
Machine learning is transforming businesses around the world. It’s already a $7.3 billion market and is expected to continue its explosive growth to $30.6 billion by 2024.
Machine learning is enabling Al to become smarter and more intelligent. Autonomous vehicles, facial recognition, autonomous drones, healthcare applications, medical imaging, and military strategy have all used deep learning that has led to stunning technological breakthroughs.
The key to making all of this happen is data annotation. Adding metadata to datasets helps detect patterns and annotation helps models recognize objects.
The Challenges of Pixel Perfect Semantic Segmentation
Image annotation isn't without its challenges. Just think about the staggering amount of data it takes for autonomous vehicles to operate. Cameras have to detect and classify objects instantly. One of the biggest issues for self-driving vehicles is the misclassification of objects. Just a few pixels might lead to a pedestrian being mistaken for a light pole and fail to anticipate its movement.
It's supervised machine learning that trains autonomous vehicles on how to correctly identify objects. However, it's only as good as the labeled training datasets that are input. When dealing with hundreds of millions of data points, it a big task. Until recently, there were only two viable sources to pick data points out of videos.
- Pick out a few frames or images and have a small amount of data
- Annotate more frames to get more data
Utilizing too few data points can lead to inaccurate data and annotating more frames requires more resources, and is a labor-intensive, expensive, and lengthy process. Video annotation occurred frame-by-frame in a time-consuming manner. When annotating, researchers have typically used bounding boxes or polygon tools. Bounding boxes tend to include background pixels and introduce noise into the training dataset. Noise can be interpreted in different ways. In addition, poor specification documentation can lead to much open interpretation, which can create inconsistencies in the data collected.
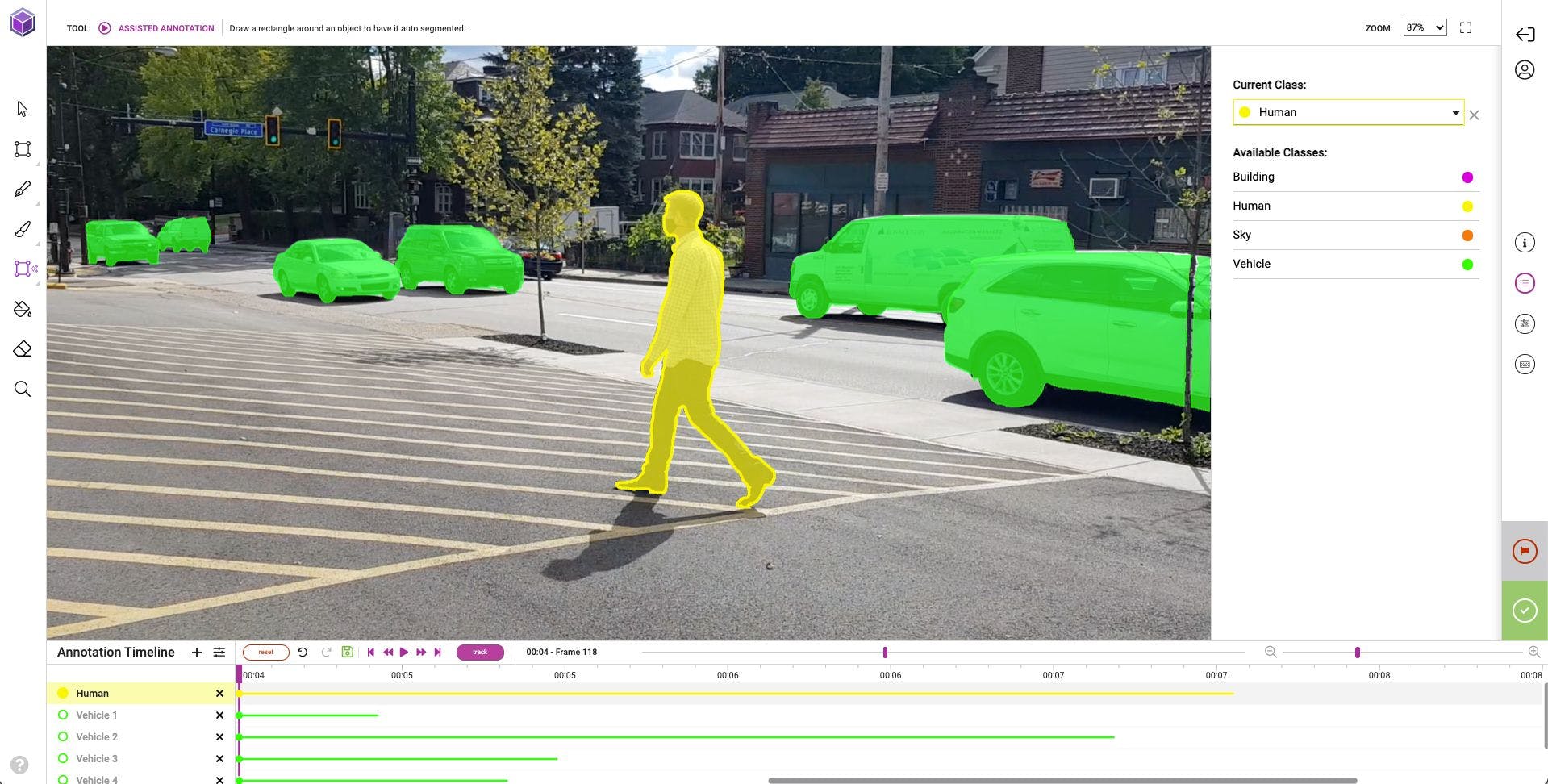
To overcome these challenges, developers have come up with the next big thing in image annotation: Pixel Perfect Semantic Segmentation.
What Is Pixel Perfect Semantic Segmentation?
Most approaches to image annotation use bounding boxes and may adapt object detectors to produce segments. Pixel Perfect Semantic Segmentation maps every pixel and assigns an object class and instance identity label to each one.
With current annotation tools, researchers have to go frame-by-frame to paint object data. For accuracy, researchers may need to identify and classify objects every few frames to provide the data needed. When you realize that a one-minute video contains several thousand frames, you can quickly see how time-intensive this task becomes.
