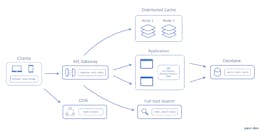
In the previous article, we have seen how to ensure the high availability of Distributed Systems.
Taking as an example the Cache, we created two replicas of service clusters, however, we didn’t discuss how we would optimally access these clusters in such a way that we don’t load any of the clusters too much, and at the same time, take advantage of high-availability and essential consistency that we created.
Round Robin is the answer.
The Problem Statement
Having two cache clusters gives us data replication and data consistency. However, a logical question arises, how do we send requests to them when we want to retrieve value from the cache?
The simple solution would be to ask one service cluster (for example, cluster A), and only in case of failure, ask cluster B. This approach is presented in Figure 1:

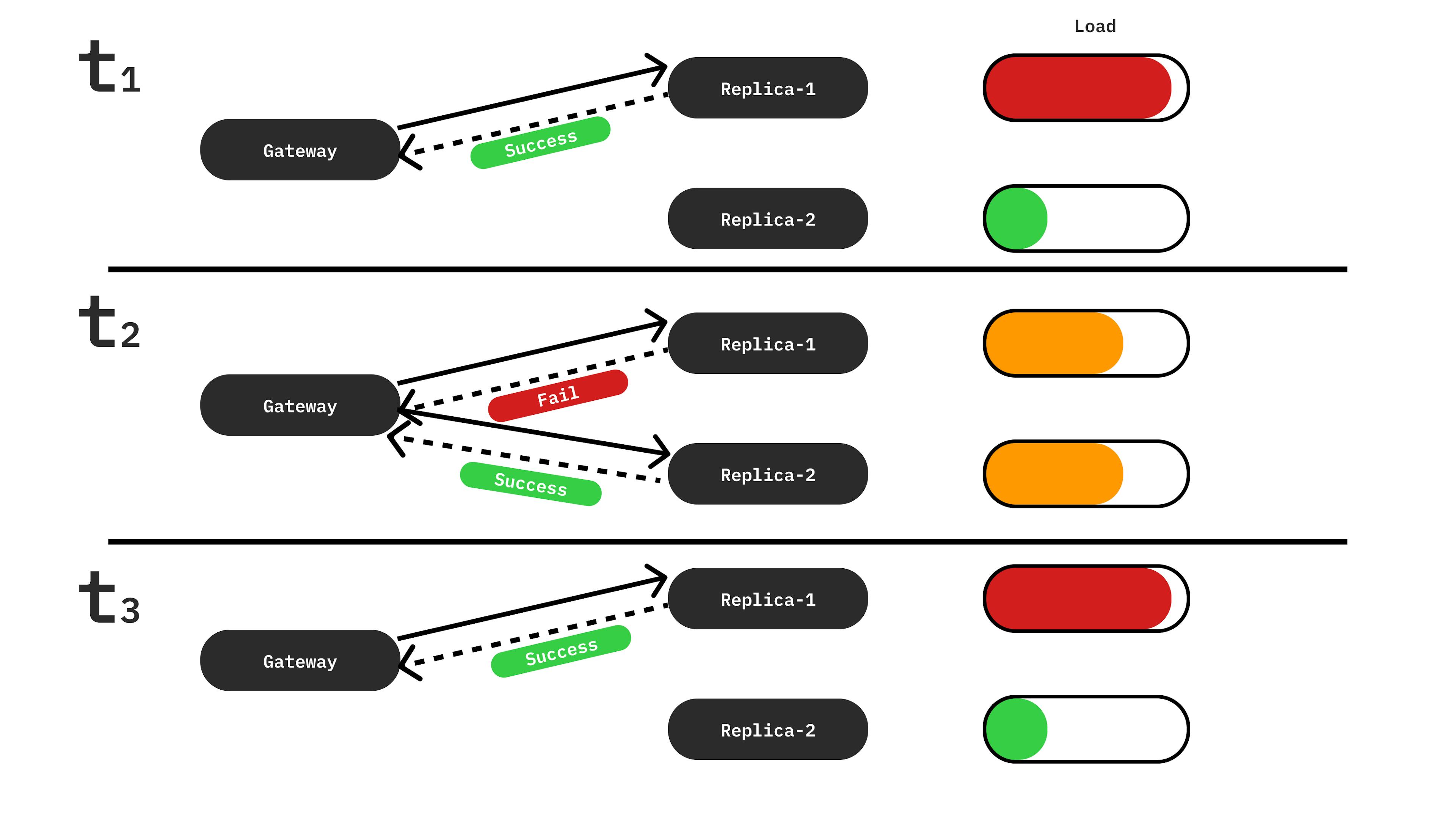
But in this case, cluster A may be overloaded, and cluster B would not be used most of the time. So this isn’t a solution. The second way of handling it would be a random calling of services.
