








We, humans, are experiencing tailor-made services which have been engineered right for us, we are not troubled personally, but we are doing one thing every day, which is kind of helping this intelligent machine work day and night just to make sure all these services are curated right and delivered to us in the manner we like to consume it.
Can you guess, what is that one thing? Yeah, you got it right, we humans are knowingly/unknowingly generating a hell lot of Mr. ‘Data’ every second.
Data, data, data, it’s everywhere and wherever it is, it is being harnessed by data engineer like us, who love to extract meanings and values out of it, in-order to serve humanity at large.
Having said that, these data sets are not easy to handle, we need to make sure it is properly sampled, cleaned curated, structured, analyzed, so that it can deduce meaningful inferences, patterns, and predictions.
As an aspiring/professional data engineer, you need to make sure that, you are able to identify which features/attributes in that sea of data is real gold which needs to be hunted.
That is where data engineers came across this one wonderful tool /algorithm called PCA. Treat data redundancy based on correlation they have and are able to minimize the higher dimension of data sets to lower dimensional space
PCA: Principal components analysis method, is what we will look into deeply today and also will discuss:
What is PCA?Why PCA?How Does It work?PCA use case examplesHow to apply it using python, to solve one real-world problem.
Let’s get started:
What & Why Of PCA?
As per wiki:
Technical Definition:
Principal Component Analysis (PCA) is a statistical procedure that orthogonally transforms the original n coordinates of a data set into a new set of n coordinates called principal components. As a result of the transformation, the first principal component has the largest possible variance; each succeeding component has the highest possible variance under the constraint that it is orthogonal to (i.e., uncorrelated with) the preceding components.
Too technical yeah… Let’s make it easier for you with a
Functional Definition:
In a real-world scenario, we often get our data sets which are beyond 2 or 3 D(dimension). For us, it’s difficult to visualize and comprehend them as it has 100 & 1000’s of features. Training ML models become difficult, time taking and also very expensive to run. In order to deal with this high dimensionality problem, we came up with the concept of PCA, where we filter out mathematically which features are important and which we can leave out.
This non parametric process /technique used for identification of a smaller number of uncorrelated variables from the larger set of data, to make it easy to comprehend and visualize is what we call the Principal Component Analysis.
Here we deal with reducing the dimension of data sets to make life easier for data engineers to analyze.
So we can also define :
Principal Component Analysis (PCA) is one of the popular techniques for dimension reduction, feature extraction, and data visualization.
Mathematically:
PCA is defined by a transformation of a high dimensional vector space into a low dimensional space. Let’s consider the visualization of 20-dim data. It is barely possible to effectively show the shape of such high dimensional data distribution. PCA provides an efficient way to reduce the dimensionality (i.e., from 20 to 2/3), so it is much easier to visualize the shape and the data distribution. PCA is also useful in the modeling of robust classifier where a considerably small number of high dimensional training data is provided, by reducing the dimensions of learning data sets, PCA provides an effective and efficient method for data description and classification.
Intuition Behind PCA ?
In order to understand how PCA works one needs to have a basic understanding of these mathematical concepts. It is advisable that you spent some time to grab those concepts to come in talking terms with PCA. We will touch this very briefly here:
Vectors:
A vector is a mathematical object that has a size, called the magnitude, and a direction.
For example, a vector would be used to show the distance and direction something moved in. If you ask for directions, and a person says “Walk one kilometer towards the North”, that’s a vector. If he says “Walk one kilometer”, without showing a direction, it would be a scalar.
Eigenvectors:
In linear algebra, an eigenvector or characteristic vector of a linear transformation is a nonzero vector that changes at most by a scalar factor when that linear transformation is applied to it. Geometrically, an eigenvector, corresponding to a real nonzero eigenvalue, points in a direction in which it is stretched by the transformation and the eigenvalue is the factor by which it is stretched.
Eigenvalues:
Every eigenvector has a corresponding eigenvalue. An eigenvector is a direction. If the eigenvalue is negative, the direction is reversed. Loosely speaking, in a multidimensional vector space, the eigenvector is not rotated. However, in a one-dimensional vector space, the concept of rotation is meaningless.
