










Table of Links
-
Domain and Task
-
Related Work
3.1. Text mining and NLP research overview
3.2. Text mining and NLP in industry use
-
4.6. XML parsing, data joining, and risk indices development
-
Experiment and Demonstration
-
Discussion
6.1. The ‘industry’ focus of the project
6.2. Data heterogeneity, multilingual and multi-task nature
2.2. Task definition
2.2. Task definition Relating to the project’s ultimate goal of enabling the dynamic creation of ‘supplier risk profiles’, we envisage a database scheme that is partially (for reasons of both proprietary information and simplicity) depicted in Figure 4 showing entities (rounded boxes), their attributes (dashed boxes) and relationships (lines). Briefly, we hope to create a record for each contract award that has one buyer and one supplier, with associated lots (one or multiple) and item information. We store certain attributes of the buyer, supplier, contract award, lots and items, such that we can run queries to fetch ‘supplier centric’ award information like the range of products (based on lot items) they have supplied, the monetary value and quantities for different kinds of products, their buyers, and covered geographical regions (buyer country). Previously we mentioned that one award XML may mention multiple contracts with multiple suppliers. In practice, we ‘flatten’ data extracted from the award XML into multiple contract award records.
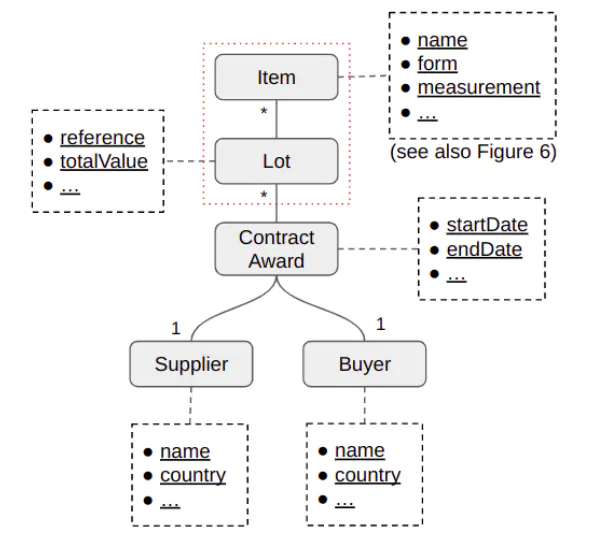
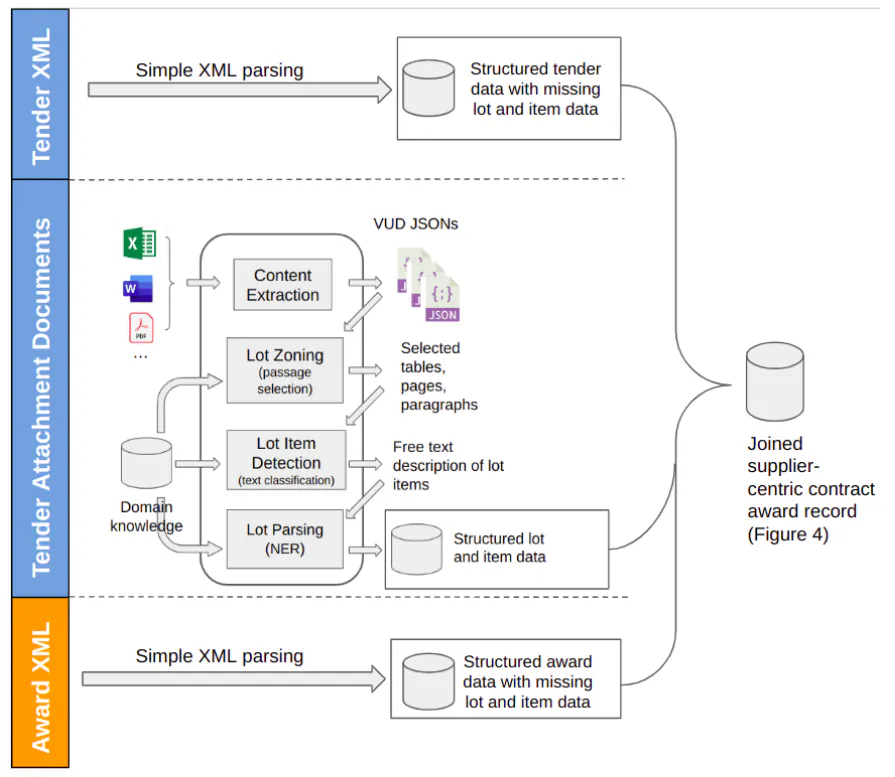
As already mentioned, much of the information captured by this schema is already in (semi-)structured format available from the tender and/or award XMLs. These can be easily extracted through XML parsing, although some light-weight data cleansing and linking may be needed (e.g., extracting the country from a buyer/supplier address, or matching buyer names from the tender and award XMLs). These tasks are relatively straightforward and will not be the focus of this article. Instead, the real challenge is extracting and populating the lot and item information (indicated in red dotted box) that is often missing in both the tender and award XMLs. Therefore, our tasks can be defined as it is shown in Figure 5 - given a tender XML, its associated award XML, and the associated tender attachments, we aim to:
1. Extract the structured lot and item information often missing in tender and award XMLs (filling the schema highlighted in the red dotted box in Figure 4; also the middle lane in Figure 5):
a. From the tender attachments, identify the relevant documents, and the relevant content areas (i.e., tables, lists, paragraphs) that contain information about the lots (lot zoning);
b. From the identified content areas, detect content elements (e.g., sentences) associated with lot items (lot item detection);
c. From the detected lot items, parse the lot and item descriptions into a structured representation, identifying attributes such as the lot reference, name of the items, measurement units, etc (lot parsing). As an example, Figure 6 shows how we want to extract structured lot and item information from the example in Figure 3.
2. Extract the structured supplier, buyer, and contract award data from the tender and award XMLs (filling other parts of the schema shown in Figure 4; also the upper and bottom lanes in Figure 5).
3. Join the information extracted from 1 and 2 above to form supplier-centric contract records and populate the database.
4. Develop supplier risk indices using the populated database and a platform for exploring these indices.
For the scope of this article, we will focus on 1), briefly cover 2) and 3) as they are more straightforward and completed outside the scope of this project, and skip 4).



Authors:
(1) Ziqi Zhang*, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(2) Tomas Jasaitis, Vamstar Ltd., London ([email protected]);
(3) Richard Freeman, Vamstar Ltd., London ([email protected]);
(4) Rowida Alfrjani, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]);
(5) Adam Funk, Information School, the University of Sheffield, Regent Court, Sheffield, UKS1 4DP ([email protected]).
This paper is











