








What is BERT? How does one use BERT to solve problems? Google Colab, Tensorflow, Kubernetes on Google Cloud
Overview
This for people who want to create a REST service using a model built with BERT, the best NLP base model available. I spent a lot of time figuring out how to put a solution together so I figured I would write up how to deploy a solution and share!
Why should you read this?
Today we have machine learning engineers, software engineers, and data scientists. The trend in deep learning is that models are getting so powerful that there is little need to know about the details of the specific algorithm and can be immediately applied to custom use cases. This trend will turn the job of machine learning engineers into a skill that software engineers have. There will still be data scientists because there will be the need to apply traditional machine learning methods and incorporate domain knowledge on “small” data to solve problems and get the desired performance.
What is BERT?
BERT, or Bidirectional Encoder Representations from Transformers, is a new method of pre-training language representations which obtains state-of-the-art results on a wide array of Natural Language Processing (NLP) tasks. — Github Project Page
Why is BERT important?
#1 When released performed state-of-the-art on 11 NLP tasks.
On SQuAD v1.1, BERT achieves 93.2% F1 score (a measure of accuracy), surpassing the previous state-of-the-art score of 91.6% and human-level score of 91.2%
BERT also improves the state-of-the-art by 7.6% absolute on the very challenging GLUE benchmark, a set of 9 diverse Natural Language Understanding (NLU) tasks.
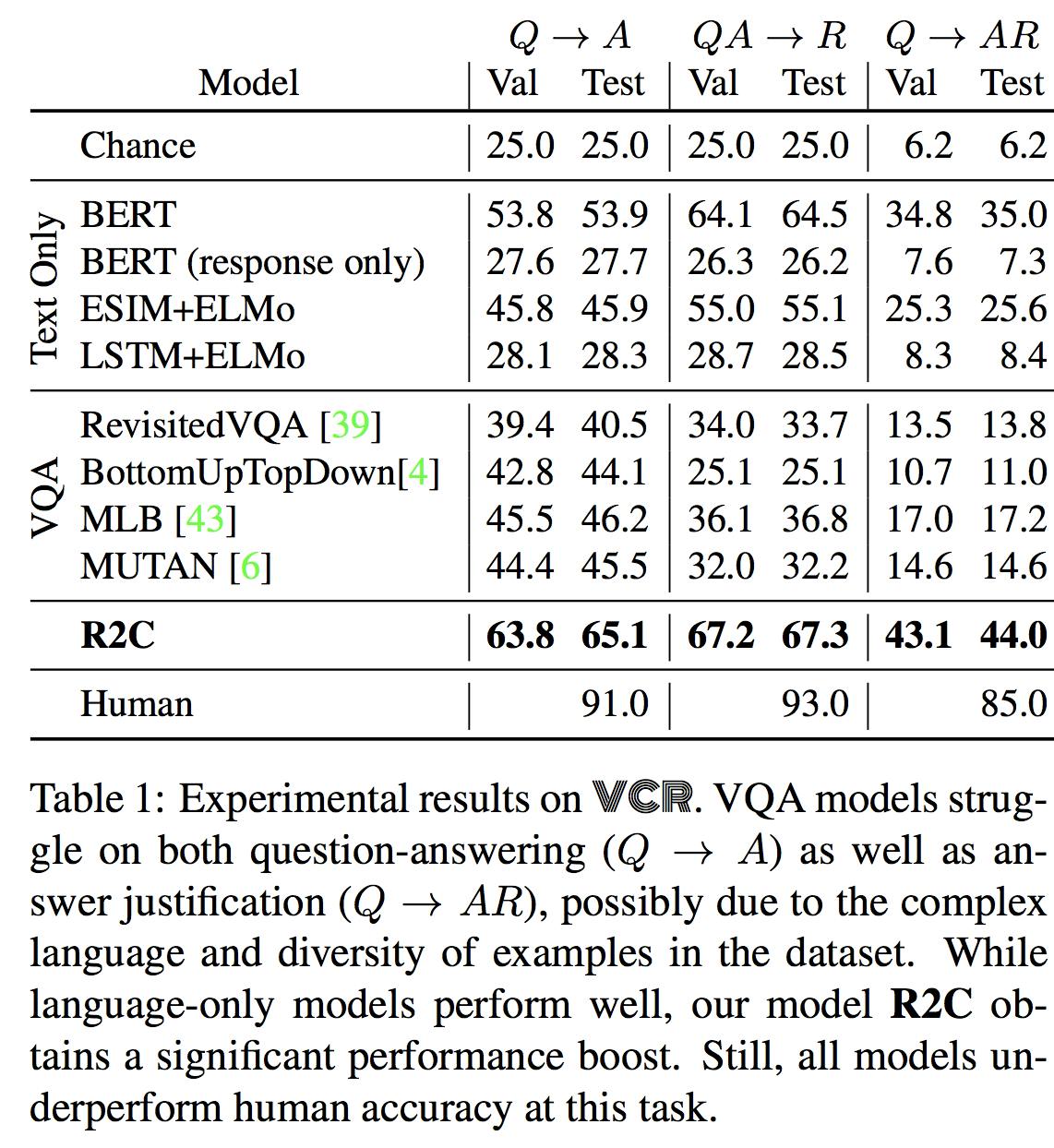
#2 The main driver for Visual Common Sense performance
Deep text-only models perform much better: most notably, BERT [17] obtains 35.0% accuracy. […] Our model, R2C obtains an additional boost over BERT by 9% accuracy, reaching a final performance of 44%. […] The model suffers most when using GloVe representations instead of BERT: a loss of 24%.