Variance:
Variance is an error from sensitivity to small fluctuations in the training set. High variance can cause an algorithm to model the random noise in the training data, rather than the intended outputs (overfitting).
Variance is the change in prediction accuracy of ML model between training data and test data.
In probability,
The variance of some random variable X is a measure of how much value in the distribution varies on an average with respect to the mean. The variance is denoted as the function Var() on the variable.
Covariance:
In probability, covariance is the measure of the joint probability for two random variables. It describes how the two variables change together. It is denoted as the function Cov(X, Y), where X
Some other terminologies one needs to understand:
Dimensionality :
It is the number of random variables in a dataset or simply the number of features, or rather more simply, the number of columns present in your data set.
Correlation:
It shows how strongly two variables are related to each other. The value of the same ranges for -1 to +1. Positive indicates that when one variable increases, the other increases as well, while negative indicates the other decreases on increasing the former. And the modulus value indicates the strength of the relation.
Basically PCA is a dimension reduction methodology that aims to reduce a large set of (often correlated) variables into a smaller set of (uncorrelated) variables, called principal components, which holds sufficient information without losing the relevant info much.
Mathematically, PCA is a projection of some higher dimensional object into a lower dimension. What sounds complicated is really something we encounter every day: when we watch TV we see a 2D-projection of 3D-objects!
Principal Component Space:
Principal components are new variables that are constructed as linear combinations or mixtures of the initial variables. These combinations are done in such a way that the new variables (i.e., principal components) are not correlated and most of the information within the initial variables is squeezed or compressed into the first components.
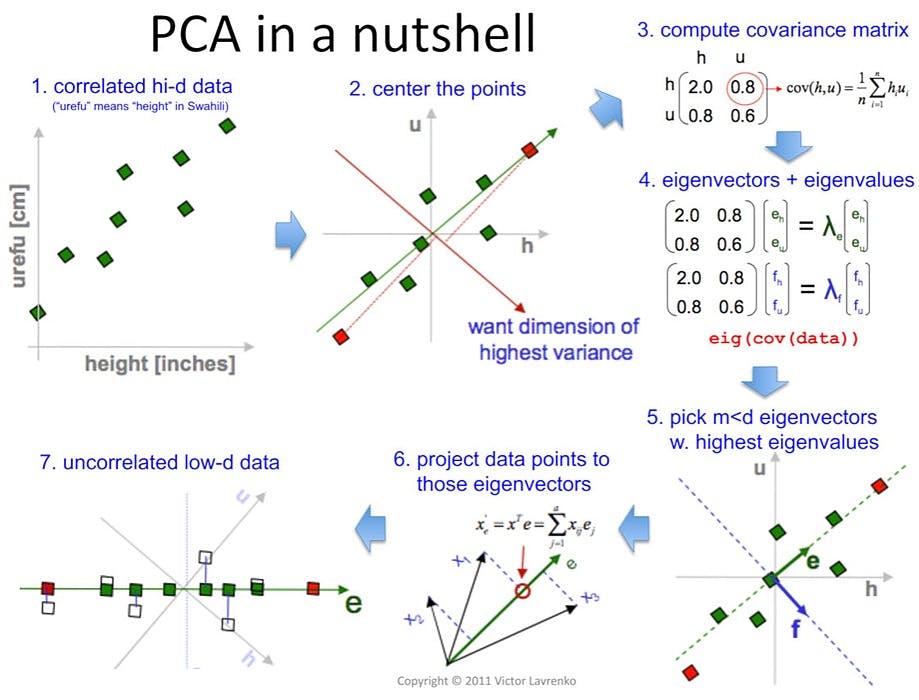
PCA: Implementation Steps:
A: Normalizing The Data Set:
In the first step we need to normalize the data that we have so that PCA works properly. This is done by subtracting the respective means from the numbers in the respective column. So if we have two dimensions X and Y, all X become 𝔁- and all Y become 𝒚-. This produces a dataset whose mean is zero. We can achieve this using sci-kit learn scaling/normalizing methods.
Mathematically, this can be done by subtracting the mean and dividing by the standard deviation for each value of each variable.
