









Splunk can be a complex beast, with its various components, requirements, and best practices on top of the OS selection and infrastructure design…deploying it can feel like an impossible task. Lucky for us, Splunk has created Validated Architectures that are proven to be effective and….just work.
To truly appreciate what the Splunk Validated Architectures are, you need to first take a few steps back and look at how Splunk was deployed before 2017 when the Validated Architecture white paper was released. As a customer, you were left with two choices.
-
Either you hired a consultancy to come in and train you while designing your Splunk infrastructure OR
-
you spent days and weeks building up the required level of knowledge to understand Splunk well enough to deploy it.
The stakes were high! On one hand, you might spend tens or hundreds of thousands of dollars with a consultancy and end up with an architecture you barely understand. On the other, you might attempt to build it yourself and wind up rebuilding it (at a much greater expense) down the road when it fails to scale or you run into performance issues.
Fast forward to 2017, when the Splunk Validated Architectures (SVAs) were made public at Splunk’s .conf2017 conference in Washington DC. The validated architectures gave everyone the hard-earned knowledge and wisdom to build a world-class Splunk architecture that suited their needs. The SVAs provided a few notable benefits. First, they allowed customers to standardize their architecture to one that is known and understood by Splunk support. This in turn streamlined troubleshooting sessions and future architecture decisions. Second, this reduced the total cost of ownership (TCO) for Splunk deployments. Because the architectures were tuned for just enough power, but not too much, you no longer had to worry that you had over-provisioned your hardware stack. Third, and maybe most importantly, it allowed you (the Splunk customer) to begin your Splunk journey heading down the right path. You could focus on data onboarding, user training, and content creation in Splunk instead of constantly worrying about your design decisions.
The Splunk SVAs lay out seven architectures, although there are really three that are the most popular. Those three will be what we focus on here, the other four are great…but most people reading this won’t need help figuring those other four out…they will be paying a consultant.
The “Single Server Deployment”


All Splunk components, from indexing, and licensing to searching, are installed on a single server. This is a great way to get started in Splunk if the reasons why you use Splunk are not mission-critical. Because this is a single-server architecture, you will have no redundancy. This means when it comes time to patch Splunk or the OS, Splunk will be offline during that period and no logs will be collected. No one will be able to access Splunk for content and no alerts will be generated during this down period. This single-server SVA is also limited in its capacity to ingest data. Splunk says it will handle ~300GB a day, but that sounds like a made-up number. I would put the number closer to 150GB a day. It is however a really simple deployment with very low overhead.
The “Distributed Clustered Deployment - single site”

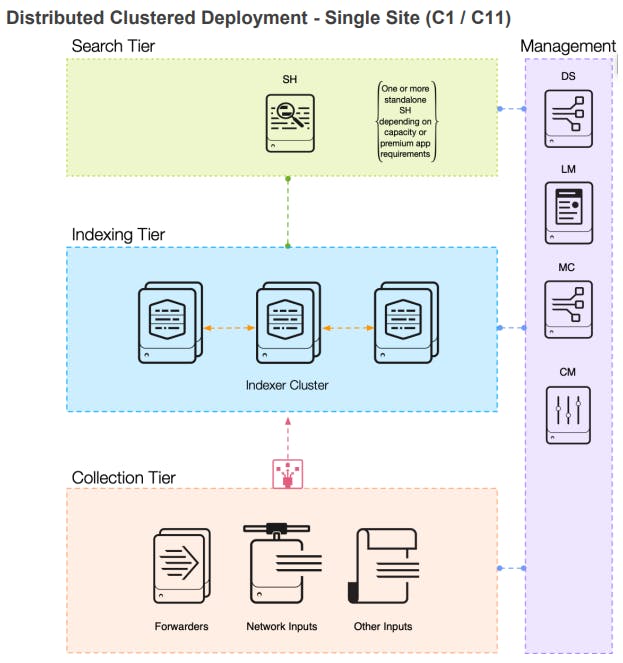
In this model, the major Splunk components are separated from each other. This establishes the three-tier approach with a separate management plane. The first tier is the collection tier, which includes universal forwarders, heavy forwarders, and all other data sources. The next tier is dedicated to data ingesting and parsing, and it’s called the indexing tier. In this tier, there are two or more “indexer” servers that are centrally managed by an indexer cluster master. The indexer cluster master maintains unified configurations across all of the indexers in the cluster, allowing administrators a simple path toward scaling the index as the need arises. It’s important to remember, the indexer cluster master is a separate Splunk component that is installed on a separate dedicated server (possibly along with other management components like the license master, management console, and deployment server).
This SVA has a single search head, which means that while there is data ingest redundancy provided by the indexer cluster there isn’t any redundancy for search head activities like content creation, report & alert generation, or running queries. This is a very popular architecture that many organizations choose to use because of the redundant data ingest capabilities. Although there isn’t redundancy in the search head, search head failures are very rare and can be easily resolved with a reboot.
The Multi-Site Distributed Clustered Deployment with a Search Head (SHC)


This architecture takes redundancy to the next level by effectively cloning the single-site distributed deployment we just talked about. Not only is each site redundant and able to process data independent of the other sites’ clusters, but there is also a complete set of data replicated between sites. That, coupled with a search head cluster per site provides a measure of redundancy not found in any other SVA. This does however increase the complexity of the deployment, increase the TCO through infrastructure costs, and can make troubleshooting more difficult because of the issues that are common when connecting two remote sites together.
If your organization operates in multiple clouds or on-premises data centers and you have the requirement to deliver Splunk as though it’s a mission-critical app, this SVA is hard to pass on.
I focused this post on reviewing the 3 best SVAs made available through the Splunk white paper, but I would be remiss if I didn’t mention that nearly half of the white paper is dedicated to showcasing the nuances of clustered search head and indexer configurations. If those are topics that you are curious about, be sure to check out the rest of the white paper.
Also Published Here












