












Table of Links
2 COCOGEN: Representing Commonsense structures with code and 2.1 Converting (T,G) into Python code
2.2 Few-shot prompting for generating G
3 Evaluation and 3.1 Experimental setup
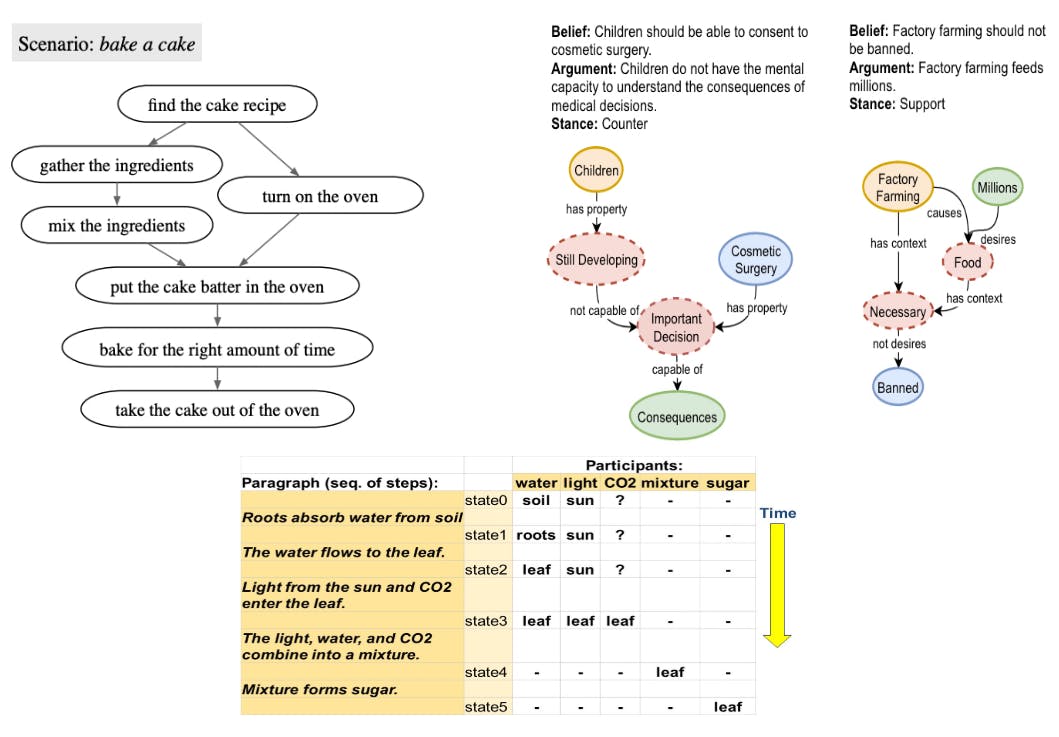
3.2 Script generation: PROSCRIPT
3.3 Entity state tracking: PROPARA
