










This publication provides an in-depth overview of various neural network layers, including their historical development, mathematical formulations, and code implementations. We cover common layer types such as dense, convolutional, recurrent, and attention layers, as well as their specialized variants.
Furthermore, it presents Python code snippets using popular deep-learning frameworks to demonstrate their practical application.
Introduction
Neural networks are a subset of machine learning algorithms that mimic the human brain's structure and function. They consist of interconnected layers of artificial neurons that process and transform input data into meaningful outputs.
In this publication, we explore various types of neural network layers, their history, mathematical formulations, and code implementations using popular deep learning frameworks such as TensorFlow and PyTorch.
Dense Layers


Dense Layers, also known as fully connected layers, have been a fundamental building block in neural networks since their inception. In 1958, Frank Rosenblatt introduced the Perceptron, the first neural network model, which employed dense layers.
A dense layer performs a linear transformation of its input, followed by an activation function. The mathematical representation of a dense layer is:


And here is the PyTorch and TensorFlow implementation of these layers:
import torch.nn as nn
dense_layer = nn.Linear(in_features=64, out_features=128)
activation = nn.ReLU()
import tensorflow as tf
dense_layer = tf.keras.layers.Dense(units=64, activation='relu')
Convolutional Layers


Convolutional layers, a fundamental component of Convolutional Neural Networks (CNNs), were introduced in the 1980s by Yann LeCun, who developed the LeNet-5 architecture for handwritten digit recognition.
Convolutional layers are designed to exploit the spatial structure in images and have since become the standard for image processing and computer vision tasks.
A convolutional layer performs a convolution operation, where a filter or kernel slides over the input image, computing the dot product between the kernel and the input region. The output is a feature map representing spatial patterns in the input.
The operation is mathematically represented as:


Here is the PyTorch and TensorFlow implementation of these layers:
import torch.nn as nn
conv_layer = nn.Conv2d(in_channels=3, out_channels=32, kernel_size=(3, 3))
activation = nn.ReLU()
import tensorflow as tf
conv_layer = tf.keras.layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu')
Recurrent Layers

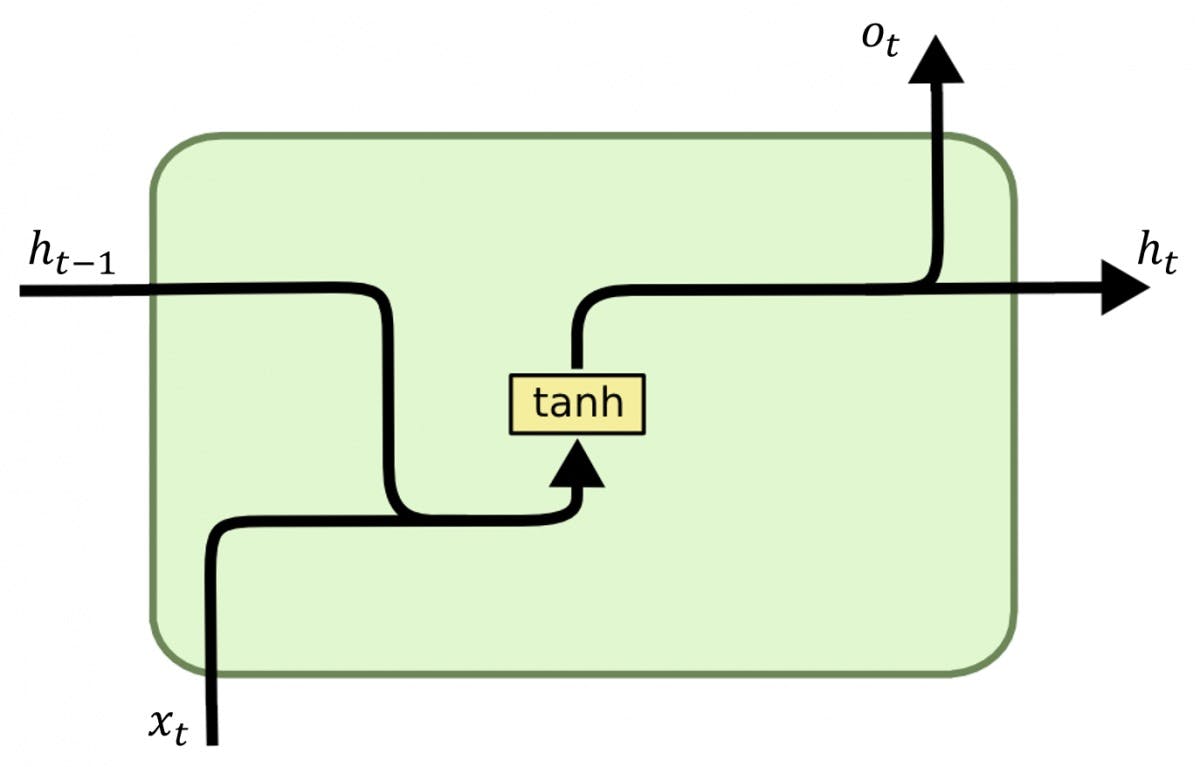
Recurrent layers, introduced in the 1980s, are the backbone of Recurrent Neural Networks (RNNs). RNNs are designed to process sequential data, making them suitable for tasks such as natural language processing, time series prediction, and sequence-to-sequence learning.
A prominent early work is the Elman Network by Jeff Elman.
Recurrent layers maintain an internal hidden state that evolves over time, allowing them to capture information from previous time steps. The hidden state update is mathematically represented as:


PyTorch and TensorFlow implementation looks like this:
import torch.nn as nn
rnn_layer = nn.RNN(input_size=64, hidden_size=64, nonlinearity='tanh')
import tensorflow as tf
rnn_layer = tf.keras.layers.SimpleRNN(units=64, activation='tanh')
Attention Layers


Attention layers were introduced in 2014 by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio to address the limitations of fixed-length context vectors in sequence-to-sequence models.
The transformer architecture, proposed by Vaswani et al. in 2017, utilizes self-attention layers and has become the foundation for state-of-the-art natural language processing models like BERT and GPT.
Attention layers compute a weighted sum of input values based on their relevance to a given context. The attention mechanism is mathematically represented as:

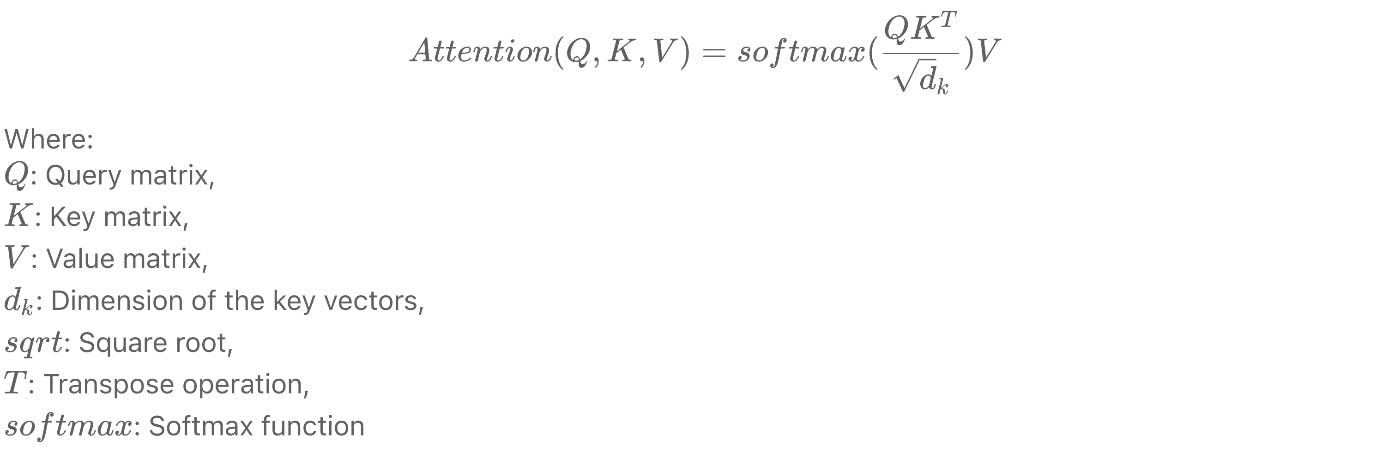
TensorFlow implementation is quite simple:
import tensorflow as tf
attention_layer = tf.keras.layers.Attention()
PyTorch has no simple attention layer implementation, so it can be defined via custom class Attention or also MultiHeadAttention can be used:
import torch
import torch.nn.functional as F
import torch.nn as nn
class Attention(torch.nn.Module):
def __init__(self, dim):
super(Attention, self).__init__()
self.dim = dim
self.query = torch.nn.Linear(dim, dim)
self.key = torch.nn.Linear(dim, dim)
self.value = torch.nn.Linear(dim, dim)
def forward(self, input):
Q = self.query(input)
K = self.key(input)
V = self.value(input)
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.dim)
weights = F.softmax(scores, dim=-1)
return torch.matmul(weights, V)
#or with multihead:
multihead_attn = nn.MultiheadAttention(embed_dim, num_heads=1)
Specialized Layers
In addition to the common layer types, several specialized layers have been developed to address specific challenges in neural network training and improve model performance. We discuss a few notable examples below:
Batch Normalization


