






For free? Of course, no one is going to take money from you for "Googling"... But what if you want to automate the process? That's where the problems lie, and where the business opportunities are.
Like in the last article, I went to the Internet, this time to get the files from Google. The story repeated itself and I realized that I had the code for this somewhere in the stash. I was happy to start studying it and realized that it wasn't much fun, and it was easier to find something already done...
Next, we'll take a quick look at what solutions the market has to offer at the moment, and what kind of bugs are being given away. We'll also look at the problems of automating this process and how it can be done easily and for free!
Comparing Solutions and Problems
Problem 0. No problems
There is a whole industry dedicated to providing SERP (search engine results page) optimization. For example, Google is ready to provide API to search itself, while other services provide search results from Yandex, Baidu, and other services in addition to access to Google.
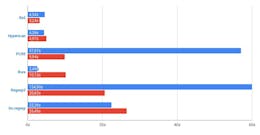
Here is a comparison of some commercial solutions:
- Google Custom Search - 100 free queries per day. $5 for 1000 queries;
- SerpApi - 100 free queries per month. Plans range from $50 to $250 per month;
- SerpWow - 100 free queries. Plans from $25 to $9000 per month;
- Oxylabs - 1 free week with 5k queries. Plans range from $49 to $249 per month.
There are about a dozen similar services. The market situation is generally clear: there are trial periods, if you like it, study the documentation, stick with the service, buy, and renew. The prices are not sky-high, but what about open-source projects? 🤓
Problem 1. Solutions are outdated
First and foremost, I would like to find a solution written in Go to use in my code or adapt it if possible. Let's take a look at what's available on the flea market GitHub:
-
github.com/rocketlaunchr/google-search - Yay! Immediately found a solution for Go. But to my great regret, it refused to work and returned no results ☹️. The developers warn us about this (fixed as of this writing):
The search engine DOM is subject to change, so solutions of this kind need to be constantly tweaked.
-
github.com/jarun/googler - A once popular console search toolkit written in Python. Last commit in 2021, the repository is archived, and it looks like the solution no longer works.
-
github.com/ecoron/SerpScrap - Library for Python. Failed to deploy it - it is necessary to install additional dependencies, how to use its docker is not documented. The solution is not developed since 2019 - do not have high hopes, move on...
-
github.com/serphacker/serposcope - Obsolete utility in Java with some UI for SEO. Seems to have Captcha solving functionality 🧐. Doesn't provide an API.
-
github.com/Athlon1600/SerpScraper - Solution for PHP. Not sure if it works (the last commit was 3 years ago), but there is some interesting code and captcha-solving functionality.


Problem 2: Fast detection without a browser
Some of the solutions I've described and seen use HTTP clients that are easy to detect. If we use them, after a short time we will encounter a captcha and our program will be bullied and called a bot 😢. The best implementations use a browser to search and then parse the page, but even this approach is not a panacea.
By the way, you can use the following services to check if you are a bot and benchmark your solutions:
- bot.sannysoft.com - shows the general parameters of your client and performs some tests;
- whatismybrowser.com - shows if the reported browser is the real one;
- abrahamjuliot.github.io/creepjs - able to detect hiding methods.
Try it, maybe as a certified android you should already have an electric sheep... 🐑⚡️.
Problem 3. They are just interfaces/wrappers :)
Some of the libraries I found turned out to be just interfaces to paid services. For example:
- github.com/towfiqi/serpbear - Something for SMM people. It's just a wrapper that uses the API of popular services.
- github.com/serpapi/google-search-results-python - Python library to interact with a paid service.
Uh-oh, what to do? There has to be a free and bad counterpart to every commercial service, right? Wrong...
Let's solve problems
Separate the wheat from the chaff
Let's automate the SERPs ourselves. On paper, solving problems does not look complicated. For example, to find all search results on the Baidu page, we can use this simple CSS selector (you can run it in the developer console in your browser)
// Find all elements of `div` that contain classes `c-container` and `new-pmd`
document.querySelectorAll(`div.c-container.new-pmd`)
You can do the same with XPath:
$x(`//div[contains(@class, "c-container") and contains(@class, "new-pmd")]`)
Then all that remains is to extract the useful information from the resulting HTML blocks and present it in a usable form.
Hide and automate
How do I automatically launch and parse CSS selectors? For many programming languages, there are frameworks that interact with the browser, such as the popular Selenium or Puppeter. In my case, I paid attention to Go-Rod.
As we have already found out, in terms of hiding our automated activity, it is better to do it via the browser than simply using an HTTP client. By the way, Go-Rod has an extension stealth that will additionally help hide our activity.
So, all the pieces are in place. All that remains is to design the right search query. You can learn this on your own - by experience or by looking at tutorials, e.g. here is a description of parameters for Baidu. Next, we use Go-Rod to start the browser in headless mode, navigate to the constructed URL and parse the results with CSS selectors... Voilà!