3.4 Argument graph generation: EXPLAGRAPHS
6 Conclusion, Acknowledgments, Limitations, and References
A Few-shot models size estimates
G Designing Python class for a structured task
G Designing Python class for a structured task
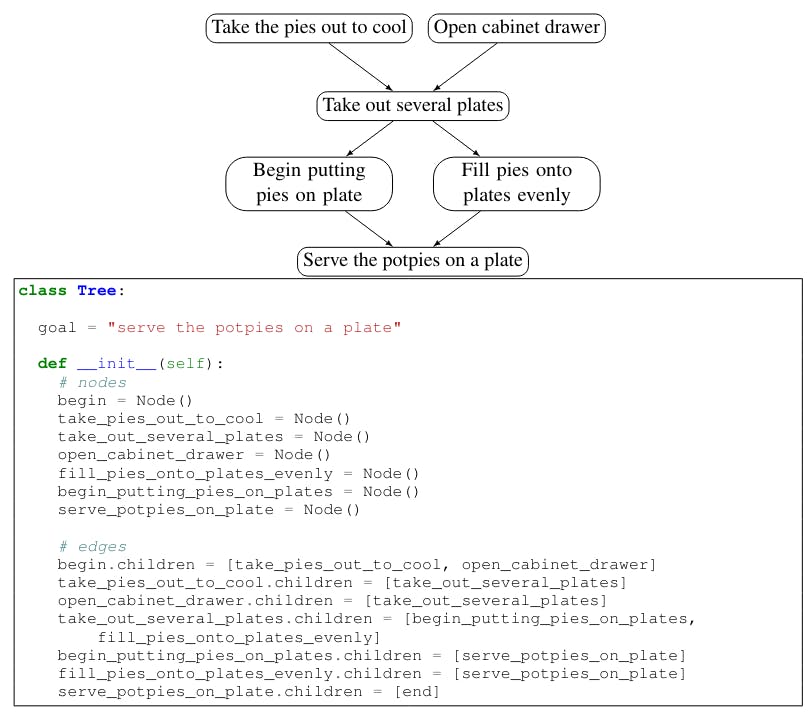
