









Intro
For many developers, including myself, system design interviews have always evoked internal uneasiness. Unlike the algorithmic stage, where the task is clear, and at the end of the interview, you can definitively determine whether you solved it or not, system design interviews lack a single correct answer or clear success criteria.
Here, the interviewer evaluates not only your thinking and deep understanding of various aspects of the system but also your ability to compare and assess different approaches. In this article, we will take a look at one of the most common challenges - How to design a messaging system?
What is the first step?
At first glance, the task of designing a messaging system may seem unattainable within the constraints of limited time and the scope of the task. However, before diving into the actual design process, it is important to clearly define the key objectives and requirements of the system, as well as understand the expected workload.
Functional requirements specify what the system should do, such as enabling text message exchanges, file sharing, group chat creation, and so on. On the other hand, non-functional requirements describe the system's characteristics, such as performance, scalability, reliability, security, and more.
Additionally, having an understanding of the anticipated workload is crucial. How many users are expected in the system? How frequently will they exchange messages? Which functionalities will be most actively used? Understanding the expected workload will help in selecting the appropriate architecture and technologies to ensure the desired performance and scalability of the system.
In the following sections, we will delve into the process of designing a messaging system, starting with defining requirements and workload. We will guide you through the essential steps required to create a messaging system.
Let's begin by designing a messaging system with a 1-on-1 chat format
Functional requirements
- Direct Messages
- Notifications for new messages
- Mark unread chats
Load Estimation, non-functional requirements
Some interviewers may overlook this section, but we should at least have an idea of the approximate scale of the expected load. Let's assume that the interviewer has provided us with the following figures:
-
1 billion messages per day
-
Approximately message size is 100 bytes
Based on the above figures, we can draw the following conclusions:
-
For all API calls, we will need load balancing since the approximate queries per second (QPS) is 115,000.
-
The database should be horizontally scalable as around 100 GB of data is generated and stored daily.
Where should we store the data?
The choice between SQL and NoSQL databases depends on specific requirements and project characteristics.
However, here are some reasons why NoSQL databases (such as Cassandra/MongoDB/DynamoDB) are preferred over SQL databases for this system:
-
Horizontal Scalability: NoSQL databases typically provide easy horizontal scalability, allowing for efficient processing of large volumes of data and ensuring high system availability.
(P.S. SQL databases can also be effectively scaled when certain limitations are considered.)
-
Flexibility of Data Model: In the case of a messaging system where messages can have different formats and contain various types of media files, the flexible data model of NoSQL databases can be preferred.
-
Availability: NoSQL databases are designed with high availability in mind, providing built-in replication and fault-tolerant mechanisms. This ensures that the system remains accessible and functional even in the event of node failures or network partitions.
-
Query Structure: In this case, there is no need for complex relational operations such as table joins.
-
Scale-out architecture: NoSQL databases are typically built with a distributed and decentralized architecture, enabling easy scaling by adding more nodes to the cluster. This allows for linear scalability, accommodating growing user bases and increasing data volumes.
In practice, many companies, such as Discord, prefer to use Apache Cassandra due to its advantages in horizontal scalability and efficient handling of large volumes of data records.
You can read more about how Discord utilizes Cassandra and the challenges they encountered here, and also an interesting article about how Slack utilizes MySQL can be found here.
Schema
Chat table
Cassandra uses a partition key for data sharding and a sort key within a node for sorting. In our table, we will use a composite partition key consisting of (User Id 1, User Id 2), and the sorting will be based on the messageId.
|
User Id 1: UUID |
User Id 2: UUID |
Message Id: Long |
Timestamp: Long |
Message: String |
|---|---|---|---|---|
|
… |
… |
… |
… |
… |
API
Since we want the sending and receiving of messages to work in real-time, this part of the functionality will utilize WebSocket or long-lived TCP connections.
