






75,559 reads
More than a Million Pro-Repeal Net Neutrality Comments were Likely Faked
by Jeff KaoNovember 22nd, 2017




Too Long; Didn't Read
<em>[Update on 11–29–2017: I’ve posted multiple </em><a href="https://www.kaggle.com/jeffkao/proc_17_108_unique_comments_text_dupe_count" target="_blank"><em>datasets</em></a><em> and my </em><a href="https://github.com/j2kao/fcc_nn_research" target="_blank"><em>code</em></a><em> containing enough for you to reproduce the analysis. Please share with the rest of us what else you find — *gets on soapbox* — a free internet will always be filled with competing narratives, but well-researched, reproducible data analyses can establish a ground truth and help cut through all of that. Look forward to seeing your analyses & there will be more data to come!]</em>People Mentioned

Companies Mentioned


I used natural language processing techniques to analyze net neutrality comments submitted to the FCC from April-October 2017, and the results were disturbing.
[Update on 11–29–2017: I’ve posted multiple datasets and my code containing enough for you to reproduce the analysis. Please share with the rest of us what else you find — *gets on soapbox* — a free internet will always be filled with competing narratives, but well-researched, reproducible data analyses can establish a ground truth and help cut through all of that. Look forward to seeing your analyses & there will be more data to come!]
NY Attorney General Schneiderman estimated that hundreds of thousands of Americans’ identities were stolen and used in spam campaigns that support repealing net neutrality. My research found at least 1.3 million fake pro-repeal comments, with suspicions about many more. In fact, the sum of fake pro-repeal comments in the proceeding may number in the millions. In this post, I will point out one particularly egregious spambot submission, make the case that there are likely many more pro-repeal spambots yet to be confirmed, and estimate the public position on net neutrality in the “organic” public submissions.¹
Key Findings:²
- One pro-repeal spam campaign used mail-merge to disguise 1.3 million comments as unique grassroots submissions.
- There were likely multiple other campaigns aimed at injecting what may total several million pro-repeal comments into the system.
- It’s highly likely that more than 99% of the truly unique comments³ were in favor of keeping net neutrality.
Breaking Down the Submissions
Given the well documented irregularities throughout the comment submission process, it was clear from the start that the data was going to be duplicative and messy. If I wanted to do the analysis without having to set up the tools and infrastructure typically used for “big data,” I needed to break down the 22M+ comments and 60GB+ worth of text data and metadata into smaller pieces.⁴
Thus, I tallied up the many duplicate comments⁵ and arrived at 2,955,182 unique comments and their respective duplicate counts. I then mapped each comment into semantic space vectors⁶ and ran some clustering algorithms on the meaning of the comments.⁷ This method identified nearly 150 clusters of comment submission texts of various sizes.⁸
After clustering comment categories and removing duplicates, I found that less than 800,000 of the 22M+ comments submitted to the FCC (3-4%) could be considered truly unique.
Here are the top 20 comment ‘campaigns’, accounting for a whopping 17M+ of the 22M+ submissions:


The vast majority of FCC comments were submitted as exact duplicates or as part of letter-writing/spam campaigns.
So how do we know which of these are legitimate public mailing campaigns, and which of these were bots?
Identifying 1.3 Million Mail-Merged Spam Comments
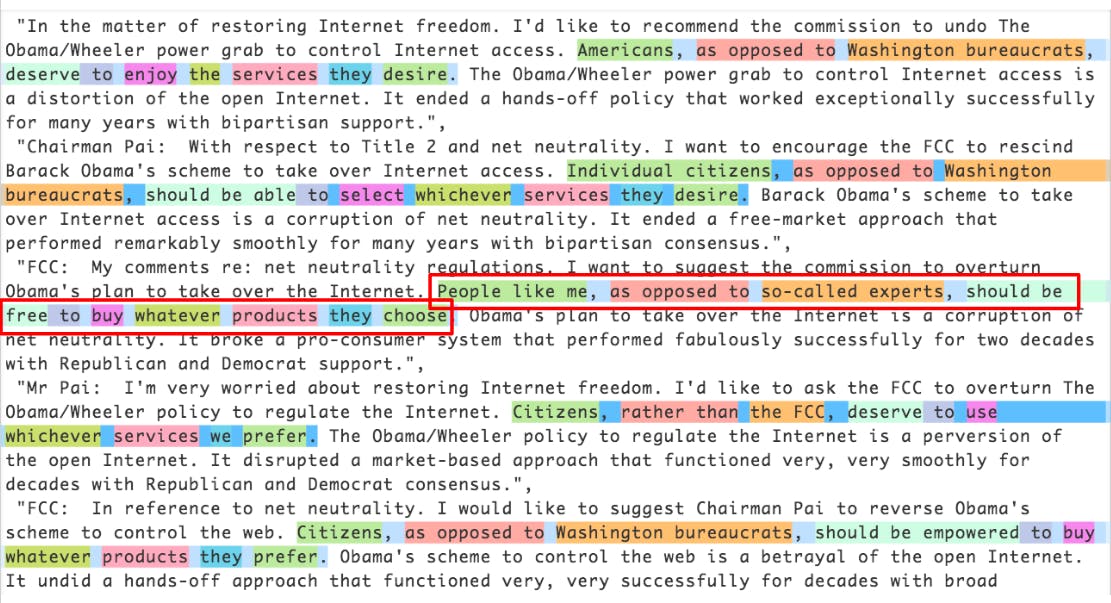
The first and largest cluster of pro-repeal documents was especially notable. Unlike the other clusters I found (which contained a lot of repetitive language) each of the comments here was unique; however, the tone, language, and meaning across each comment was largely uniform. The language was also a bit stilted. Curious to dig deeper, I used regular expressions⁹ to match up the words in the clustered comments:
I found the term “People like me” particularly ironic.
It turns out that there are 1.3 million of these. Each sentence in the faked comments looks like it was generated by a computer program. A mail merge swapped in a synonym for each term to generate unique-sounding comments.¹⁰ It was like mad-libs, except for astroturf.
When laying just five of these side-by-side with highlighting, as above, it’s clear that there’s something fishy going on. But when the comments are scattered among 22+ million, often with vastly different wordings between comment pairs, I can see how it’s hard to catch. Semantic clustering techniques, and not typical string-matching techniques, did a great job at nabbing these.
Finally, it was particularly chilling to see these spam comments all in one place, as they are exactly the type of policy arguments and language you expect to see in industry comments on the proposed repeal¹¹, or, these days, in the FCC Commissioner’s own statements lauding the repeal.¹²
Pro-Repeal Comments were more Duplicative and in Much Larger Blocks
But just because the largest block of pro-repeal submissions turned out to be a premediated and orchestrated spam campaign¹³, it doesn’t necessarily follow that there are many more pro-repeal spambots to be verified, right?
As it turns out, the next two highest comments on the list (“In 2015, Chairman Tom Wheeler’s …” and “The unprecedented regulatory power the Obama Administration imposed …”) have already been picked out from previous reporting as possible astroturf as well.
Going down the list, each comment cluster/duplicate would need its own investigation, which is beyond the scope of this post. We can, however, still gain an understanding of the distribution of comments by taking a broader view. Reprising the bar chart above breaking down the top FCC comments, let’s look at the top 300 comment campaigns that comprise an astonishing 21M+ of the 22M+ submissions¹⁴:


Keep-Net Neutrality comments were much more likely to deviate from the form letter, and dominated in the long tail.
From this chart we can see that the pro-repeal comments (there are approximately 8.6 million of them) are much more likely to be exact duplicates (dark red bars) and are submitted in much larger blocks. If even 25% of these pro-repeal comments are found to have been spam, that would still result in more than 2 million faked pro-repeal comments, each with an email address attached. Further verification should be done on the email addresses used to submit these likely spam comments.
On the other hand, comments in favor of net neutrality were more likely to deviate from a form letter (light green, as opposed to dark green bars) and were much more numerous in the long tail. If the type, means of submission, and ‘spamminess’ of comments from both sides were equal, we would expect a roughly even distribution of light and dark, red and green, throughout the bars. This is evidently not the case here.¹⁵
Organic Public Comments: 99%+ Support Keeping Net Neutrality
And what of the less than 800,000 comments submitted that were not a duplicate or clustered as part of a comment category? Does the trend of comments turning in favor of net neutrality continue in the long tail?
It turns out old-school statistics allows us to take a representative sample and get a pretty good approximation of the population proportion and a confidence interval. After taking a 1000 comment random sample **of the 800,000 organic comments and scanning through them, I was only able to find three comments that were clearly pro-repeal.**¹⁶ That results in an estimate of the population proportion at 99.7%. In fact, we are so near 100% pro net neutrality that the confidence interval goes outside of 100%.¹⁷ At the very minimum, we can conclude that the vast preponderance of individuals passionate enough about the issue to write up their own comment are for keeping net neutrality.
Oh, and please do take a minute to scan through the samples I’ve provided. Those are the comments of real people being affected by this decision, who speak most personally and devastatingly about its impacts:
I am 82, handicapped, and home bound, but not lonely, because I have the free internet. I can roam the world. use Facebook to visit family friends. I can sell my work on Etsy without fear of Amazon getting preference should the 2015 law be repealed. If you (The FCC) no longer had oversight, my ISP could raise its prices so that I couldn’t afford to have the Internet at all! I am relying on the FCC to protect me and others like me.¹⁸
Conclusion
Public participation and civic engagement are fundamental to a functioning democracy. It’s scary to think that organic, authentic voices in the public debate — more than 99% of which are in favor of keeping net neutrality — are being drowned out by a chorus of spambots.¹⁹ We already live in a time of low faith in public institutions, and given these findings, I fear that the federal regulatory public comment process may be yet another public forum lost to spam and disinformation.
With the overwhelming actual public support for keeping net neutrality, it’s irresponsible for the FCC majority to simply wave their hand and disregard public opinion in the latest draft order, merely because of irregularities in the public record, or because the public comments weren’t written in legalese.
FCC chairman Ajit Pai’s office not only needs to furnish the evidence sought by AG Schneiderman, they need to respond to the FOIA requests regarding the net neutrality public comments candidly and transparently, to restore public confidence in the FCC rulemaking process.
Additional Notes:
- There have been some great analyses focused on the non-textual elements of the submissions, for example, their timing, the email addresses used, and other metadata. Shout out to the work of Jeffrey Fossett, who did a first pass analysis of the partially submitted comments in May that inspired this post and some of the methods used in the analysis, to Chris Sinchok, GravWell, and many other posts I studied in preparing this analysis.
- Let me know here if you have any questions or would like access to the dataset I scraped from the FCC’s ECFS submission system — if enough folks request it, I may host the dataset on Google BigQuery so you can run SQL queries on the ~64 GB dataset on your own.
Footnotes:
¹ I.e., not from a spambot or part of an identified campaign.
² Full disclosure: I was a summer law clerk for Commissioner Clyburn in 2010, and though I greatly admire her recent work championing net neutrality, the opinions and POV in this post are my own.
³ Not clustered as part of a comment submission campaign, not a duplicate comment.