Once the standardization is done, all the variables will be transformed to the same scale.
B: Find The Covariance Of The Normalized Data Set
For 2D vectors: Our 2x2 Covariance matrix will look like,
Where,
Var[X1] = Cov[X1,X1] and Var[X2] = Cov[X2,X2].
C: Find the Eigenvectors and EigenValues of the Covariance matrix :
Next we calculate eigenvalues and eigenvectors for the covariance matrix. The matrix here is a square matrix A. ƛ is an eigenvalue for a matrix A if we get equation given below:
det( ƛI — A ) = 0,
Here,
I is the identity matrix of the same dimensionA which is a required condition for the matrix subtractiondet’ is the determinant of the matrix.
For each eigenvalue ƛ, a corresponding eigenvector v, can be found by solving:
( ƛI — A )v = 0
D: Calculating the feature vector to form Personal Component Space:
We rank the eigenvalues from largest to smallest so that it gives us the components in order or significance. Here at this stage we try to reduce the dimension to find the eigenvectors which will be forming the feature vectors, which is a matrix of vectors, called the eigenvectors.
Feature Vector = (eig1, eig2, eg3,… ), it depends upon the mathematical space we are dealing with.
E: Forming Principal Components :
After we go through previous steps we make use of the feature vector values, transpose it and multiply it with the transpose of the scaled features of the original which we performed at the initial stage of normalization.
We build a new reduced dataset from the K chosen principle components.
reducedData= FeatureVectorT x ScaledDataT
Here, reducedData is the Matrix consisting of the principal components,
FeatureVector is the matrix we formed using the eigenvectors we chose to keep, and
ScaledData is the scaled version of original dataset. T stands for transpose we perform on the feature and scaled data.
Summarizing PCA:
PCA brings together:
A measure of how each variable is associated with one another. It uses the Covariance matrix to do so.The directions in which our data are dispersed. (Eigenvectors.)The relative importance of these different directions. (Eigenvalues.)
PCA combines our predictors and allows us to drop the eigenvectors that are relatively unimportant.
Understanding PCA With Hands-On Example In Python:
We will understand how to deal with the problem of the curse of dimensionality using PCA and will also see how to implement principal component analysis using python.
Data Set:
We will make use of the vehicle-2.csv data set sourced from open-sourced UCI .
The data contains features extracted from the silhouette of vehicles in different angles. Four Corgie & model vehicles were used for the experiment: a double-decker bus, Cheverolet van, Saab 9000 and an Opel Manta 400 cars. This particular combination of vehicles was chosen with the expectation that the bus, van and either one of the cars would be readily distinguishable, but it would be more difficult to distinguish between the cars.
Objective:
The purpose is to classify a given silhouette as one of three types of vehicles, using a set of features extracted from the silhouette. The vehicle may be viewed from one of many different angles. How We Will Meet Our Objective? We will be applying a dimensionality reduction technique — PCA and train a model using the reduced set of principal components (attributes/dimensions). Then we will build Support Vector Classifier on raw data and also on PCA components to see how the model performs on the reduced set of dimensions. We will also print the confusion matrix for both the scenario and see how our model has performed in classifying various vehicle types based on the given silhouette of the vehicles.
Let’s Go Hands-On:
To help you all better understand and dry run the code, here is the code file shared on kaggle
Please get your hands dirty and share your feedback if you found it helpful
#ChandrayanLogy:
Data engineers have a major responsibility for making sense of all the data sets they receive for analysis. Performing the right feature engineering steps to prepare the data set is key to the success of this whole exercise of data engineering and machine learning process. Dimensionality reduction is one such key process that needs to be taken care of, so that we are cherry-picking the relevant features. This features which will go into building machine learning models will decide how well we are solving the given problem statement.
So make data your friend, get into the depth & breadth of it to analyze, you will be surprised how much it has to say and infer. As a business leader data needs to be at the core of your day to day decision making if you really want to be in the game for a longer period of time. Machines, when well trained with meaningful data, can empower you with the right set of information to compete in this highly dynamic marketplace.
Thanks for being together in this journey, Happy Learning !
(Picture Credits: Victor Lavrenko)