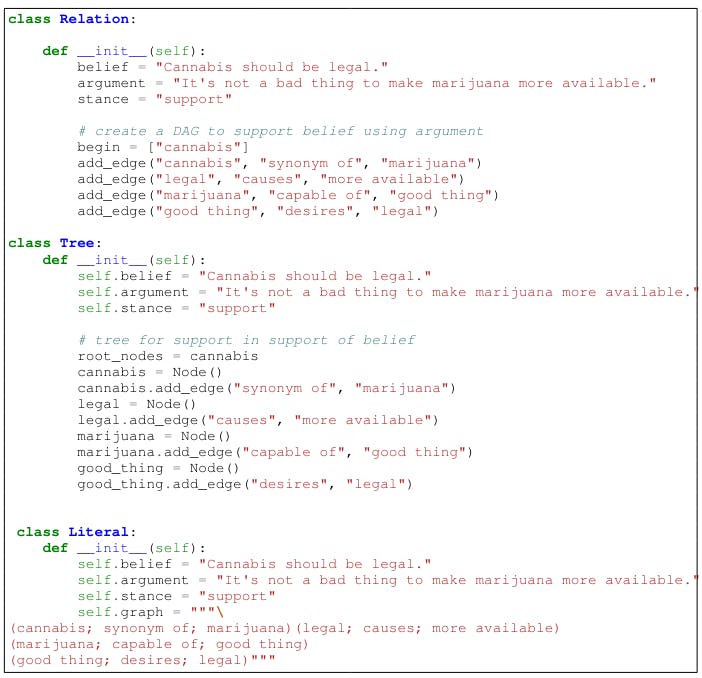
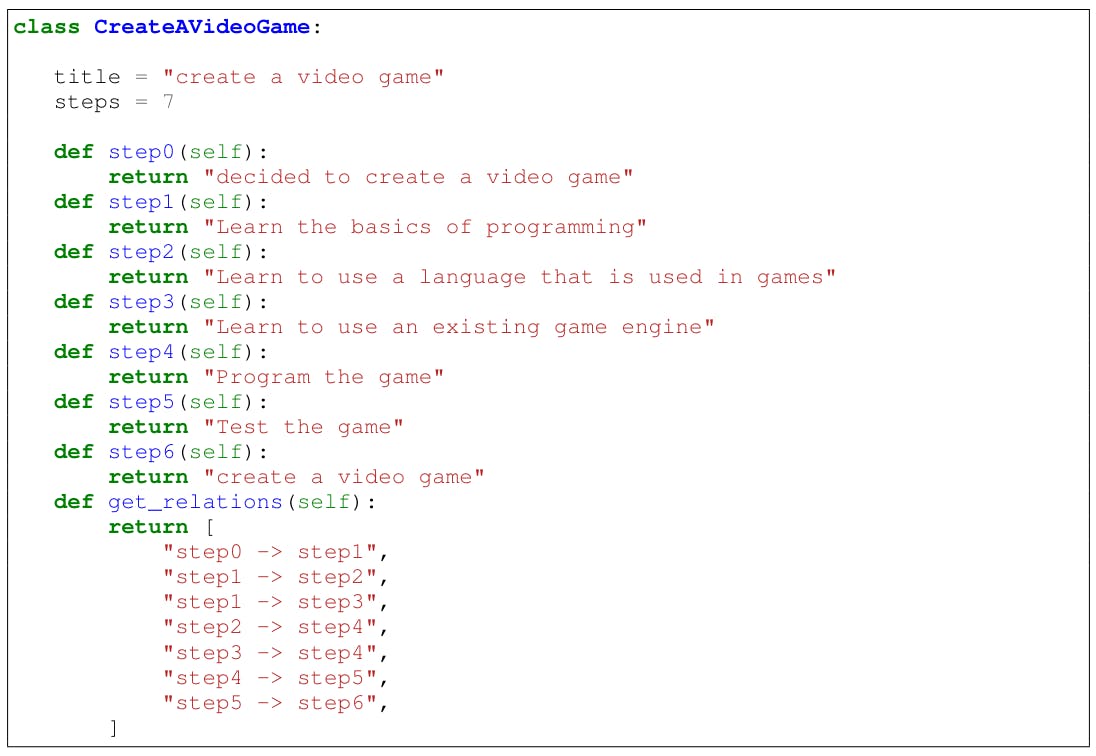
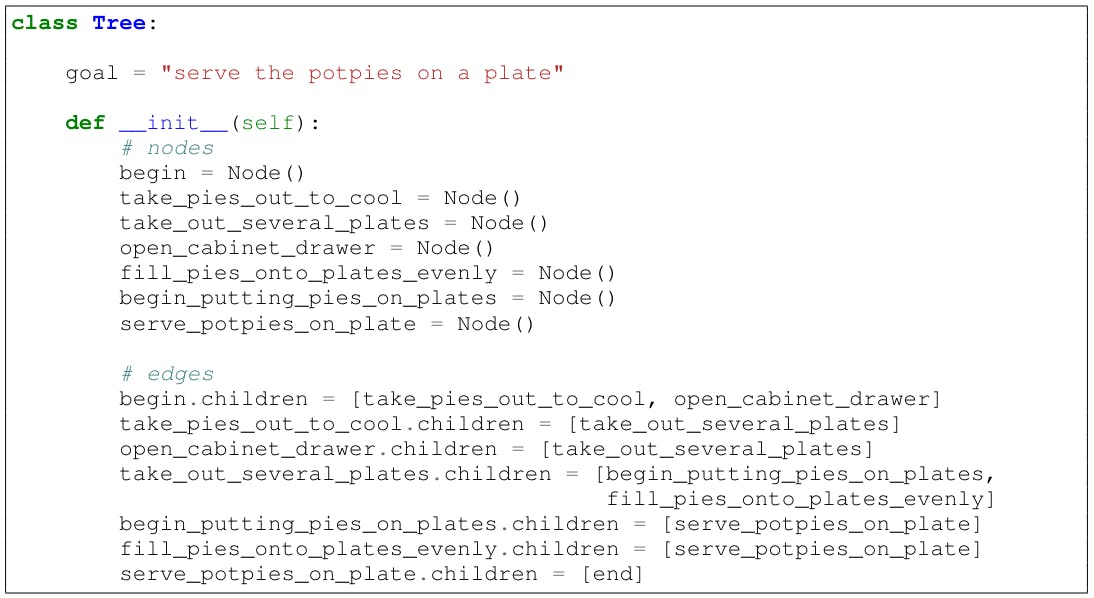
Figure 7 shows three different designs for Explagraphs. For PROSCRIPT, the various formats include representing proscript as a Networkx[8] class (8), DOT-like class 9, and as a Tree (10).