⁴ Data collected from beginning of submissions (April 2017) until Oct 27th, 2017. The long-running comment scraping script suffered from a couple of disconnections and I estimate that I lost ~50,000 comments because of it. Even though the Net Neutrality Public Comment Period ended on August 30, 2017, the FCC ECFS system continued to take comments afterwards, which were included in the analysis.
⁵ I used an md5 hash function, which had a low enough collision rate and allowed me to (relatively) quickly find and count up duplicates. I tossed out submissions with no express comment text but otherwise did not do any other text preprocessing on the text before encoding and clustering in order to preserve artifacts in the text that may give clues as to the method of submission.
⁶ A large proportion of these ~3 million “unique” comments were essentially duplicates — only differing by a few characters or words or having a different signature. In order to conclusively and exhaustively categorize these comments, I chose to group comments by meaning. Comments were turned into document vectors comprised of the average of all word vectors in the comment. The word vectors were obtained from spaCy, which uses the word vectors from the paper by Levy and Goldberg (2014). [Correction from Matthew Honnibal: spaCy now uses the GloVe vectors by Pennington et al.]
⁷ I made two passes at clustering the document vectors. First with DBSCAN with a euclidean distance metric at a very low epsilon to identify obvious clusters [Update on 11–25–2017: After reviewing old code & to give slightly more detail, I used HAC to pick out the mad-lib clusters] and cull them out manually using a string signature. This left ~2 million unique comments. From that 2 million, I used HDBSCAN on a 100,000 comment sample with cosine distance to identify ‘looser’ clusters, and then used [approximate_predict()](http://hdbscan.readthedocs.io/en/latest/prediction_tutorial.html)to classify remaining comments as either within those identified clusters or as outliers. Removing duplicates, this resulted in less than 800,000 unique outlier “organic” comments. [Correction: As HDBSCAN Author Leland McInnes notes below, cosine distances don’t yet play well with HDBSCAN — to be exact, I used the euclidean distance metric between l2-normalized doc vectors, which typically works well as a substitute.]
⁸ Sized from the dozens to the millions.
⁹ Regular Expression in this pastebin.
¹⁰ This is because the combinations of comment configurations grows exponentially with each set of synonyms introduced. Also, to be precise, there were some mad-lib comments that were duplicated once, but not more than that.
¹¹ Page 3 of the Verizon Comments (submitted August 30, 2017)
¹² FCC Chairman Pai’s Statement re the Draft Order (published November 21, 2017)
¹³ While there are certainly other possible explanations for this set of results, I think Occam’s Razor should apply. More investigation into the timing and emails used for this particular campaign would provide more corroborating evidence.
¹⁴ Plotted on a log-scale so you can still see the color of the smaller bars.
¹⁵ As the author of the Gravwell study states: “[The evidence] forces us to conclude that either the very act of going to the FCC comment site and providing a comment is only attractive to those of a certain political leaning, or that the bulk submission information is full of lies.”
¹⁶ Pro-repeal comments are on lines 176, 228, 930 in the pastebin. There also appeared to be three net neutrality supporters that seemed confused about the terminology (lines 332, 366, 901) and one script kiddie (line 261). It’s possible I have missed one or two, and I’m happy to correct any mistakes in this comment set if you find them.
¹⁷ My more statistically-inclined colleague informs me that the central limit theorem breaks down at the extreme limits (where the population proportion is near 0% or 100% of a population), which I have taken his word/expertise for, for now, and will learn about later. [Edit: I have found a good addition to this on a reddit comment. The interval is 99.12% to 99.90%, 19 times out of 20.]
¹⁸ Line 102 in the pastebin.
¹⁹ [A final late addition: Lest I am unintentionally giving the wrong impression to folks who haven’t been following the net neutrality debate as closely, I want to be clear that there were suspicious campaigns from all sides of the debate from the text-only analysis; however, none were as numerous and as intentionally disguised as the 1.3M ‘unique’ comments identified in the post.]

L O A D I N G
. . . comments & more!
. . . comments & more!
About Author

TOPICS
THIS ARTICLE WAS FEATURED IN...



RELATED STORIES




Ajit Pai is Lying #net-neutrality
Dec 16, 2017
An FAQ for Defending Net Neutrality #net-neutrality
Dec 12, 2017

Disparate Impact: Who's Afraid of It? #society
Jan 28, 2024