sendMessage(senderId: UUID, recipientId: UUID, message: String)receiveNewMessages()
All other interactions will be built on HTTP requests.
getDialogs(userId: UUID, offset: Long)getHistory(userId 1: UUID, userId 2: UUID, timestamp: Long)
Architecture
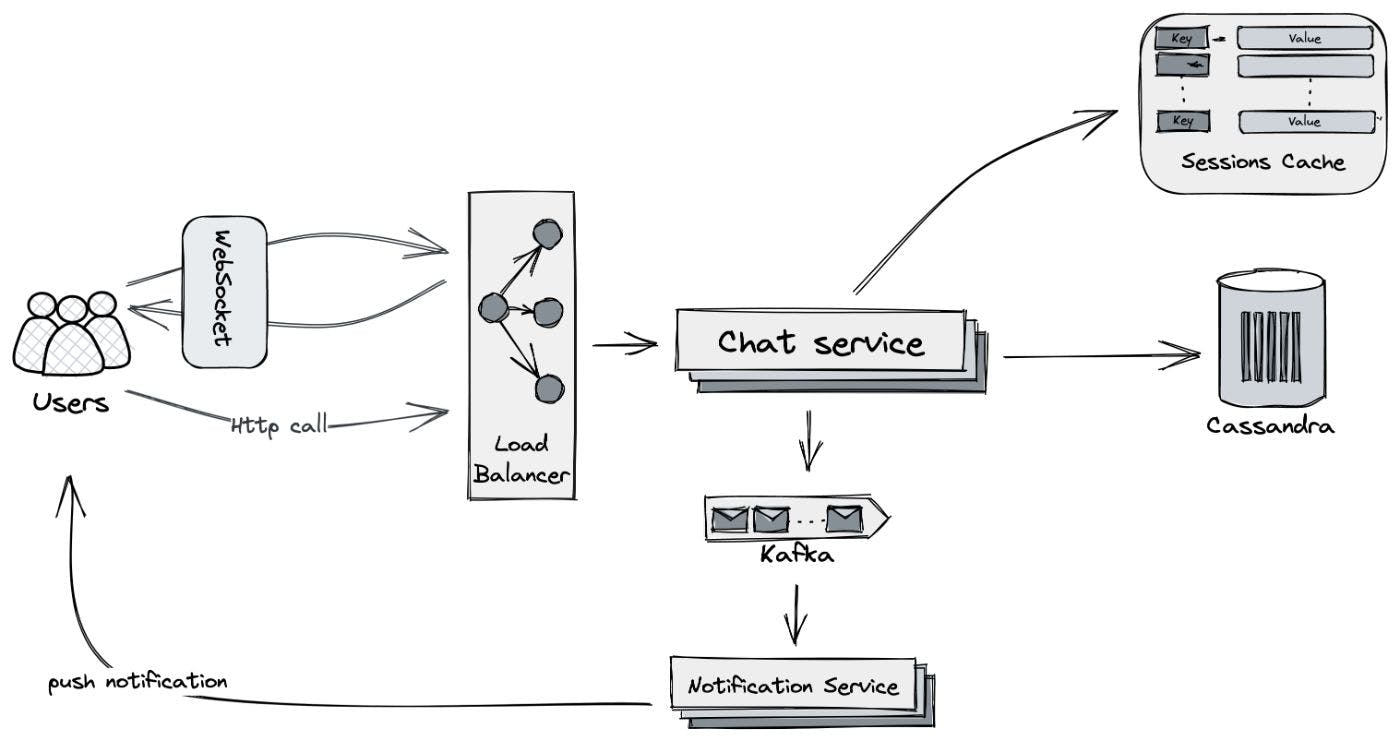
Finally, we can move on to the high-level architecture of our system.