These may be a reasonable solution in some cases, but randomness in Distributed Systems adds even more problems, making it even more unstable and hard to monitor.
And here, the Round Robin algorithm comes into play. This approach is shown in Figure 2:

Round Robin Algorithm
Round Robin (or shortly RR) is an algorithm for sharing computational resources between processes. In the computer, we have only some CPU cores that can execute programs. These programs are usually split into a bunch of processes that need access to the CPU to execute their instructions.
At every moment, a CPU core can execute a single process, however, if the CPU would execute processes sequentially, then running more programs at the same time would be impossible. To make the running of more programs in parallel possible, the computer uses Context Switches.
A Context Switch is a phenomenon of moving from one running thread (or process) to another; even if the execution of the first didn’t end up. The first process is put on hold, while the second one is started or continues execution from the last instruction executed.
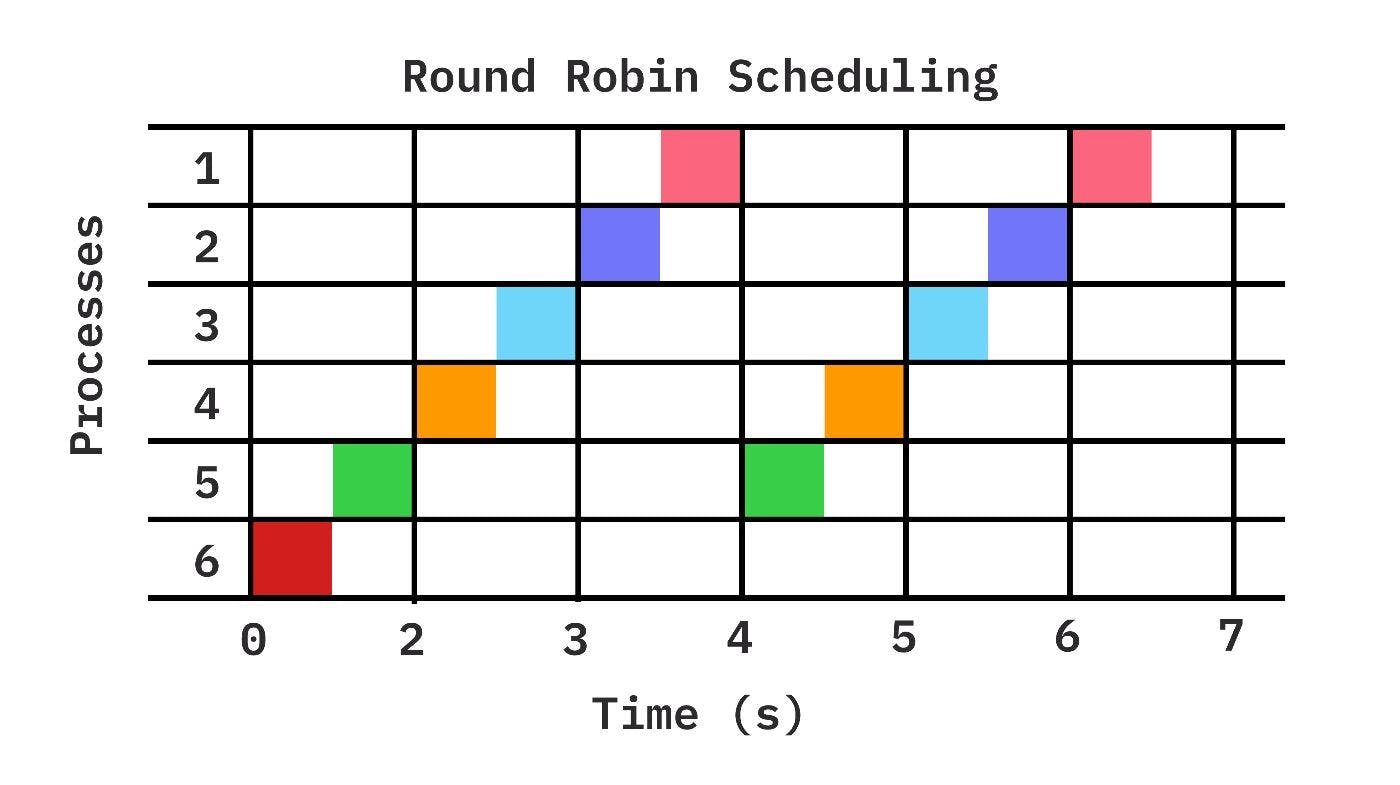
Round Robin uses a context switch to move constantly from one process to another by giving a constant amount of time on the CPU to each process till it finishes executing. New processes added to the queue processes are getting processing time too when their time comes.
