






Evaluating Multi-Cloud Event Distribution and Load Balancing in DeFaaS
by Blockchainize Any TechnologyJanuary 30th, 2025




Too Long; Didn't Read
The evaluation highlights the impact of geographical location over cloud provider on multi-cloud event latency, and the performance of IPFS read operations. Randomized load balancing is tested through simulation, with the default design achieving the best results. The integration of SmartPubSub enhances decentralized event delivery with reduced latency.
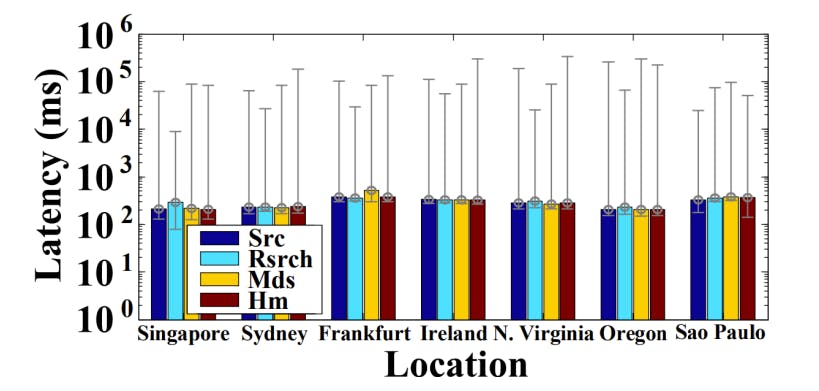



Table of Links
2 Background and Motivation
2.1 Decentralized Computing Infrastructure and Cloud
4 Detailed Design of DeFaaS and 4.1 Decentralized Scheduling and Load Balancing
4.2 Decentralized Event Distribution
4.3 API Registration and Access Control
4.5 Logging and Billing and 4.6 Trust Management
4.7 Supporting Multi-Cloud Service Mesh
5 Implementation and Evaluation
5.3 Evaluation
Multi-cloud event dissemination. Multi-cloud event distribution performance is evaluated. We first present the latency with different applications from remote nodes in Figure 2. For small messages (Figure 2), the latency varies significantly across different remote nodes. In particular, the maximum latency can be much higher than the median value.
To evaluate the performance for a given message size on each node, we run the experiment 30 times for selected applications. For Figure 1 we see that when communicating between different clouds, what affects the event latency more is the different geographical locations than different cloud providers. Since most of the cloud providers are already very optimized, inter-cloud communications have a lesser impact than actual physical servers being in different geographical regions than our testbed and also from the different servers sending the different-sized packets to IPFS. Note that the differences between applications are small and negligible.
Out current work is to integrate with a new decentralized network for disseminating information on top of the IPFS, called SmartPubSub [Agostinho et al.(2022)]. SmartPubSub leverages ScoutSubs, a completely decentralized protocol for event message distribution and a fast delivery protocol centered around the publisher. Based on the experiments with a network of containerized SmartPubSub nodes (in one region), [Agostinho et al.(2022)], the average event latency under normal situation is between 200 - 250ms.
Effect of IPFS read operations. We measure performance of the downloading operations across clouds (data saved to the IPFS and retrieved using read operations by another node). Latency is determined by the length of time it takes for an operation to complete, and throughput is calculated by dividing the amount of data processed by the latency of the operation. We observe that the locations of the remote nodes do not have a major impact on the read latency. This is likely because the experimented applications often perform small read requests, which can result in high variance in read latency. When a node performs remote read operations, the resolving and downloading operations required by the local node significantly affect the I/O performance.
Randomized load balancing. To evaluate the performance of randomized load balancing, we have developed a simulator for experiments. The simulator models the API gateways and routing of API calls to multi-cloud data centers. In the current version, API calls take the same unit time to complete, which can be easily extended to random completion time. The simulator allows us to explore load balancing performance of different heuristics: (i) a default design based on the standard power of two choices; (ii) a simplified heuristic called choice of two; and (iii) a baseline of no randomized load balancing. In the default design, when an API gateway of a cloud data center receives a call, it will randomly pick another cloud data center using on-chain random source. If the receiving data center is busier than the



randomly picked data center, then the call will be forwarded to the randomly picked data center. In the choice of two heuristic, when an API gateway of a cloud data center receives a call, it will evaluate whether the receiving cloud has been overloaded (queued calls exceeding its configured capability). If the receiving cloud is overloaded, it will forward the call to a randomly picked data center. In the baseline, there is no randomized load balancing. Due to space limit, here we report the results assuming that calls should be evenly distributed to the data centers. Further, when a call is forwarded, gateway node will be randomly selected.
We have simulated three settings, i.e., 6, 8, and 10 data centers. Results are averaged based on five runs of the simulation. Each run simulates 10,000 API calls. Table 2 shows the average API call queue times for different experiment scenarios. According to the results, the default implementation of randomized load balancing achieves the best performance in terms of average queue times comparing with the other options. The second option (choice of two) only performs slightly worse. The average queue times are the worst without randomized load balancing. Although the second option has slightly longer average queue times, it may still be a good candidate in the actual deployment because of its simplicity. In the second option, a gateway node is not required to track or query any state status of other data centers. The support for a lightweight implementation (no need to keep states of other data centers) may overcome its slight disadvantage in performance. Further, the heuristic and simulator can be modified to use multi-dimension utility that combines cost, decentralization and performance.
Authors:
(1) Rabimba Karanjai, Department of Computer Science, University of Houston ([email protected]);
(2) Lei Xu, Department of Computer Science, Kent State University;
(3) Lin Chen, Department of Computer Science, Texas Texh University;
(4) Nour Diallo, Department of Computer Science, University Of Houston;
(5) Weidong Shi, Department of Computer Science, University Of Houston.
This paper is

L O A D I N G
. . . comments & more!
. . . comments & more!