During the initial client load, the client makes an HTTP request to retrieve dialog data and establishes a WebSocket connection. The information about the WebSocket connection is stored in the Sessions cache. All messages are processed by the Chat service, which saves them to the database. The Chat service also checks with the Sessions cache to see if there is an open connection for the recipient and on which node it resides. If there is an open connection, the message is sent to that node. If there is no open connection or an error occurs during message delivery, the message is forwarded to the Notification Service (it's important to note that notifications do not guarantee delivery).

Additional Requirements
Just now we discussed the high-level architecture for a 1-on-1 chat system, but modern applications also support group chats and many other features. Let's expand the functional requirements for our system.
What should it be able for? Functional requirements
Direct MessagesNotifications for new messagesMark unread chats- Group chats with the ability to join and leave the group.
- User status (online or offline).
Database schema
Group chat table
Partition key - Group Id, sort key - message Id
|
Group Id: UUID |
Message Id: Long |
Timestamp: Long |
Message: String |
User Id: UUID |
|---|---|---|---|---|
|
… |
… |
… |
… |
… |
We will also need a table for user-group relationships. There are two implementation options available.
Option 1
We have only one table (as shown below) where the partition key is the group Id and the sort key is the user Id. Additionally, we have a secondary index in the reverse direction.
It is worth noting that the combination of GroupId → UserId is unique, which means that using a secondary index will not significantly improve performance.
|
Group Id: UUID |
User Id: UUID |
|---|---|
|
… |
… |
Option 2
We will create two tables. One table will use Group Id as the partition key and User Id as the sort key, and it will be used for broadcasting messages from a group. The second table will have User Id as the partition key and Group Id as the sort key, and it will be used to determine the groups a user belongs to.
|
Group Id: UUID (partition key) |
User Id: UUID (sort key) |
|---|---|
|
… |
… |
|
Group Id: UUID (sort key) |
User Id: UUID (partition key) |
|---|---|
|
… |
… |
When using this approach, you need to ensure data consistency in both tables, which can be achieved by implementing distributed transactions when making changes.
API
The following endpoints are added to the existing endpoints we already have:
createGroup(userId: UUID, name: String, members: List<UUID>)- Creates a new group with the provided details and returns the Group Id.joinGroup(userId: UUID, groupId: UUID)- Allows a user to join a specific group by providing the Group Id.leaveGroup(userId: UUID, groupId: UUID)- Allows a user to leave a specific group by providing the Group Id.getGroupMembers(groupId: UUID)- Retrieves the list of members belonging to a specific group by providing the Group Id.getAllGroups(userId: UUID)- Retrieves the list of groups in which a user is a member by providing the User Id.getGroupMessages(groupId: UUID, timestamp: Long)- Retrieves the messages sent in a specific group by providing the Group Id.
Architecture
While the high-level architecture remains unchanged, the handling of group messages will differ slightly from handling direct messages. When a user sends a message to a group, it should be delivered to all members of that group. Below is a diagram illustrating this process.

