
Working on a data science project is almost always equivalent to an amazing clutter in the working directory. Data scientists would most likely have the following materials dumped in their project working directory:
Python/R scriptsData sets
— includes journal articles, slides, other documentsReference materialsNotebooksNotesScala sources (if using spark)
— usually, a source of inspiration, methodology or case studiesCloned repository of other projects relevant to the current work
for data transfer, data clean-up or even for runners.sh to submit jobs on a cluster. I always have a runner.sh that contains yarn settings for spark-submitOther scripts- Other stuffs, thought to be useful but oftentimes are not.
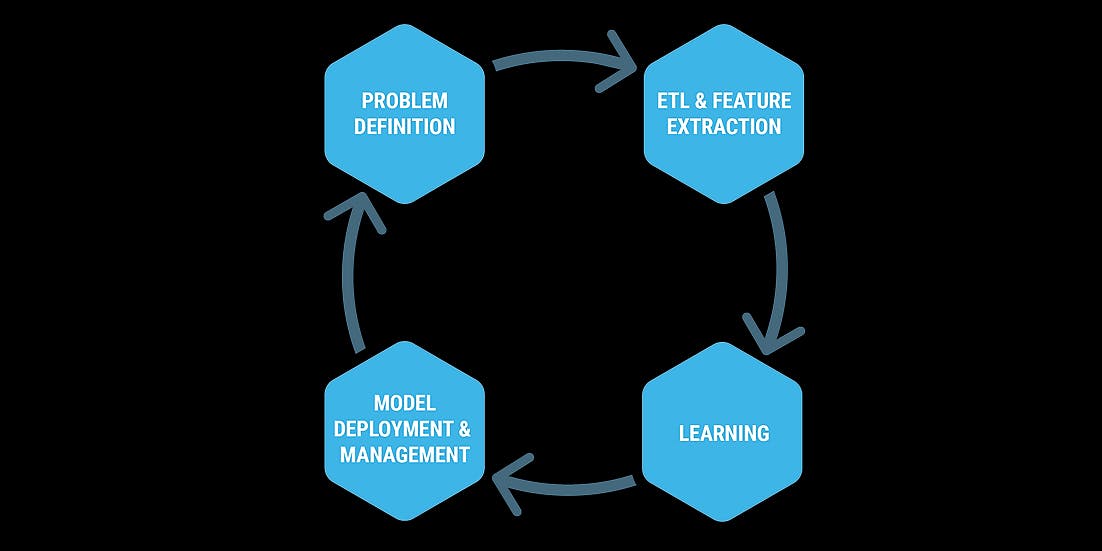
Given a project, Data Scientists follows these steps to tackle it;
Workflow of data science work
Requirements gatheringETL data from sources using python, R or scala
- perform descriptive statistics on data to validate whether it reflects business facts. This takes sometime, even on collaborative environment where business and data scientists are working closely. In addition, data calibration is also needed to further verify business facts.Data calibration
- with data validated and calibrated, A Data Scientist can now start working on generating insights - producing notebooks, scripts or scala jars. Notes, journal articles and other references will add to the clutter in the working directory.Data Science and Insights Generation
- reports for business are consolidated in a presentation from outputs of various visualization tools (png files, tableau workbooks)Visualization and Reports creation
- if the study is to be operationalized, prototypes are built as Data Engineers guide.PySpark or Spark jobs sources for operationalization- Different activities necessary for the above steps, inevitably clutters the project directory.
De-clutter working directories
This is the directory heirarchy I have for every data science project:
ansible playbooks are created to automated repeatitive tasksansible-playbooks:
all data sets (toy, final, intermediate aggregates, etc). I would usually have to sub directories, for (1) datasets generated in the cluster (we're running on a spark environment), (2) locally generateddata:
with subdirectories for notebooks running on the cluster and locallyNotebooks:
pdfs, journal articles, referencesrepo: for all python, scala and R scripts, organized as repo/src/python/main/R, repo/src/python/lib (for various utilities), repo/src/main (for scala codes).References:
is organized like this to allow easy compilation of scala codes using maven build.repo
all reports goes hereReports:


Version Control
I use git to manage versions and changes. A .gitignore file which ignores everything except for the main directories above keeps accidental inclusion of files not intended for commit to the remote repo.
Here’s my .gitignore file.
/*
**/.DS_Store
**/.ipynb_checkpoints
**/*.log
repo/src/python/lib/
!/resources
!/notebooks
!/repo
!/ansible
!/data
!/.gitignoreTools
- Ansible: I am using ansible for automating repeative scp and spark submit on a cluster client. For simpler tasks, this may not be neccessary. Read about it here.'
- Git: for version control
- Sublime: for text editor
- Anaconda3: as python distribution with jupyter-notebook
- Markdown cheatsheet: for any documentation using sublime.
- I’ve recently added, AirBnB's knowledge-Repo for knowledge-sharing with collegues. You can read more about it here.
End Notes
How are you de-cluttering your working directory? Get the workspace template here. Feel free to comment and improve.
References:
Banner Image source: https://hortonworks.com/products/partner-solutions/data-science/