Enhancing Search With Elastic
How we are improving search in our app using Elastic Search


In our highlights application we recently worked on improving the search functionality. All the search API calls are routed through backend node api server to take care of authentication and access rights.
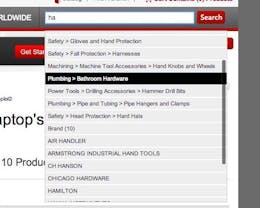
Our advanced search looks as follows.

As you can see from the image above we had five fields that were critical for search. Using our app you will be able to highlights any relevant text on a webpage, add notes and tags to it. So in the search we wanted to let users find a particular highlights using
- Highlighted text.
- Added tags.
- Added note.
- URL on which the highlight was made.
- Date on which the highlight was made.
We implemented the search and it was all working fine. But the problem was that users rarely remember whether the keyword they are searching was part of which particular field.
So we broke down the problem into two steps. First irrespective of the which field the keyword was entered into getting the results. Second making sure that the most relevant results still came at the top.
1. Making sure result-set is not too restrictive
We created a temporary field that clubbed all the keywords entered by the user irrespective of which field they had entered it in. We used this clubbed field as keywords to do a text search filtering. So if any of the keywords entered by the users were present in any of the fields of a document it would filter/select that document. For records matching this query we just added a simple scalar score.
2. Making sure that the relevant results floated to the top
And then in the second level we searched the keyword entered in the field filter from UI with the exact field in the backend. If this matched we added an additional score with higher weight. So if there was a one to one match that document would come at the top of the result as it has more relevancy score.
Not all fields are born equal. In our case URL field and tag fields are more contextual. So if there is a match in these fields we used a higher multiplier for the score.
Fine tuning the query was a little difficult. So we set explain = true. This explains how the score was calculated for the query, document combination. You can read more about it in this link https://www.elastic.co/guide/en/elasticsearch/reference/1.4/search-explain.html
We passed the explanation output to the front end in our dev instance and just displayed it in the display of results along with the score. This way we could easily see how scoring was affecting our search. As an exercise we picked a particular record and then tried to search for it. This was along with confirming that whether our result was floating to the top or not, we were able to identify how our scoring was affecting the results.
You can check out how our search and advanced is working on https://alpha.app.learningpaths.io/#/highlights/public
It is still a work in progress and would love to have your feedback.
Shareable search queries
If the search filters are part of the URL then users will be able to bookmark those urls and they can even share them with the friends. Sharing was important for us as we were adding the option of sharing the highlights publicly as well. So all the search entries by user were handled on the front end and url was updated accordingly.

Search
Enabling actual search filters
Since we were not actually filtering based on the entered keywords we also had to the change the wording. We used the prefix in before the field name to convey that we were actually doing a search within the field.
While the approach we took improved the search for the end users, it gave rise to a new issue. For example let us say that I have thousands of highlights and I want to filter my search to strictly that contain a tag say ‘drupal’. Since we had broadened our search it would also fetch the records where the text ‘drupal’ is present in notes or url as well. So we introduced a new filter keyword with the prefix has. So if you type in hasTag:drupal in the search it will fetch only those records that actually contain the tag drupal. We have not exposed this option now. This will be a cheat code for pro users for now. Once we figure out the UX to add this we will add it to the UI.
Like our product our search is far from complete. But we are putting it out these so that you can already use it while we keep improving it.