










Genetic Algorithms , also referred to as simply “GA”, are algorithms inspired in Charles Darwin’s Natural Selection theory that aims to find optimal solutions for problems we don’t know much about. For example: How to find a given function maximum or minimum, when you cannot derivate it? It is based on three concepts: selection, reproduction, and mutation. We generate a random set of individuals, select the best ones, cross them over and finally, slightly mutate the result - over and over again until we find an acceptable solution. You can check some comparisons on other search methods on Goldberg's book.
Let’s check how to write a simple implementation of genetic algorithm using Python!
The problem we will try to solve here is to find the maximum of a 3D function similar to a hat. It is defined as f(x, y) = sin(sqrt(x^2 + y^2)). We will limit our problem to the boundaries of 4 ≥ x ≥ -4 and 4 ≥ y ≥ -4.

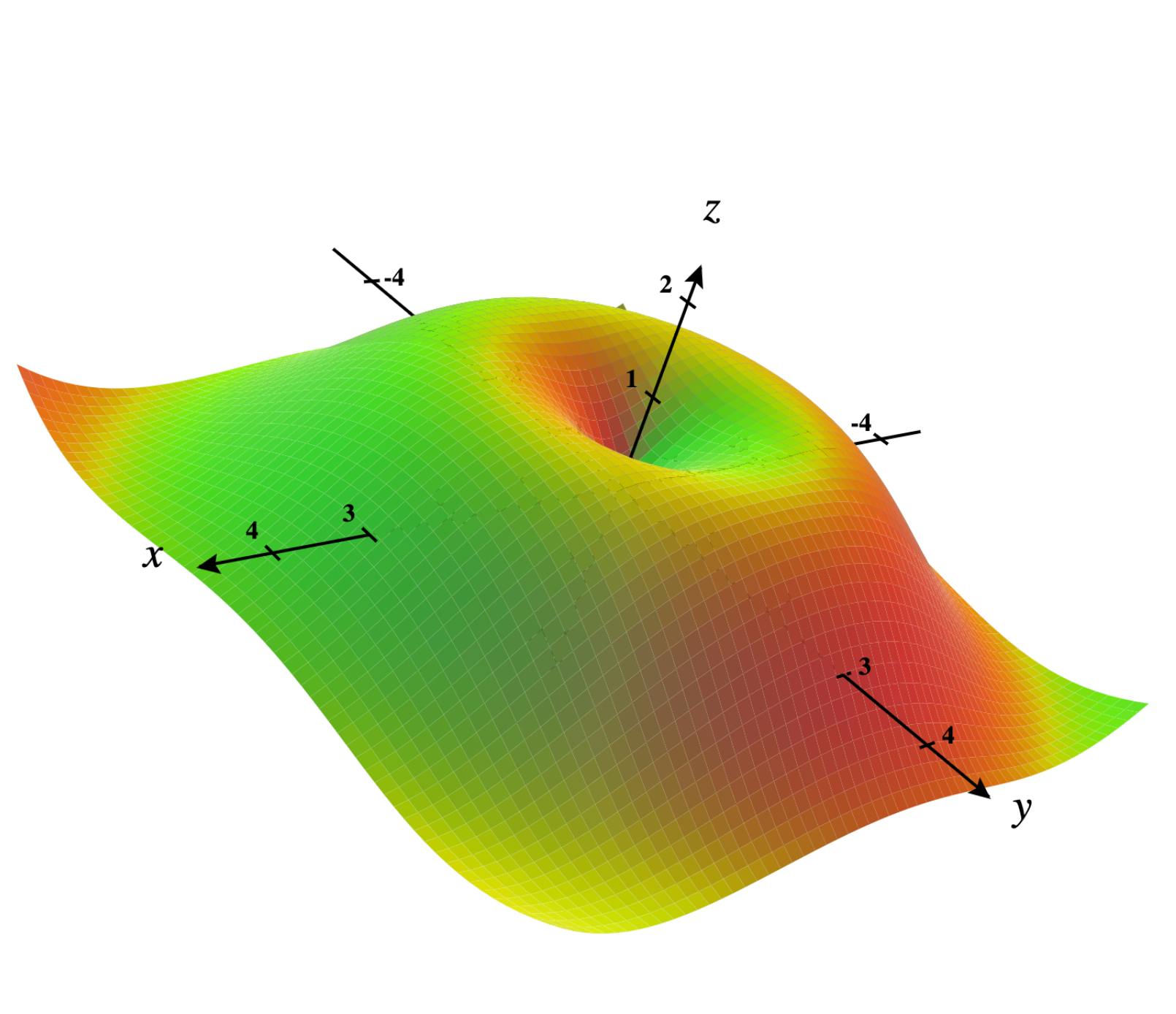
(Plot of the function between our defined boundaries, created with CalcPlot3D)
The first step is to generate our initial population. A population or generation is our current set of possible solutions, called individuals. We will iterate over several generations improving it until we find an acceptable solution. The first generation is randomly generated.
