









Table of Links
2 MindEye2 and 2.1 Shared-Subject Functional Alignment
2.2 Backbone, Diffusion Prior, & Submodules
2.3 Image Captioning and 2.4 Fine-tuning Stable Diffusion XL for unCLIP
3 Results and 3.1 fMRI-to-Image Reconstruction
3.3 Image/Brain Retrieval and 3.4 Brain Correlation
6 Acknowledgements and References
A Appendix
A.2 Additional Dataset Information
A.3 MindEye2 (not pretrained) vs. MindEye1
A.4 Reconstruction Evaluations Across Varying Amounts of Training Data
A.5 Single-Subject Evaluations
A.7 OpenCLIP BigG to CLIP L Conversion
A.9 Reconstruction Evaluations: Additional Information
A.10 Pretraining with Less Subjects
A.11 UMAP Dimensionality Reduction
A.13 Human Preference Experiments
3 Results
We used the Natural Scenes Dataset (NSD) (Allen et al., 2022), a public fMRI dataset containing the brain responses of human participants viewing rich naturalistic stimuli from COCO (Lin et al., 2014). The dataset spans 8 subjects who were each scanned for 30-40 hours (30-40 separate scanning sessions), where each sesssion consisted of viewing 750 images for 3 seconds each. Images were seen 3 times each across the sessions and were unique to each subject, except for a select 1,000 images which were seen by all the subjects. We follow the standardized approach to train/test splits used by other NSD reconstruction papers (Takagi and Nishimoto, 2022; Ozcelik and VanRullen, 2023; Gu et al., 2023) which is to use the shared images seen by all the subjects as the test set. We follow the standard of evaluating model performance across low- and high-level image metrics averaged across the 4 subjects who completed all 40 scanning sessions. We averaged across same-image repetitions for the test set (1,000 test samples) but not the training set (30,000 training samples). For more information on NSD and data preprocessing see Appendix A.2.
Critically, models trained on a subset of data were selected in chronological order. That is, models trained from only 1 hour’s worth of data come from using the subject’s first scanning session of 750 image presentations. This means our model must be able to generalize to test data collected from scanning sessions entirely held-out during training.
3.1 fMRI-to-Image Reconstruction
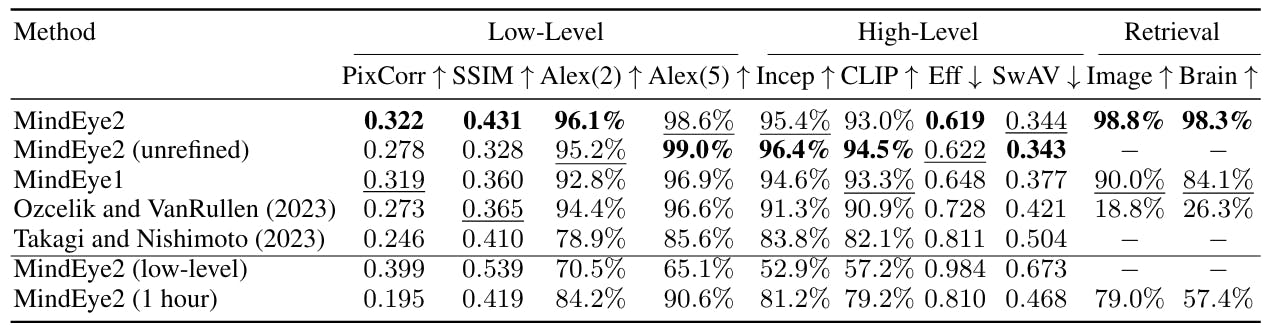
First, we report performance of MindEye2 when training on the full NSD dataset. We quantitatively compare reconstructions across fMRI-to-image models in Table 1, demonstrating state-of-the-art MindEye2 performance across nearly all metrics. We compare to both the previous MindEye1 results as well as other fMRI-to-image approaches that were open-sourced such that we could replicate their pipelines using the recently updated NSD (which includes an additional 3 scanning sessions for every subject).
MindEye2 refined reconstructions using the full NSD dataset performed SOTA across nearly all metrics, confirming that our changes to shared-subject modeling, model architecture, and training procedure benefitted reconstruction and retrieval performance (explored more in section 3.5). Interestingly, we observed that high-level metrics for the unrefined MindEye2 reconstructions outperformed the refined reconstructions across several metrics despite looking visibly distorted. This suggests that the standard evaluation metrics used across fMRI-to-image papers should be further scrutinized as they may not accurately reflect subjective interpretations of reconstruction quality.
We conducted behavioral experiments with online human raters to confirm that people subjectively prefer the refined reconstructions compared to the unrefined reconstructions (refined reconstructions preferred 71.94% of the time, p < 0.001). Human preference ratings also confirm SOTA performance compared to previous papers (correct reconstructions identified 97.82% of the time, p < 0.001), evaluated via two-alternative forced-choice judgments comparing ground truth images to MindEye2 reconstructions vs. random test set reconstructions. See Appendix A.13 for more details.

compare reconstructions side-by-side with models trained on only 1 hour’s worth of data in Figure 4, depicting improvements in reconstruction quality for MindEye2. We report more evaluations in the Appendix: see A.3 for MindEye2 results without pretraining, A.4 for evaluations with varying amounts of training data across all models, A.5 for single-subject evaluations, and A.10 for MindEye2 evaluations with varying selection of pretraining subjects. We also conducted a behavioral experiment with human raters which confirmed that humans subjectively prefer MindEye2 (1-hour) reconstructions to Brain Diffuser (1-hour) reconstructions (Appendix A.13).


3.1.1 VARYING AMOUNTS OF TRAINING DATA
The overarching goal of the present work is to showcase high-quality reconstructions of seen images from a single visit to an MRI facility. Figure 5 shows reconstruction performance across MindEye2 models trained on varying amounts of data from subject 1. There is a steady improvement across both pretrained and non-pretrained models as more data is used to train the model. "Non-pretrained" refers to single-subject models trained from scratch. The pretrained and non-pretrained results became increasingly more similar as more data was added. The 1-hour setting offers a good balance between scan duration and reconstruction performance, with notable improvements from pretraining. The non-pretrained models trained with 10 or 30 minutes of data suffered significant instability. These models may have experienced mode collapse where outputs were similarly nonsensical regardless of input. Such reconstructions coincidentally performed well on SSIM, indicating SSIM may not be a fully representative metric.
This paper is available on arxiv under CC BY 4.0 DEED license.
Authors:
(1) Paul S. Scotti, Stability AI and Medical AI Research Center (MedARC);
(2) Mihir Tripathy, Medical AI Research Center (MedARC) and a Core contribution;
(3) Cesar Kadir Torrico Villanueva, Medical AI Research Center (MedARC) and a Core contribution;
(4) Reese Kneeland, University of Minnesota and a Core contribution;
(5) Tong Chen, The University of Sydney and Medical AI Research Center (MedARC);
(6) Ashutosh Narang, Medical AI Research Center (MedARC);
(7) Charan Santhirasegaran, Medical AI Research Center (MedARC);
(8) Jonathan Xu, University of Waterloo and Medical AI Research Center (MedARC);
(9) Thomas Naselaris, University of Minnesota;
(10) Kenneth A. Norman, Princeton Neuroscience Institute;
(11) Tanishq Mathew Abraham, Stability AI and Medical AI Research Center (MedARC).










