








Artificial Intelligence (AI) technology is too far evolved to still be relying on basic, word cloud analysis for your survey data.
Historically, user experience researchers have used word cloud visualisation to view the most repeated words found in the responses to text entry survey questions.
You would think that these results would give you the information necessary to take action to improve your product.
But they don’t.
Without the help of thematic clustering (which goes several steps beyond word clouds) —this is a task that can take too much time for a busy user researcher with daily deadlines.
You might end up doing this by hand or manually in an excel spreadsheet which adds yet another fragmented tool to remember to check when gathering all your product data.
And one thing is non-negotiable: you can’t afford to skip this step.
If you do; you can end up compromising the product quality for speed by making decisions based on assumptions rather than well-researched and analyzed data.
Why Basic Word Clouds Fall Short
As we mentioned, basic NLP falls short. To understand why thematic clustering is important, you must first understand where basic NLP-like word clouds fall short.
Basic NLP methods are based on:
- Word frequency counts.
- String matching.
- Keyword extraction.
- Topic extraction and modeling.
They depend on words being clearly stated so that common themes can be identified. For instance, here are responses from three customers to a survey question.
“The subscription fee is a bit steep.”
“The cost to change vendors might be too much for us at the moment.”
“You should include a pricing plan based on usage.”
While NLP would be able to surface the primary concern here is cost, it would be limited in providing a deeper understanding of the intent from each response because the words associated with cost are not the same.
As a product manager, you’re relying on this automation tool to connect the dots between responses so that you know what decision to make for your product next. But with limited word association, basic NLP eliminates a key technique within its algorithm called string matching, which connects two words with similar meaning or intent, even if they are not the same.
Because none of the words associated with cost are the same, for example, “a bit steep” or “pricing plan based on usage”, the basic NLP methods wouldn’t allow you to easily identify the similarities.
The Next Generation of Response Analysis: Thematic Clustering
By leveraging an NLP model with thematic clustering, you can more clearly see the themes that arise from survey responses, and can:
- More clearly prioritize product issues (How many users is this actually impacting)?
- Learn the emotional sentiments towards specific issues (Instead of just seeing “price” you can understand, does someone think the price is too high or too low?).
- See the specific intent for change users are advocating for (One word in a word cloud is rarely enough to understand what users actually want).
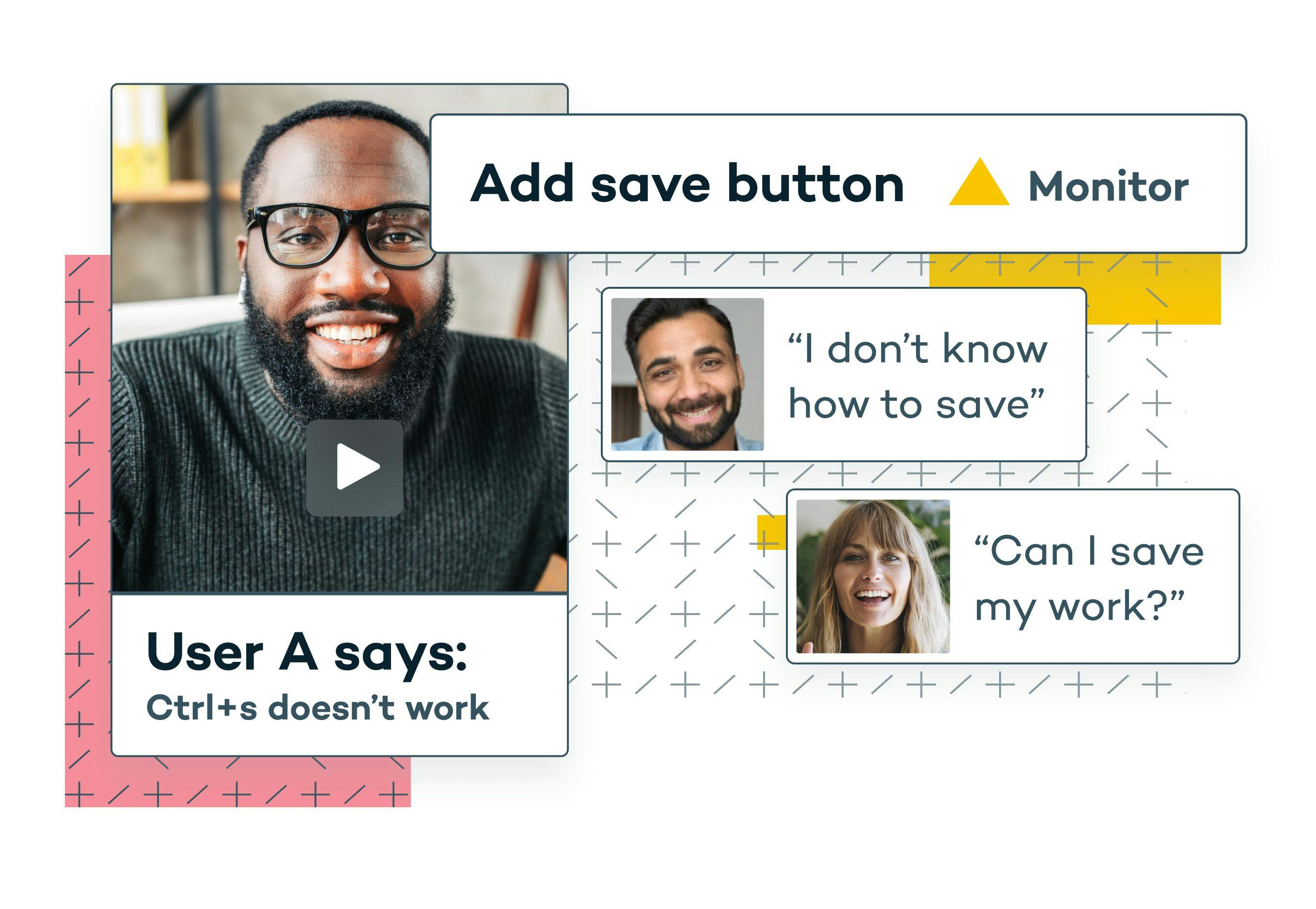
Sprig’s machine learning algorithm is designed to replicate the efforts of expert human researchers. It isn’t based on the basic NLP methods we described earlier because our aim is to go beyond one-note topics and keyword analysis.