import random
def generate_population(size, x_boundaries, y_boundaries):
lower_x_boundary, upper_x_boundary = x_boundaries
lower_y_boundary, upper_y_boundary = y_boundaries
population = []
for i in range(size):
individual = {
"x": random.uniform(lower_x_boundary, upper_x_boundary),
"y": random.uniform(lower_y_boundary, upper_y_boundary),
}
population.append(individual)
return populationOur genesis function expects three arguments: the number of individuals the population should have, a tuple indicating the boundaries on the x-axis and a tuple indicating the boundaries on the y-axis, so our individuals fit randomly these boundaries.
Moving on, let’s define our fitness function. It will be our evaluator, which will express how better or worse an individual is from each other. The individuals with the best fitness should be preserved and reproduce while the worst ones should fall — just like in nature. In our case, how we want to find our function maximum, we can simply apply our objective function to an individual and the biggest numbers will be the biggest fitness as well. If we'd want to find the minimum, fitness could be expressed as the result of the function times -1, so smaller values become larger fitness.
import math
def apply_function(individual):
x = individual["x"]
y = individual["y"]
return math.sin(math.sqrt(x ** 2 + y ** 2))Since we have a population generator and a fitness evaluator, we can start reproducing our individuals to achieve the next generation. We will do this until we find an acceptable solution. There are several stop criteria, a largely used one is "n generations with stale fitness", but we will use a simpler one, which is simply n generations - we will use 100. Up to now our entry function looks like:
generations = 100
population = generate_population(size=10, x_boundaries=(-4, 4), y_boundaries=(-4, 4))
i = 1
while True:
print(f"🧬 GENERATION {i}")
for individual in population:
print(individual)
if i == generations:
break
i += 1
# Make next generation...To select the individuals to reproduce we will use a widely adopted method called roulette wheel which consists of dividing a circle in portions like a pie chart, where each individual has a portion proportional to its fitness, and then spinning it. This way we assure best individuals have a better chance of being selected, while the worst ones still have a chance, although it is minor.
def choice_by_roulette(sorted_population, fitness_sum):
offset = 0
normalized_fitness_sum = fitness_sum
lowest_fitness = apply_function(sorted_population[0])
if lowest_fitness < 0:
offset = -lowest_fitness
normalized_fitness_sum += offset * len(sorted_population)
draw = random.uniform(0, 1)
accumulated = 0
for individual in sorted_population:
fitness = apply_function(individual) + offset
probability = fitness / normalized_fitness_sum
accumulated += probability
if draw <= accumulated:
return individualTo illustrate our method, let's say we have four individuals: A, B, C and D with fitness 0, 50, 200 and 250 respectively. The sum of the total fitness is 500, so each one will have a fitness / total_fitness chance of being selected: 0%, 10%, 40%, 50%. We select a random number between 0 and 1 and then verify which individual is in the selected portion: A [0, 0], B (0, 0.1], C (0.1, 0.5], D (0.5, 1].
Since our scenario can have negative fitness, first we have to normalize our individuals by picking the lowest fitness, multiplying by -1 and then adding it to all of them (for example, if we have two individuals with fitness -10 and 5 respectively we add 10 to both becoming 0 and 15). We also expect the population argument to be sorted ascending by fitness so it's easier to get the worst and best individuals.


Let's then populate the next generation. It should have the same length of the first one, so we will iterate 10 times selecting two individuals each using our roulette and then crossing them. The resultant individual will receive a minor perturbation (mutation) so we don't stick to comfort zone and look out for even better solutions than what we have so far.