The flip side of the coin
Of course, even using the browser and tricks to hide our activity - sooner or later we will bite the Captcha. For the criterion of *usefulness of the solution, I invented benchmark 101 - if you can make 101 free requests per day (Google provides 100) through one machine (1 IP), then the solution surpasses all analogues is useful. And considering that there are 3 automated services, it's triple useful!
The disadvantages of this approach are:
-
We rely on the persistence of search engines DOM pages - if their structure changes, we have to fix our solution. But it depends more on the page elements you choose to "hook on" - for instance, the code I wrote 4 years ago was still able to parse results from a Google page unchanged (but was quickly detected as a bot).
-
By using the browser instead of a regular HTTP client, we have a slightly higher resource requirement and additional dependencies are needed.
Obviously, the way to work with different search engines will be different. The solution I will describe below uses a unified approach, so let's see how to get the search API in 2 clicks....
API Search Results
I used the above approach in the OpenSERP project. In order to enable access to search results via API, you can:
- Run OpenSERP in a Docker environment:
docker run -p 127.0.0.1:7000:7000 -it karust/openserp serve -a 0.0.0.0 -p 7000
- Or use compiled version for your OS, but you will need to have Chrome on your machine.
Running our server, we can use the following query to GET 25 search results in German for how to get banned from google fast:
http://127.0.0.1:7000/google/search?text=how to get banned from google fast&lang=DE&limit=25
An example of the result in JSON format 🤗:
[
{
"rank": 1,
"url": "https://www.apprimus-verlag.de/catalogsearch/result/index/?p=5&q=aiab.top%5BTutorial+on+how+to+get+Google+to+index+your+site+fast",
"title": "aiab.top[Tutorial on how to get Google to index your site fast",
"description": "Artikel 61 - 75 von 288 — Suchergebnisse für: \"aiab.top[Tutorial on how to get Google to index your site fast\" · Development of an Algorithm for the Taktline Layout ..."
},
{
"rank": 2,
"url": "https://chrome.google.com/webstore/detail/ban-checker-for-steam/canbadmphamemnmdfngmcabnjmjgaiki?hl=de",
"title": "Ban Checker for Steam - Chrome Web Store",
"description": "Automatically check bans of people you recently played with, your friends, and group members. ... Go to extension's options page to do so."
},
{
"rank": 3,
"url": "https://www.reuters.com/article/usa-google-idDEKBN28O1T1",
"title": "Einige Google-Dienste vorübergehend nicht erreichbar",
"description": "14.12.2020 — Viele Google-Nutzer schauten am Montag in die Röhre. Mehrere Dienste des US-Technologiekonzerns Alphabet wie die Videoplattform YouTube, ..."
},
...
]
In order to use Yandex or Baidu, we use the appropriate endpoint - yandex or baidu instead of google in the query. The parameters of the queries and their description are presented on the repository page.
It is also possible to get the results via the CLI.
Conclusion
Despite the availability of paid options to automate searches through well-known engines - there should always be a free alternative. That's why I created an open-source solution OpenSERP that supports multiple search engines (Google, Yandex, Baidu), can be deployed on your hardware, and helps you avoid being bound to a paid 3rd-party service. Of course, there is still some work to be done before the solution can be used on an industrial scale. But in any case, I hope it can be useful for the reader, so I invite you to check out the project :)
PS
You may also be interested in reading about automating web archives searches.