When expert researchers are conducting an interview or observing a focus group, they’re able to spot the quick micro-expressions of human interaction. Some people might think it wouldn’t be possible to detect those same nuances through digital interactions. But not only is our machine learning tool trained to detect those same microexpressions; it also has the ability to group them based on themes, and provide recommendations for how to action on the results (eg. monitor or take action).
Rather than focus exclusively on similar topics from open survey results, we use a multi-axis approach through which we sort data based on relevant criteria. It’s typically a three-way split based on the following groups of information:
-
Intent
-
Topic
-
Emotional response/sentiment


The Customer’s Intent Must Match The Theme
One thing lies at the heart of user research—understanding the reasons behind a customer’s purchase decision (aka customer intent). Customer intent can be expressed in many ways, which makes it difficult to be defined by a single event or response. Two respondents can have the same intent but use a completely different language.
We use machine learning to ensure that all surfaced themes are actionable. To accomplish that, they must align with the intent communicated in the user responses). Traditional product research strategies, such as keyword extraction, don’t always ensure this alignment between customer intent and theme.
Correctly Identifying Topic Groupings Increases Relevance
Topic groupings help you match responses that express the same customer intent. If the groupings are inaccurate, your data is flawed. Good decisions are based on accurate data, and that’s essential because decisions made on flawed data can be detrimental to the product’s success.
Objectively Assess Emotional Responses
Your customers’ sentiments towards your product are directly related to the emotions that influence their purchase decisions. The issue is that humans often assess emotional responses subjectively. Even the most skilled researcher can fall into confirmation bias from time to time.
Our advanced machine learning techniques solve this challenge. By splitting the problem into separate portions - topic vs intent, global definitions vs domain-specific attributes - we’re able to identify an emotional response based on the urgency of the theme’s responses.
This evolves to be a more reliable way to judge which customer concern topic requires immediate action upon first glance.
Apply Thematic Clustering to Multiple Response Types like Text, Voice, and Video

Machine learning has expanded what’s possible for user research. Thematic analysis isn’t just applicable to text-entry questions anymore.
At Sprig, we help product teams collect and analyze responses using thematic clustering across text, video, and voice, so teams can put the analysis to use while:
-
Conducting asynchronous discovery interviews
-
Obtaining feedback from concept and prototypes
-
Or running high-volume micro-surveys to solve discrete product issues such as onboarding conversion issues or improving existing features with poor performance.
Ready to ditch the word clouds?
The standard approach to user research has got to change. Old ways of gathering customer insights relied on in-person conversations, outdated NLP algorithms, and therefore too much manual human analysis.
Not anymore.
Sprig has developed an all-in-one product research platform that leverages machine learning to analyze all types of response data quicker, more accurately, and at scale.
So, are you ready to take it for a spin?