H Impact of Model size
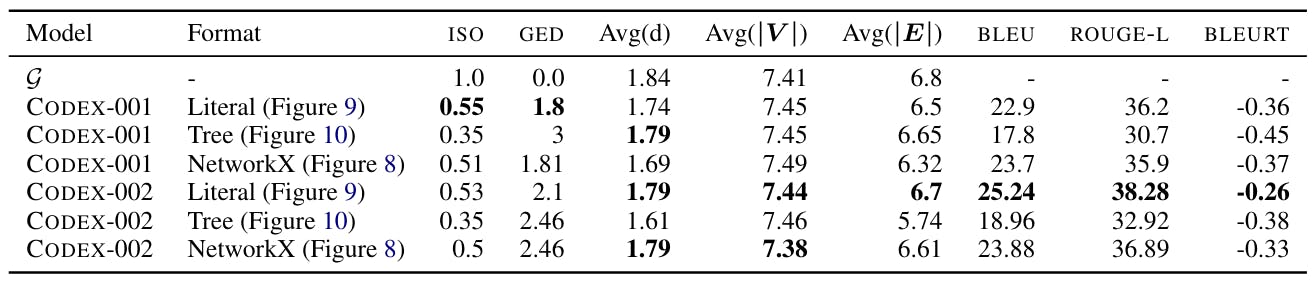
The CODEX model released by OpenAI is available in two versions[9]: code-davinci-001 and code-davinci-002. While the exact sizes of the models are unknown because of their proprietary nature, OpenAI API states that code-davinci-002 is the Most capable Codex model Tables 16 and ?? compares COCOGEN +code-davinci-001 with COCOGEN +code-davinci-002. Note that both code-davinci-001 and code-davinci-002 can fit 4000 tokens, so the number of in-context examples was identical for the two settings. The results show that for identical prompts, COCOGEN +code-davinci-002 vastly outperforms COCOGEN +code-davinci-001, showing the importance of having a better underlying code generation model.




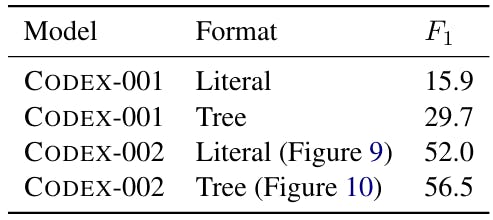
Model size vs. sensitivity to the prompt In Table 14 shows the performance of CODEX-001 (smaller) and CODEX-002 (larger, also see Appendix A) on identical prompts. Our experiments show that as model size increases, the sensitivity of the model on the prompt design might get progressively easier.
I Variation in prompts
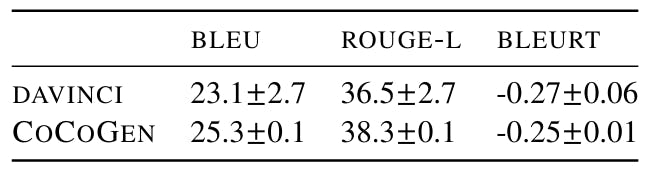
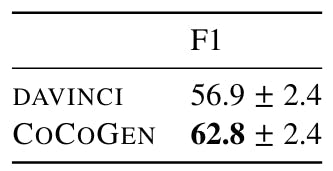
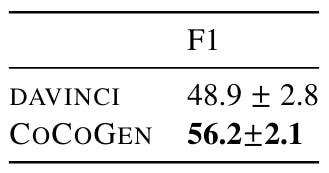
We run each experiment with 4 different random seeds, where the random seeds decide the order of examples in the prompt. We find minimal variance between runs using different fixed prompts between 3 runs. Further, as shown in the Table 18, 19, 20, and 21, all improvements of COCOGEN over DAVINCI are statistically (p-value < 0.001).














This paper is available on arxiv under CC BY 4.0 DEED license.
[9] as of June 2022
Authors:
(1) Aman Madaan, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(2) Shuyan Zhou, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(3) Uri Alon, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(4) Yiming Yang, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]);
(5) Graham Neubig, Language Technologies Institute, Carnegie Mellon University, USA ([email protected]).












