cells)
t, h := mapTypeAndValue(m)
fmt.Printf("Overflow buckets: %d", h.noverflow)
numBuckets := 1 << h.B
for r := 0; r < numBuckets*bucketCnt; r++ {
bucketIndex := r / bucketCnt
cellIndex := r % bucketCnt
if cellIndex == 0 {
fmt.Printf("\nBucket %3d:", bucketIndex)
}
// lookup cell
b := (*bmap)(add(h.buckets, uintptr(bucketIndex)*uintptr(t.bucketsize)))
if b.tophash[cellIndex] == 0 {
// cell is empty
continue
}
k := add(unsafe.Pointer(b), dataOffset+uintptr(cellIndex)*uintptr(t.keysize))
ei := emptyInterface{
_type: unsafe.Pointer(t.key),
value: k,
}
key := *(*interface{})(unsafe.Pointer(&ei))
fmt.Printf(" %3d", key.(int))
}
fmt.Printf("\n\n")
}
func main() {
m := make(map[int]int)
for i := 0; i < 50; i++ {
m[i] = i * 3
}
showSpread(m)
m = make(map[int]int)
for i := 0; i < 8; i++ {
m[i] = i * 3
}
showSpread(m)
}Due to randomized nature of map hash generation, each run result for map bigger than 8 values would be different. Notice that very small map will work just like list! Result example:
Overflow buckets: 3
Bucket 0: 26 28
Bucket 1: 0 2 7 8 13 22 31 38
Bucket 2: 6 9 11 16 21 34 35 37
Bucket 3: 1 4 12 14 29 42 48
Bucket 4: 10 32 45 46
Bucket 5: 15 30 33 43
Bucket 6: 25 47
Bucket 7: 3 5 17 18 19 20 23 24
Overflow buckets: 0
Bucket 0: 0 1 2 3 4 5 6 7Code snippet https://play.golang.org/p/xgyQEatPHgT
Predefined size
Sometimes you now, how many items you need to put in map. For maps with known size, is better to specify size at the moment of creation. Go will automatically create suitable number of buckets, so expenses of grow process could be avoided.
m := make(map[int]int, 1000000)
_, hm := mapTypeAndValue(m)
fmt.Printf("Elements | h.B | Buckets\n\n")
fmt.Printf("%8d | %3d | %8d\n", hm.count, hm.B, 1<<hm.B)
for i := 0; i < 1000000; i++ {
m[i] = i * 3
}
fmt.Printf("%8d | %3d | %8d\n", hm.count, hm.B, 1<<hm.B)Result:
Elements | h.B | Buckets
0 | 18 | 262144
1000000 | 18 | 262144Code snippet https://play.golang.org/p/cnijjiKwM8o
Deletion and ever growing map
What you should know about Go builtin maps, that they can only grow. Even if you delete all values from map, number of buckets will remain the same, so is memory consumption.
m := make(map[int]int)
_, hm := mapTypeAndValue(m)
fmt.Printf("Elements | h.B | Buckets\n\n")
for i := 0; i < 100000; i++ {
m[i] = i * 3
}
for i := 0; i < 100000; i++ {
delete(m, i)
}
fmt.Printf("%8d | %3d | %8d\n", hm.count, hm.B, 1<<hm.B)Result:
Elements | h.B | Buckets
0 | 14 | 16384Code snippet https://play.golang.org/p/SPWixru8sdM
Links and thanks
All code mentioned in article could be found here: https://github.com/kochetkov-av/golang-map-insights
Big thanks to author of https://lukechampine.com/hackmap.html and of course to The Go Authors!