In such a way, there is no processed starvation (a process doesn’t get access to resources at any time).
![]Figure 3: Round Robin Scheduling Algorithm.
base64 images have been removed. Instead, use an URL or a file from your device

Round Robin For Load Balancing
Round Robin can be used in Distributed Systems too. Usually, it is used for load balancing. When the system has more replicas of the service (as in our case with caches) a system of balancing the load in this service is needed.
While the Load Balancing in the Round Robin initial formulation the processes are changed with services, while the CPU time is changed with requests.
To better understand it, suppose we have two services, A and B. The first request would be done to service A. The wheel is turning, and the next request goes to Service B. And then again to Service A, and so on.
NOTE: During our implementation, we are going to do an additional check request to another service in case of the failure to one, to save the property of replication that we have in our Caches.


The Python Implementation
First, we are going to implement the RR algorithm as a class, this time for Cache access, but you can reuse it for your use case.
Starting with the class Constructor, it takes as arguments a dictionary with the credentials of the services, including the host and port (also, you can, for example, include access tokens).
import requests
class CacheRoundRobin:
def __init__(self, caches : dict) -> None:
'''
The constructor of the Cache Round Robin load balancer.
:param caches: dict
The dictionary contains the credentials of the caches services.
'''
self.caches = caches
self.caches_list = list(self.caches.keys())
self.responsible_cache = self.caches_list[0]
The dictionary sent to the class constructor has the following schema:
{
"cache-1" : {
"host" : "127.0.0.1",
"port" : 7000
},
"cache-2" : {
"host" : "127.0.0.1",
"port" : 7001
}
}
In this dictionary, every element is a dictionary with the service credentials containing the host and port.
Turning Function
Next, we need a function that would give the responsibility to the next service. For this purpose, we just find the next service in the service list and make him responsible for the next request.
def turn(self):
'''
This function turns the round robin and gives the responsibility to make requests to other person.
'''
# Getting the responsible cache service index.
resp_index = self.caches_list.index(self.responsible_cache)
# Setting the next cache service as the responsible one using the previous index.
if resp_index + 1 == len(self.caches_list):
self.responsible_cache = self.caches_list[0]
else:
self.responsible_cache = self.caches_list[resp_index]
Now that we implemented the function, changing the responsible service, we can get to the function for requesting values from the cache. The function will take as an argument the request payload and return the result or None in case of missing value.
def get_value(self, payload : dict):
'''
This function makes the request to the responsible service.
:param payload: dict
The payload of the request.
:return: dict or None
The response payload.
'''
# Making the request to the responsible service.
response = requests.get(
f"https://{self.caches[self.responsible_cache]['host']}:{self.caches[self.responsible_cache]['port']}/cache",
json = payload
)
# Checking if the status of the request.
if response.status_code == 200:
# Turning the round robin and returning the response in case of successful request.
self.turn()
return response.json()
else:
# Getting another service from cache services list and making it temporarily responsible for requests
resp_index = self.caches_list.index(self.responsible_cache)
if resp_index + 1 == len(self.caches_list):
next_cache = self.caches_list[0]
else:
next_cache = self.caches_list[resp_index]
# Making the request.
response = requests.get(
f"https://{self.caches[next_cache]['host']}:{self.caches[next_cache]['port']}/cache",
json = payload
)
# Turning the round robin.
self.turn()
# Returning the result.
if response.status_code == 200:
return response.json()
else:
return None
In the client code using this class, every call of the get_value function will change the responsible service, and the next request will go to another service. Also, in the case of an error, the class will try another call to another service.
In case of success, the RR will return the response from the first or second service; if there is fail in both services, the None value will be returned.
Conclusion
Having multiple replicas of service in a distributed system has its strengths and weaknesses. It lowers the latency, however, if not implemented correctly can make things worse.
Round Robin is an easy and functional solution for load balancing in replica services, very often being used in Gateways.
The full commented code of the class can be found here: GitHub URL
Written by Păpăluță Vasile
LinkedIn:https://www.linkedin.com/in/vasile-păpăluță/
Instagram:https://www.instagram.com/science_kot/
GitHub:https://github.com/ScienceKot