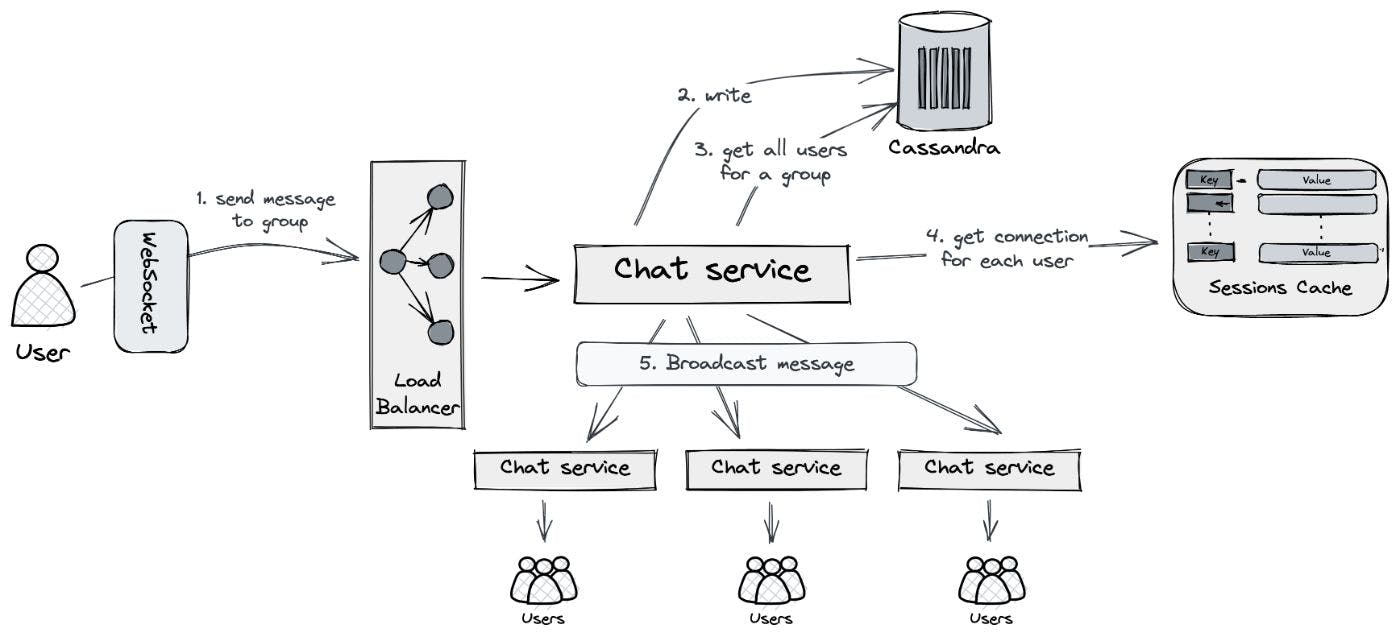
This diagram is sufficient for the initial understanding, but there are a few key points to consider.
-
In the above diagram, we use synchronous HTTP requests to transfer messages from one chat service to another. As a result, there may be a potential issue with the order in which these messages are received by the users. Additionally, in cases of excessive external or internal load, the chat service may start throttling. This means the service will limit the rate at which it processes requests or sends messages to cope with the increased load and prevent server overload.
To address the issue of message order, it can be handled on the client side. If a client receives a message with a messageId greater than the last message in its local history, it should update its history accordingly. By comparing the messageId of incoming messages with the local history, the client can ensure that the messages are displayed in the correct order and prevent any inconsistencies in the message sequence.
-
In the current implementation, we send a message to all users in a group immediately, without considering the group size and activity. This results in each incoming message being transformed into multiple outgoing messages, where the number of outgoing messages equals the group size. This can lead to a significant increase in internal interactions within the system for large and active groups, negatively impacting system performance.
To address this issue, we can employ different approaches depending on the size of the group. For small groups, we can maintain the current approach of sending messages to all participants. However, for large and active groups, we can modify the strategy and update the message history using regular client requests. This way, we can reduce the system load, avoid unnecessary internal interactions, and improve overall performance.
Implementing this strategy requires careful consideration of factors such as polling frequency, handling potential conflicts, and managing the synchronization process effectively. This approach for larger and more active groups, we can mitigate the performance impact and provide a more efficient messaging experience.
Summary
In this article, we have developed a high-level architecture for a messaging system, defined APIs, and discussed the database structure. We have also addressed several significant trade-offs. In system design interviews, there is no perfect answer. Each solution has its limitations, and our task is to assess them and choose the simplest solution that meets all the requirements.
Throughout the design process, it is crucial to consider factors such as scalability, performance, data consistency, fault tolerance, and ease of implementation. By evaluating these trade-offs and making informed decisions, we can create a robust and efficient messaging system.
It's important to note that system design is an iterative process, and as the system evolves and user requirements change, adjustments and optimizations may be necessary. The key is to continually evaluate the system's performance, gather user feedback, and make improvements accordingly.












