







Reason
In modern distributed systems, efficient real-time data discovery and integration are common tasks. We often encounter approaches involving multiple queues or services that collect data into a database, followed by various search queries. But what if I told you that it's not necessary to store data in a database when you can read data directly from Kafka as if it were a table?
Apache Kafka, a powerful event streaming platform, offers robust capabilities for data discovery and real-time data integration, making it a versatile solution for building scalable event-driven architectures.
This article will explore how to use Kafka for convenient data exploration and dynamic data integration.
Short intro


Understanding Kafka Topics and Event Streams
Apache Kafka operates on a "publish-subscribe" model, organizing data into topics. Producers publish records (events) to specific topics, and consumers subscribe to these topics to process records in real-time. Each record in a topic typically contains key-value pairs representing structured data.
Key Features for Data Discovery in Kafka
Topic Partitioning and Scalability: Kafka topics are divided into partitions, allowing data to be distributed across multiple brokers for scalability. This partitioning enables parallel processing and efficient data retrieval.
Retention and Compaction: Kafka retains data for a configurable period, allowing consumers to replay events within a specified time window. Log compaction ensures that only the latest value for each key is retained, simplifying data management.
Use Cases
Real-time Analytics: Aggregating and analyzing streaming data from various sources in real-time to derive meaningful insights.
Dynamic Data Enrichment: Enhancing incoming data streams by joining with reference data or historical records stored in Kafka.
Fraud Detection: Detecting anomalies or fraudulent patterns by correlating events and transactions in real-time.
Practice!
By default, we didn’t change anything; we just know that Kafka saves all our messages in topics and we can read them. But also, we can work with topics like SQL tables.
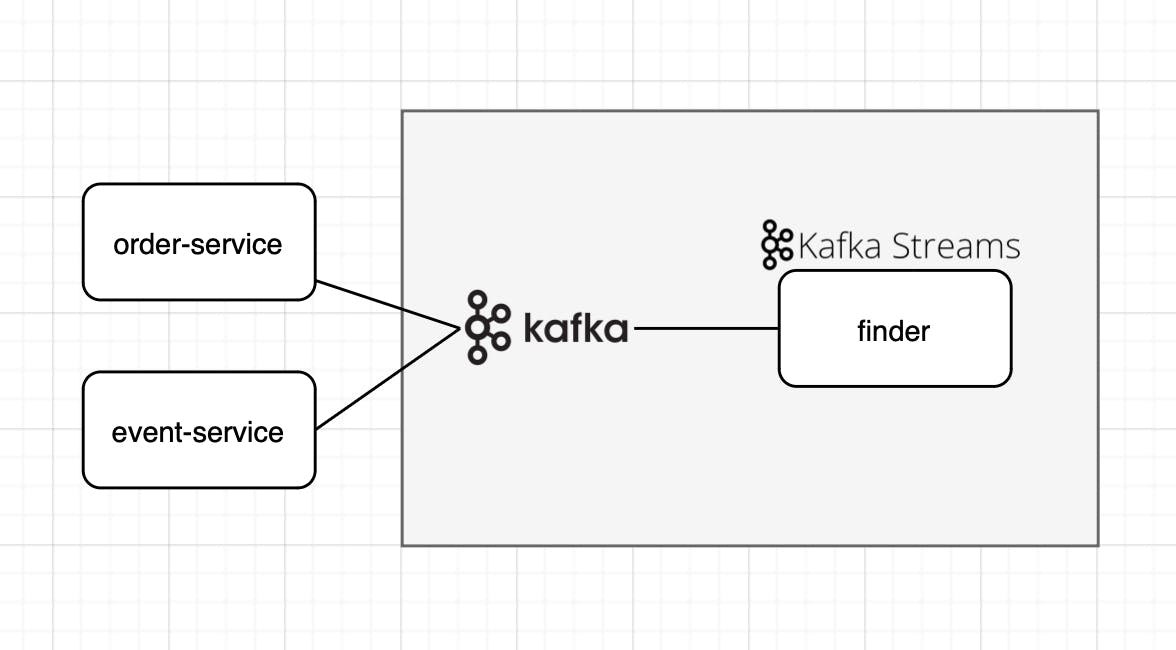
So, we should imagine that we have two services. The first one processes messages which consist of important information for our department. We have a topic “events,“ and it has a structure like this:
{
"product_id": "2e7bca59-406b-48e3-b92c-f0a744bda108",
"timestamp": 1713648805,
"category": "OfficeSupplies",
"app": "GoShop",
"session_id": "af9dd378-0021-42c8-82ca-9fc1a861a342",
"user_id": "af9dd378-0021-42c8-82ca-9fc1a861a342"
}
Important fields here:
user_id // uniq uuid v4
and
category // uniq goods category name
The second one sends purchase info when our user buys something. Example:
{
"order_id": "0ce3260e-f896-45e2-b8e9-88a4dea8fb7b",
"user_id": "76046ad5-ffda-4f06-8c1e-730de11f585a",
"order_time": 1713649496,
"total_price": 96.9778306289559,
"products": [
{
"product_id": "b19494c5-6913-42a6-aab1-80049334d107",
"category": "Furniture",
"price": 42.82092921543266
},
{
"product_id": "20d44dc0-a648-4b49-908f-609ef7bd9e6d",
"category": "Books",
"price": 4.742365306930942
},
{
"product_id": "9f2fb735-32b1-4a8a-aeee-d25312d284e3",
"category": "Electronics",
"price": 49.41453610659229
}
]
}
We can see that it has a category field as well. Now, we have a relatively simple task: to identify all purchases that occurred after our user visited a specific category. For example, a user decides to browse the electronics category and later purchases a new laptop. We have both events - the browsing and the purchase. Our goal is to determine whether they are linked to each other based on the user's user_uuid.
