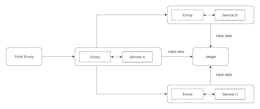
Distributed tracing is being promoted as one of the pillars of observability, offering enhanced visibility into cross-service interactions. It gives potentially an opportunity to identify the service interaction problems, providing a precise understanding of where problems may arise.
Despite its advertised and widely promoted potential, there are more chances to fail to adopt distributed tracing than to get any value out of it. Let’s review the main myths, misconceptions, and failures associated with adopting distributed tracing.
Teams Implement Just Another Logging
Frequently, the initial attempts at implementing distributed tracing within organizations fail because they start with a very common approach: instrument only a few microservices. This strategy is a common starting point for demonstrating the successful PoC.
However, the typical result of these experiments is that teams use tracing in the boundaries of their service or a few services. So, instrumenting just one service out of dozens or even hundreds leads to an unexpected result - teams end up with what is essentially another form of logging.
Think about it … in addition to the next familiar logline:
{ "ip": "127.0.0.1", "user": "-", "date": "06/Dec/2023:12:30:45 +0000", "method": "GET", "url": "/example-page", "http_version": "HTTP/1.1", "status_code": 200, "response_size": 1234 }
The application starts sending the following spans to the distributed tracing backend:
{
"traceId": "8a4da9f548267ea8",
"spanId": "bc8d7a6c12345a",
"parentSpanId": "a2a7b5c6123456",
"name": "HTTP GET /example-page",
"kind": "SERVER",
"timestamp": 1638760245000,
"duration": 1500,
"attributes": {
"http.method": "GET",
"http.status_code": 200,
"http.url": "/example-page",
"ip": "127.0.0.1",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"
},
"status": {
"code": "OK",
"message": "HTTP 200"
}
}
In other words, that is just structured logging. That is not really the outcome that engineers expect. Many teams stop experimenting with distributed tracing at this stage, as teams do not really need another form of logging albeit with more visualization – the value of which is often questionable.
How to Avoid It?
Distributed tracing extends beyond the individual service or deployment scope. Successful tracing requires instrumenting the entire request flow passing through dozens of services, making tens or even hundreds of persistence layer calls, and uncontrolled third-party integrations.
Nobody Told Us That the Cost of Tracing Grows Unproportionally.
Teams are already accustomed to paying for metrics and logging … and sometimes, a lot. Believe me, distributed tracing costs can be as high or even higher as there are costs associated with ingestion, indexing, network usage, and, in some cases, user access.
Let’s think about why the tracing cost is that high. The answer is actually obvious: it is common for engineers to assume that the more extensively they instrument with distributed tracing, the more value they'll derive.
Undoubtedly, there is value in creating spans, and for each database call, outgoing request, or other resource-intensive operations. That gives incredible transparency on how the system is operating and where are the potential bottlenecks.
However, well, it takes some time for teams to acknowledge that this is not exactly how tracing is used as, in practice, a significant portion of data collected remains unused, yet the costs persist.
How to Avoid It?
Be mindful of how, what, and when to instrument. Obviously, excluding routine health-check requests, numerous database calls, and noisy flows is a good starting point. But even excluding all the noise is not enough: you need to start sampling the data.
And sampling means that only a fraction of traces will be stored and by a fraction; I do not mean 50% … but rather 10-15% or even smaller for high throughput applications.
Vendors Sold Us an Idea That Tracing Reduces MTTR and MTTD, But It Doesn’t Because of the Limitations of Trace Sampling.
You can often see similar text on the vendors’ papers:
If a customer reports that a feature in an application is slow or broken, the support team can review distributed traces to determine if this is a backend issue. Engineers can then analyze the traces generated by the affected service to quickly troubleshoot the problem.
Well, what often goes unsaid is that distributed tracing might not be the silver bullet for all types of failures. Let’s already agree that we cannot avoid sampling the traces, and only a minority of data reaches the vendor. What would that mean? It means that tracing becomes less effective for:
- searching for a specific customer problems
- identifying rare issues that are difficult to pinpoint
- address scoped outages such as an outage of specific architecture cells or performance degradation of the specific software version
How to Avoid It?
First, understand why your organization needs distributed tracing and what problem it solves beyond the industry hype and everyone trying. Ask yourself if you can find use cases when storing only 5% of all the traces is an acceptable compromise.
Automatic Instrumentation Is Not Always Automatic
Automatic code instrumentation is a very useful and time-saving approach to instrumenting your code for distributed tracing. In some cases (e.g., Java), it requires the addition of dependency and a few configuration lines. However, the first impression can be deceptive:
-
Async complexity. While there are instrumentations available for tools like Kafka and other async communication platforms, automatic instrumentation can be less effective for entirely asynchronous systems that rely heavily on background jobs and batched requests.
This is because automatic tools may struggle to accurately capture and correlate the spans in such environments.
- Performance Issues. Automated instrumentation can introduce performance overhead. That could become an issue, especially for applications with strong performance requirements. So, never forget about performance tests before enabling them in the production environment.
- Legacy systems. Most of the software is legacy to some extent, and automated instrumentation doesn't guarantee support for all libraries, versions, or use cases.
- Bespoke frameworks. Enterprises often develop in-house frameworks, libraries, and packages avoiding widely off-the-shelf solutions. It introduces challenges when it comes to instrumentation as in most cases automated instrumentation won’t be helpful for those use cases.
The Biggest Failure of Distributed Tracing: A Commitment and Culture
Again, distributed tracing operates on the level of the entire request meaning that every individual service should be instrumented with distributed tracing. Instrumenting every service requires significant engineering effort and careful planning.
Moreover, there is no guarantee that the project will be successful and that all the effort will translate to an improved MTTR and MTTD.
As for the culture, teams already have dashboards and monitors for all the downstream, dependencies, incoming, and outgoing requests. Engineers teams have yearly improved logging that actually, in common, is good enough to troubleshoot most of the issues.
Introducing distributed tracing as yet another tool to improve MTTR and MTTD can be met with resistance from teams accustomed to their existing monitoring processes.
Conclusion
A distributed project is an extremely huge and complicated IT project that should be executed on an organizational level. Numerous pitfalls and considerations come into play, and even if you're skeptical based on my experience, it's crucial to bear these points in mind.