The empirical evidence demonstrated by using BERT on different tasks across different domains gives good reason to try BERT. Let’s use BERT to solve a classification problem!
Find a problem to solve
Sebastian Ruder started a project to track the progress in Natural Language Processing tasks.
This walkthrough is going to tackle a text classification problem. For simplicity, we are going to choose the AG News Dataset since the dataset is a reasonable size and closely aligns with a traditional classification problem.
Refer to this article to get the AG News Dataset ready for training.
Part 1: Fine-tune BERT using AG News Dataset
The result of following this entire tutorial is here. The Google Colab notebook to process the dataset, train, and export the model can be found here. The following will go over recreating needed resources for the REST service at a high level.
First, clone the BERT repo so that we extend the project to meet our needs.
Second,run_classifier.py is the file to extend for sentence classification. To add a new data source add a class that extends DataProcessor. The DataProcessor class specifies the methods to implement and you can refer to the other classes that extend DataProcessor to figure out reasonable implementations.
class AgnewsProcessor(DataProcessor):"""Processor for the MultiNLI data set (GLUE version)."""
def get_train_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")),"dev_matched")
def get_test_examples(self, data_dir):"""See base class."""return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):"""See base class."""return ["World","Entertainment","Sports","Business",]
def _create_examples(self, lines, set_type):"""Creates examples for the training and dev sets."""examples = []for (i, line) in enumerate(lines):if i == 0: # for headercontinuesingle_example = self._create_example(line, set_type)examples.append(single_example)return examples
def _create_example(self, line, set_type):guid = "%s-%s" % (set_type, tokenization.convert_to_unicode(line[0]))text_a = tokenization.convert_to_unicode(line[1])if set_type == "test":label = "World"else:label = tokenization.convert_to_unicode(line[-1])single_example = InputExample(guid=guid, text_a=text_a, label=label)return single_example
Third, copy this notebook to train, evaluate and export the model. For training, this tutorial will use Google Colab notebooks. To use the notebook as designed, create a Google Storage Bucket to store the base model and trained model.
Why use Google Colab notebooks? They are a free compute resource and easy to share.
The initial evaluation results are not very promising. For a deeper analysis look here.
***** Eval results *****eval_accuracy = 0.25eval_loss = 7.6698585global_step = 12000loss = 7.3534603
At the end of Part 1, you should have exported a fine-tuned BERT model trained on data of your choosing. This tutorial saves the model into Google Cloud Storage.
Part 2: Write Tenorflow Serving Client
Now that we have a saved model. We need to create some code to call the Tensorflow model and get predictions. The code needs to run on a server and the easiest lightweight code to use is Flask.
First, parse and process the input with FullTokenizer using a call to _create_example which outputs an InputExample which the BERT model expects.
inputExample = processor._create_example([request_id, content['description']], 'test')
Second, transform InputExample to tf.train.Example usingfrom_record_to_tf_example
tf_example = classifiers.from_record_to_tf_example(3, inputExample, label_list, 64, tokenizer)
Third, now send the formatted input to the Tensorflow Serving container.
### create predict request objectmodel_request = predict_pb2.PredictRequest()
### specify name of modelmodel_request.model_spec.name = 'bert'
### specify name of function to callmodel_request.model_spec.signature_name = 'serving_default'
### specify dimetion of requestdims = [tensor_shape_pb2.TensorShapeProto.Dim(size=1)]tensor_shape_proto = tensor_shape_pb2.TensorShapeProto(dim=dims)
### create model input objecttensor_proto = tensor_pb2.TensorProto(dtype=types_pb2.DT_STRING,tensor_shape=tensor_shape_proto,string_val=[model_input])
### actually send request to model and wait for outputmodel_request.inputs['examples'].CopyFrom(tensor_proto)result = stub.Predict(model_request, 10.0) # 10 secs timeoutresult = tf.make_ndarray(result.outputs["probabilities"])pretty_result = "Predicted Label: " + label_list[result[0].argmax(axis=0)]app.logger.info("Predicted Label: %s", label_list[result[0].argmax(axis=0)])
Part 3: Build Docker Containers for Tensorflow-Serving and Tenorflow-Serving Client
Using the flask app and Tensorflow model, we can create docker containers and deploy them using Kubernetes.
Kubernetes (k8s) is an open-source system for automating deployment, scaling, and management of containerized applications. — Project Page
If you don’t know anything about Kubernetes I suggest you go over this set of tutorials.
One of the real benefits of using Kubernetes is the abstraction of networking. You can have different pieces of an application deployed in different pods on different nodes and talk to each other internally seamlessly while exposing a single point of entry called a ‘service’.


