






1,790 reads
Everything You Need to Know About Google BERT
by PacktFebruary 9th, 2021




Too Long; Didn't Read
BERT is a state-of-the-art embedding model published by Google. It represents a breakthrough in the field of NLP by providing excellent results on many NLP tasks, including question answering, text generation, sentence classification, and more. BERT relates each word in a sentence to all the other words in the sentence to understand the contextual meaning of every word. The BERT model is based on the transformer model, called Bidirectional Encoder Representations from Transformers.People Mentioned

Companies Mentioned


If you’ve been following developments in deep learning and natural language processing (NLP) over the past few years then you’ve probably heard of something called BERT; and if you haven’t, just know that techniques owing something to BERT will likely play an increasing part in all our digital lives. BERT is a state-of-the-art embedding model published by Google, and it represents a breakthrough in the field of NLP by providing excellent results on many NLP tasks, including question answering, text generation, sentence classification, and more.
Here we are going to look at what BERT is and see what is distinctive about it, by looking in a relatively high-level way (eschewing the underlying linear algebra) at the internal workings of the BERT model. By the end you should have if not a detailed understanding then at least a strong sense of what underpins this modern approach to NLP and other methods like it.
Basic Ideas Behind BERT
BERT stands for Bidirectional Encoder Representations from Transformers.
As we’ve said, it’s a state-of-the-art embedding model from researchers at Google. By calling it an embedding model we mean that, fed with natural language input, it generates vector-based representations – embeddings –of those inputs. One of the major reasons for BERT’s success is that it is a context-based embedding model, unlike other popular embedding models, such as word2vec, which are context-free.
First, let's look at the difference between context-based and context-free embedding models. Consider the following two sentences:
- Sentence A: He got bitten by a python.
- Sentence B: Python is my favorite programming language.
We understand, as soon as we read them, that the meaning of the word 'python' is different in the two sentences. In sentence A, the word 'python' refers to the snake, while in sentence B it refers to the programming language.
Now, if we derive embeddings for the word 'python' in the preceding two sentences using an embedding model such as word2vec, the embedding of the word 'python' would be the same in both sentences, rendering the meaning of the word 'python' the same in both sentences. This is because word2vec, being a context-free model, will ignore the context and always give the same embedding for the word 'Python' irrespective of context.
BERT, on the other hand, being a context-based model, will understand the context and then generate the embedding for the word based on that context. So, for the preceding two sentences, it will give different embeddings for the word 'python', according to the context.
Take sentence A: He got bitten by a python. First, BERT relates each word in the sentence to all the other words in the sentence to understand the contextual meaning of every word. So, to understand the contextual meaning of the word 'python', BERT takes the word 'python' and relates it to all the words in the sentence. By doing this, BERT can understand that the word 'python' in sentence A denotes the snake through its relationship to the word ‘bitten’.
Now, let's take sentence B: Python is my favorite programming language. Similarly, here BERT relates each word in the sentence to all the words in the sentence to understand the contextual meaning of every word. So, BERT takes the word 'python' and relates it to all the words in the sentence to understand the meaning of the word 'python'. By doing this, BERT understands that the word 'python' in sentence B is related to a programming language through its relationship to the word ‘programming’.
Thus, unlike context-free models such as word2vec, which generate static embeddings irrespective of the context, BERT generates dynamic embeddings based on the context. How does BERT do that?
BERT’s workings
Bidirectional Encoder Representations from Transformers (BERT), as the name suggests, is based on the transformer model. Let’s investigate what that means.
The transformer model
Recurrent neural networks (RNNs) and Long Short-Term Memory (LSTM) networks are widely used in sequential tasks such as next word prediction, machine translation, text generation, and more. However, one of the major challenges with the recurrent model is capturing long-term dependency.
To overcome this limitation of RNNs, a new architecture, called the transformer model, was introduced in the paper Attention Is All You Need (see Further reading). The transformer is currently the state-of-the-art model for several NLP tasks, and has paved the way for revolutionary new architectures such as BERT, GPT-3, T5, and more.
The transformer model is based entirely on something called the attention mechanism. It gets rid of recurrence completely. The transformer uses a special type of attention mechanism called self-attention.
Let’s consider how the transformer works with a language translation task. The transformer consists of an encoder-decoder architecture. We feed the input sentence (source sentence) to the encoder. The encoder learns the representation of the input sentence and sends the representation to the decoder. The decoder receives the representation learned by the encoder as input and generates the output sentence (target sentence).
Suppose we need to convert a sentence from English to French. As shown in the following figure, we feed the English sentence as input to the encoder. The encoder learns the representation of the given English sentence and feeds the representation to the decoder.
The decoder takes the encoder's representation as input and generates the French sentence as output:


Figure 1 – Encoder and decoder of the transformer
Encoder
The transformer consists of a stack of encoders. The output of one encoder is sent as input to the encoder above it. Each encoder sends its output to the encoder above it. The final encoder returns the representation of the given source sentence as output. We feed the source sentence as input to the encoder and obtain the representation of the source sentence as output:


Figure 2 – A stack of N encoders
Note that in the transformer paper Attention Is All You Need, the authors used N = 6, meaning that they stacked up six encoders one above the another. However, we can use different values of N. For simplicity and better understanding, let's keep N = 2:


Figure 3 – A stack of encoders
Now how does the encoder work? How is it generating the representation for the given source sentence (input sentence)? The following figure shows the components of the encoder:


Figure 4 – Encoder with its components
All the encoder blocks are identical. We see that each encoder block consists of two sublayers:
- Multi-head attention
- Feedforward network
Actually there’s rather more to it than that. The multi-head attention block can be thought of as a sophisticated method for computing, from input word embeddings, the self-attention values of words, which is a way of allowing the transformer to understand how one word is related to all the other words in the expression. The following figure shows encoder internal structure in more detail:


Figure 5 – A stack of encoders with encoder 1 expanded
As well as using attention matrices to understand how individual words in the input relate to all the other words, you can see that positional encoding plays a part in proceedings. It is therefore worth quickly saying what positional encoding is.
Positional encoding
Consider the input sentence I am good. In RNNs, we feed the sentence to the network word by word. That is, first the word I is passed as input, next the word am is passed, and so on.
We feed the sentence word by word so that our network understands the sentence completely. But with the transformer network, we don't follow the recurrence mechanism.
Instead of feeding the sentence word by word, we feed all the words in the sentence parallel to the network. Feeding the words in parallel helps to decrease the training time and also helps in learning the long-term dependency.
However, how will the transformer understand the meaning of the sentence if the word order is not retained? To understand the sentence, the word order (position of the words in the sentence) is important, right? Yes, since the position of each word in a sentence contributes to the meaning of the sentence.
So, we should give some information about the word order to the transformer so that it can understand the sentence. That’s what positional encoding accomplishes.
Now, going back to Figure 5, we see the following:
First, we convert our input to an input embedding (embedding matrix), and then add the position encoding to it and feed it as input to the bottom-most encoder (encoder 1).
Encoder 1 takes the input and sends it to the multi-head attention sublayer, which returns the attention matrix as output.
We take the attention matrix and feed it as input to the next sub-layer, which is the feedforward network. The feedforward network takes the attention matrix as input and returns the encoder representation as output.
Next, we take the output obtained from encoder 1 and feed it as input to the encoder above it (encoder 2).
Encoder 2 carries the same process and returns the encoder representation of the given input sentence as output. We can stack N encoders one above the other; the output (encoder representation) obtained from the final encoder (topmost encoder) will be the representation of the given input sentence.
Contextual word representations
After that deep-dive into the Transformer model and encoders let’s get back to BERT. We see that BERT uses the transformer model but includes only the encoder part.
In the previous section we saw that we feed a sentence as input to the transformer's encoder and it returns the representation for each word in the sentence as an output. Well, that's exactly what BERT is – Encoder Representation from Transformer. Okay, so what about that term Bidirectional?
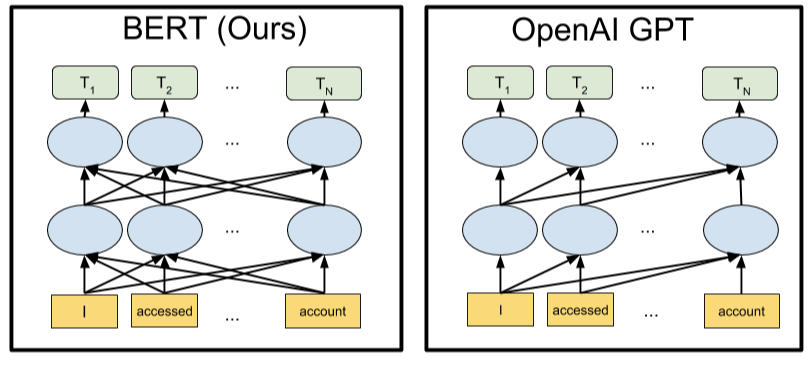
The encoder of the transformer is bidirectional in nature since it can read a sentence in both directions. Thus, BERT is basically the Bidirectional Encoder Representation obtained from the Transformer.
Let's understand this better using the same sentences we saw in the previous section.
We’ll go back to our previous sentence A: ‘He got bitten by Python’. Now, we feed this sentence as an input to the transformer's encoder and get the contextual representation (embedding) of each word in the sentence as an output. Once we feed the sentence as an input to the encoder, the encoder understands the context of each word in the sentence using the multi-head attention mechanism (which relates each word in the sentence to all the words in the sentence to learn the relationship and contextual meaning of words) and returns the contextual representation of each word in the sentence as an output.
As shown in the following diagram, we feed the sentence as an input to the transformer's encoder and get the representation of each word in the sentence as an output. We can stack up N encoders, as shown in the following diagram. We have only expanded encoder 1 so as to reduce clutter. In the following diagram, RHe denotes the representation of the word 'He', Rgot is the representation of the word 'got', and so on. The representation size of each token will be the size of the encoder layer. Suppose the size of the encoder layer is 768, then the representation size of each token will be 768:


Figure 6 – BERT generating the representation of each word in the sentence
Similarly, if we feed sentence B, 'Python is my favorite programming language', to the transformer's encoder, we get the contextual representation of each word in the sentence as output, as shown in the following diagram:


Figure 7 – BERT generating the representation of each word in the sentence
Thus, with the BERT model, for a given sentence, we obtain the contextual representation (embedding) of each word in the sentence as an output. Now that we understand how BERT generates contextual representation, let’s look at the different available configurations of BERT.
Configurations of BERT
The BERT’s developers have made the model available in two standard configurations:
- BERT-base
- BERT-large
BERT-base consists of 12 encoder layers, stacked one on top of the other. All the encoders use 12 attention heads. The feedforward network in the encoder consists of 768 hidden units. Thus, the size of the representation obtained from BERT-base will be 768.
We use the following notations:
- The number of encoder layers is denoted by L.
- The attention head is denoted by A.
- The hidden unit is denoted by H.
Thus, in the BERT-base model, we have L = 12, A = 12, and H =768. The total number of parameters in BERT-base is 110 million. The BERT-base model is shown in the following diagram:


Figure 8 – BERT-base
BERT-large consists of 24 encoder layers, each stacked one on top of the other. All the encoders use 16 attention heads. The feedforward network in the encoder consists of 1,024 hidden units. Thus, the size of the representation obtained from BERT-large will be 1,024.
Hence, in the BERT-large model, we have L = 24, A = 16, and H =1024. The total number of parameters in BERT-large is 340 million. The BERT-large model is shown in the following diagram:


Figure 9 – BERT-large
Both BERT models have been pre-trained on two large text corpora, the Toronto BookCorpus (800m words) and English Wikipedia (2500m words), using two training tasks: next sentence prediction and masked language modeling (i.e. fill in the missing word in a sentence).
Apart from the preceding two standard configurations, we can also build the BERT model with different configurations. We can use smaller configurations of BERT in settings where computational resources are limited. However, the standard BERT configurations, such as BERT-base and BERT-large, give more accurate results and they are the most widely used.
Using BERT
At this point you might well be thinking that this is all very well, but it’s rather abstract and theoretical. What can the BERT model be used for, and how would we set about using it? To the first question, we need just say here ‘a wide variety of problems in NLP’, since BERT captures and expresses in its output representations so much of the context that matters in language processing. Examples include such classic problems as text summarization (of both extractive and abstractive kinds), classification tasks such as sentiment analysis, and translation.
In terms of how BERT is used, it is important to note that it acts not on raw words but rather on text tokenized into WordPieces. And typically, the pre-trained BERT models are used as a starting point, with fine tuning then being performed in a subsequent training stage against input data relevant to the specific task and domain at hand.
Concluding remarks
The advent of BERT represents a shift in the tectonic plates of natural language processing. Using a Transformer-based architecture, the BERT model captures enough of the nuance of language to allow hitherto tough NLP problems to be tackled successfully. This opens up new digital vistas, and promises – dare one say it – to transform the nature of our relationship, through language, with computers. Moreover, approaches to NLP based on BERT and its kin offer hope that it will indeed be possible to meet the challenge posed by the sheer quantity of text held globally in digital form.
Further reading
Attention Is All You Need, by Ashish Vaswani, Noam Shazeer, and Niki Parmar, available at https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, by Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, available at https://arxiv.org/pdf/1810.04805.pdf.
Text Summarization with pre-trained Encoders by Yang Liu and Mirella Lapata, available at https://arxiv.org/pdf/1908.08345.pdf
Buy the book here- http://packt.live/2Mg6cWt

L O A D I N G
. . . comments & more!
. . . comments & more!