Pixel perfect Semantic Segmentation coupled with AI-Assisted annotation tools requires fewer frames to be annotated manually. The Innotescus proprietary ML model tracks objects and interpolates positions between frames without sacrificing accuracy. Researchers whole sense encompassing 10’s of minutes of video with a single segmentation on the starting frame. This can produce a 10x increase in the labeled dataset while reducing labeling time to minutes. Over time, the algorithm becomes smarter and smarter to further reduce the number of frames needed.
It's smart enough to track movement and automate through frames. When it loses an object, such as when it leaves the screen, it knows to stop. By segmenting objects at the pixel level, the algorithm generates more data and makes tracking easier. Machine learning makes the Al smarter as more data is ingested while the Al algorithm does much of the heavy lifting to track as objects move. That leads to a dramatic reduction in the number of frames that need manual annotation without impacting the quality of the data gathered.
The Benefits of AI-Assisted Pixel Perfect Segmentation
Improved data leads to deeper insights, more efficient training, and enhanced performance. The right collaborative platform can help data scientists, data annotators, algorithm developers, and data engineers manage the entire process more easily. Benefits include:
- The elimination of repetitive labeling tasks
- Turn raw data into labeled datasets
- Reduce error space around objects
- Generate consensus labels across multiple annotations of the same image
- Eliminate data-distribution biases
- Increase the diversity of the data
- Construct training datasets efficiently with sufficient complexity for better outcomes
Pixel-wise video annotation leads to more robust data and deeper insights so that much of the trial-and-error process during model design can be alleviated with deeper understanding.
Richer Datasets Are Required
The need for mining and extracting meaningful patterns from massive datasets will only continue to grow. As technology evolves, Al and segmenting tools are changing the marketplace. The global annotation market is already $209 million and growing at a rate of 15.8% per year. As the demand for better and more data is required, this explosive growth demands better collection and annotation practices for bigger, better, and richer datasets.
About the Author: lnnotescus enables faster, more accurate image annotation for everything from basic image classification to highly accurate pixel segmentation and is currently developing advanced video annotation.
Contact the experts in annotation, computer vision, and machine learning at Innotecsus today to learn more or sign up for our beta.