Batch normalization, introduced by Sergey Ioffe and Christian Szegedy in 2015, addresses the issue of internal covariate shifts in deep neural networks. This technique normalizes the inputs of each layer to improve training speed and stability.
Batch normalization calculates the mean and variance of each feature within a mini-batch and normalizes the features accordingly. It can be represented as:


And here is Python implementations:
import torch.nn as nn
batch_norm_layer = nn.BatchNorm2d(num_features=64)
import tensorflow as tf
batch_norm_layer = tf.keras.layers.BatchNormalization()
Dropout


Dropout, introduced by Geoffrey Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov in 2014, is a regularization technique that helps prevent overfitting in neural networks.
During training, dropout randomly sets a fraction of the neurons to zero, preventing the model from relying too heavily on any single neuron.
Dropout is applied during training by randomly zeroing out a fraction of the input elements, controlled by the dropout rate p. The output is represented as:


PyTorch and TensorFlow code for Dropout:
import torch.nn as nn
dropout_layer = nn.Dropout(p=0.5)
import tensorflow as tf
dropout_layer = tf.keras.layers.Dropout(rate=0.5)
Long Short-Term Memory (LSTM)


Long Short-Term Memory (LSTM) is a type of recurrent layer introduced by Sepp Hochreiter and Jürgen Schmidhuber in 1997. LSTMs address the vanishing gradient problem in traditional RNNs, enabling them to learn long-range dependencies in sequences.
LSTM layers use a gating mechanism with three gates (input, forget, and output) and an internal cell state to control the flow of information through the network. The LSTM update equations are:


6.3.3 Code TensorFlow:
import torch.nn as nn
lstm_layer = nn.LSTM(input_size=64, hidden_size=64)
import tensorflow as tf
lstm_layer = tf.keras.layers.LSTM(units=64)
Gated Recurrent Units (GRU)


Gated Recurrent Units (GRU) were introduced by Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Dzmitry Bahdanau, Fethi Bougares, Holger Schwenk, and Yoshua Bengio in 2014 as a simplified alternative to LSTMs.
GRUs have fewer parameters and are computationally more efficient while still addressing the vanishing gradient problem.
6.4.2 Formulas GRU layers use a gating mechanism with two gates (update and reset) to control the flow of information through the network. The GRU update equations are:


6.4.3 Code TensorFlow:
import torch.nn as nn
gru_layer = nn.GRU(input_size=64, hidden_size=64)
import tensorflow as tf
gru_layer = tf.keras.layers.GRU(units=64)
Conclusion
In this publication, we have explored various types of neural network layers, their historical development, mathematical formulations, and code implementations.
Understanding these layers and their specialized variants is essential for designing and training effective neural network models.
By combining these building blocks in innovative ways, researchers and practitioners can continue to advance the state of the art in deep learning and create novel solutions for complex problems.