This time, we'll need to write a small piece of Java code because it has been the best choice for working with Kafka for several years now. Kafka and stream processing are my main focus, so feel free to ask any questions related to Kafka or stream processing.
Let’s Start!
-
Shop stream - We should create the first stream using the “shop-purchase“ topic.
KStream<String, PurchaseRecord> shopStream = kStreamBuilder.stream( streamProperty.shopTopic(), Consumed.with(Serdes.String(), new JsonSerde<>(PurchaseRecord.class)) ); -
Event stream - The second stream uses the “events“ topic.
KStream<String, EventRecord> viewStream = kStreamBuilder.stream( streamProperty.eventTopic(), Consumed.with(Serdes.String(), new JsonSerde<>(EventRecord.class)) ); -
We need to merge it into a new one, but only not null values:
KStream<String, EnrichedPurchase> enrichedPurchases = shopStream.join( viewStream.toTable(), // to table (purchase, view) -> { if (purchase.userId().equals(view.userId())) { // find same use Optional<String> category = purchase.products() // consist?? .stream() .map(ProductRecord::category) .filter(f -> f.equals(view.category())) .findFirst(); if (category.isPresent()) { // at least one! return new EnrichedPurchase(view, purchase); } } return null; } ).map(KeyValue::new) .filter((i, v) -> v != null); -
Send to result topic:
enrichedPurchases.to( streamProperty.resultTopic(), Produced.with(Serdes.String(), new JsonSerde<>(EnrichedPurchase.class)) );
As a result, we send:
{
"event": {
"product_id": "c49ff516-90fc-4e94-9538-bb0b24d148a9",
"session_id": "e5adff32-f8c6-4b35-903d-07d85415d681",
"user_id": "2e5a847b-08bd-48ae-8c42-bee0a5391b30",
"timestamp": 1713702160,
"category": "PetSupplies",
"app": "GoShop"
},
"purchase": {
"order_id": "7f8eb08c-3e77-46b9-b8b1-3f4250c76386",
"user_id": "2e5a847b-08bd-48ae-8c42-bee0a5391b30",
"total_price": 440.87111325777965,
"orderTime": 0,
"products": [
{
"product_id": "4610a39e-ba5e-4034-b45e-7d3dc738e364",
"category": "PetSupplies",
"price": 57.415938152296654
}
]
}
}
The full code is available here:
Conclusion
Apache Kafka simplifies data discovery and dynamic data integration by providing a unified platform for event streaming and data integration. By leveraging Kafka's scalability, retention policies, and stream processing capabilities, developers can create efficient, scalable, event-driven applications without the need for separate databases or complex data pipelines.
Using the Kafka ecosystem, such as Kafka Streams and Kafka Connect, organizations can harness event-driven architecture capabilities to unlock new opportunities in data exploration, integration, and real-time analytics.
If you don't require a complex architecture, there's no need to maintain long-term data storage or to set up separate databases for various metrics, consider using Kafka Streams. This tool allows you to process data without having to create additional structures and enables real-time data reading.
Moreover, you can easily redirect processed data from several topics into a new one for further storage or utilization. This is particularly convenient for performing analytical calculations.
Also, I’d recommend finding books here: https://kafka.apache.org/books-and-papers