Image Credit: https://kubernetes.io/docs/tutorials/kubernetes-basics/expose/expose-intro/
Build Docker Containers and Push Containers to Dockerhub
Prerequisite: Create a Dockerhub account
# Create Tensorflow Serving Container and host on DockerhubIMAGE_NAME=tf_serving_bert_agnewsVER=1547919083_v2MODEL_NAME=bertDOCKER_USER=lapoloniocd ~docker run -d --name $IMAGE_NAME tensorflow/servingmkdir ~/modelsgsutil cp -r gs://bert-finetuning-ag-news/bert/export/AGNE/1547919083 ~/modelsdocker cp ~/models/1547919083/ $IMAGE_NAME:/models/$MODEL_NAME
### the MODEL_NAME is an internal convention in Tensorflow Serving used to refer to the model and create/name the corresponding model REST endpoint_docker_ commit --change "ENV MODEL_NAME $MODEL_NAME" $IMAGE_NAME $USER/$IMAGE_NAME
docker tag $USER/$IMAGE_NAME $DOCKER_USER/$IMAGE_NAME:$VERdocker push $DOCKER_USER/$IMAGE_NAME:$VER
# Create client to call Bert Modelgit clone https://github.com/lapolonio/bert.gitcd ~/bert
CLIENT_IMAGE_NAME=bert_agnews_clientCLIENT_VER=v3DOCKER_USER=lapoloniomkdir assetgsutil cp gs://cloud-tpu-checkpoints/bert/uncased_L-12_H-768_A-12/vocab.txt asset/docker build -t $USER/$CLIENT_IMAGE_NAME .docker tag $USER/$CLIENT_IMAGE_NAME $DOCKER_USER/$CLIENT_IMAGE_NAME:$CLIENT_VERdocker push $DOCKER_USER/$CLIENT_IMAGE_NAME:$CLIENT_VER
Create a Kubernetes cluster, deploy containers to Kubernetes in Google Cloud
### create k8s clustergcloud container clusters create bert-cluster
### set the target cluster to the created clutergcloud config set container/cluster bert-cluster
### get credentials from google cloud to allow deploymentgcloud container clusters get-credentials bert-cluster --zone us-east1-b --project bert-227121
### deploy containerskompose convert --stdout | kubectl apply -f -
In Google Cloud Console there is an option to connect to Google Cloud when you select that option the following prompt opens:


Image Credit: Google Cloud Console Interface
Conclusion: Enterprise-Ready vs Production-Ready
This tutorial goes over deploying a Tensorflow model built using BERT in Kubernetes on Google Cloud. We used BERT as the base model to solve an NLP classification task. This solution pattern creates a proof of concept ecosystem to test if Kubernetes is a viable solution to provide Tensorflow models in production in the cloud. There could be barriers to using Kubernetes / Tensorflow Serving such as networking or performance constraints.
If Kubernetes is viable there is still a number of steps to get this solution Production-Ready:
- AutoScaling (to handle different workloads)
- Logging
- CNAMES (unless you are ok with referring to possibly changing IPs)
- Alerts (to notify if service goes down)
- Automatic builds and deployments (CI/CD)
- Different Environments for testing
Kubernetes is an excellent solution for serving stateless applications at scale. Tensorflow Serving is a robust platform for serving Tensorflow models. Tensorflow Serving provides model versioning functionality and model status endpoints that fit nicely with heartbeats and ready to be used for alerts.
__________
Additional Resources:
The Illustrated BERT, ELMo, and co. (How NLP Cracked Transfer Learning)_The year 2018 has been an inflection point for machine learning models handling text (or more accurately, Natural…_jalammar.github.io
https://github.com/google-research/bert#sentence-and-sentence-pair-classification-task
Save and Restore | TensorFlow_TensorFlow Variables are the best way to represent shared, persistent state manipulated by your program…_www.tensorflow.org
RESTful API | TensorFlow Serving | TensorFlow_The RESTful APIs support a canonical encoding in JSON, making it easier to share data between systems. For supported…_www.tensorflow.org
Using TensorFlow Serving with Docker | TensorFlow Serving | TensorFlow_This will run the docker container and launch the TensorFlow Serving Model Server, bind the REST API port 8501, and map…_www.tensorflow.org
Interactive Tutorial — Deploying an App_To interact with the Terminal, please use the desktop/tablet version Continue to Module 3›_kubernetes.io
Deploying a containerized web application | Kubernetes Engine Tutorials | Google Cloud_Google Cloud delivers secure, open, intelligent, and transformative tools to help enterprises modernize for today’s…_cloud.google.com
Google Cloud Platform I: Deploy a Docker App To Google Container Engine with Kubernetes_Google Cloud Platform (GCP) is a cloud computing service by Google that offers a set of enterprise cloud services that…_scotch.io
Exposing applications using services | Kubernetes Engine | Google Cloud_Google Cloud delivers secure, open, intelligent, and transformative tools to help enterprises modernize for today’s…_cloud.google.com