There are several crossover techniques for real numbers: for example, we could take x of the individual A and y of the individual B, we could take the geometric mean of each or, the simplest one, take the arithmetic mean of each. If we were dealing with binary data, the most common technique is to pick a part of the bit string of A and a part of bit string of B. For simplicity reasons, let's use the arithmetic mean.
For the mutation there are plenty options too - we will simply sum a small random number between a fixed interval. This interval is the mutation rate and can be fine tuned accordingly, let's use [-0.05, 0.05]. For larger search spaces you can choose larger intervals and diminish it from generation to generation. When dealing with binary data you can simply flip randomly selected bits of the individual string.
def sort_population_by_fitness(population):
return sorted(population, key=apply_function)
def crossover(individual_a, individual_b):
xa = individual_a["x"]
ya = individual_a["y"]
xb = individual_b["x"]
yb = individual_b["y"]
return {"x": (xa + xb) / 2, "y": (ya + yb) / 2}
def mutate(individual):
next_x = individual["x"] + random.uniform(-0.05, 0.05)
next_y = individual["y"] + random.uniform(-0.05, 0.05)
lower_boundary, upper_boundary = (-4, 4)
# Guarantee we keep inside boundaries
next_x = min(max(next_x, lower_boundary), upper_boundary)
next_y = min(max(next_y, lower_boundary), upper_boundary)
return {"x": next_x, "y": next_y}
def make_next_generation(previous_population):
next_generation = []
sorted_by_fitness_population = sort_population_by_fitness(previous_population)
population_size = len(previous_population)
fitness_sum = sum(apply_function(individual) for individual in population)
for i in range(population_size):
first_choice = choice_by_roulette(sorted_by_fitness_population, fitness_sum)
second_choice = choice_by_roulette(sorted_by_fitness_population, fitness_sum)
individual = crossover(first_choice, second_choice)
individual = mutate(individual)
next_generation.append(individual)
return next_generationSo this is it! We now have all the three steps of a GA: selection, crossover and mutation. Our main method is then simply like that:
generations = 100
population = generate_population(size=10, x_boundaries=(-4, 4), y_boundaries=(-4, 4))
i = 1
while True:
print(f"🧬 GENERATION {i}")
for individual in population:
print(individual, apply_function(individual))
if i == generations:
break
i += 1
population = make_next_generation(population)
best_individual = sort_population_by_fitness(population)[-1]
print("\n🔬 FINAL RESULT")
print(best_individual, apply_function(best_individual))The
best_individual
🧬 GENERATION 100
{'x': -1.0665224807251312, 'y': -1.445963268888755} 0.9745828000809058
{'x': -1.0753606354537244, 'y': -1.4293367491155182} 0.976355423070003
{'x': -1.0580786664161246, 'y': -1.3693549033564183} 0.9872729309456848
{'x': -1.093601208942564, 'y': -1.383292089777704} 0.9815156357267611
{'x': -1.0464963866796362, 'y': -1.3461172606906064} 0.9910018621648693
{'x': -0.987226479369966, 'y': -1.4569537217049857} 0.9821687265560713
{'x': -1.0501568673329658, 'y': -1.430577408679398} 0.9792937786319258
{'x': -1.0291192465186982, 'y': -1.4289167102720242} 0.9819781801342095
{'x': -1.098502968808768, 'y': -1.3738230550364259} 0.9823409690311633
{'x': -1.091317403073779, 'y': -1.4256574643591997} 0.9748817266026281
🔬 FINAL RESULT
{'x': -1.0464963866796362, 'y': -1.3461172606906064} 0.9910018621648693Our final result was very close to one of the possible solutions (this function has multiple maximums inside our boundaries, which is 1.0 as you can see on the plot at the beginning). Note that we used the less sophisticated possible techniques, so this result is somehow expected - it is a start point to fine tune until we are able to find better solutions with less generations.
This was a very introductory hands on article on Genetic Algorithms using Python. If you liked it, you will certainly want to know more about all the possible improvements you can do on it and applications you can use it. I highly recommend the reading of "Genetic algorithms in search, optimization, and machine learning" book, mentioned at the beginning.












