Well we all are aware that a cache — pronounced CASH — is hardware or software that is used to store something temporarily in a computing environment and if you want to really know about in detail how it actually works you can go to through its definition here as this article assumes that the reader has fair understanding of the caching as a concept.
As we know that the most interesting applications can no longer be executed in isolation and thus modern applications are built from many components and this components interact with each other which in today’s era we called them as distributed systems.
When the things becomes distributed it will come with its advantages and disadvantages as well because the cost and complexity of maintaining and developing these system are very high but nonetheless to say this is the essential technique to suffice the need of today’s internet application.Now lets talk about the cache in the distributed system.
Caching is the critical concept which ultimately boost the performance of the system as a whole but again in order to reap maximum benefits out of it we can follow the following approaches to introduce caching in distributed systems.
1. Adding the Web Cache as a Side Car Pattern:
This approach is pretty simple as the web cache container has been deployed along side with the each instance of your server as a side car pattern to which the service does not aware of the cache server which makes it completely decoupled from it and we can easily play around or do any modification of the cache container without effecting the service.


But again this has its own disadvantages as we will have to scale the cache server as the same scale of the service this isn’t the good approach for designing the cache as best practice is to have as few replicas as possible with lots of resource for each replica for example it would also be beneficial to have two 10 GB of replica as a whole rather than having 1 GB of 10 cache replica as a system because it will decrease the hit rate which will eventually beat the purpose of caching in the system and to overcome these disadvantages we can used caching as a replica services which have been described in the next section.
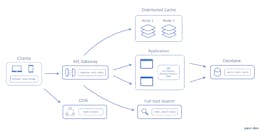
2. Adding Cache Container As A Replica Services In The System:
Instead of adding the caching instance along with each instance of the container we can add the cache web servers above our service containers so that all the containers will have the access to these cache replica as shown in the below figure and in turn this cache will call the service in case of cache misses .


The main advantage of this approach is that you have the few replica of cache servers and each having the huge capacity to hold the data independently thus result in decreasing of cache misses as a whole as compared to previous strategy and also the application written in NodeJS which can really utilize the single core because of its single threaded nature can be used in this approach to create the multiple smaller replica of NodeJs service on the single machine to leverage the multiple cores and in front having these minimum number of replicas with maximum resource making it more suitable caching strategy for implementing in distributed system as with this approach we need not have to scale the cache service with the application service.
Also you can do various things like implementing the rate limiting and the termination of the SSL itself at the cache layer side instead in the applications service.
But again if the request which is to be cached itself is quite huge and the RPS (Request Per Second) is also at really high side then it will make more sense to distribute the request itself across the cache replica with the concept called Sharded Caching which we will cover in next section.
3. Sharded Caching:
The previous approaches are generally used for building stateless services whereas this sharded caching is used for building the cache in the stateful services also it is beneficial if the application is having millions of concurrent connection at a time and even the delay in millisecond can be costly to the business.
Shraded cache is the cache which sits between the user and the cache replica which in turn has the logic to distribute the load evenly across all the replica.The important thing here is to design the sharded hash function to avoid frequent collision and keep the load even across all the replicas.There are many strategies like consistent hashing for implementing the sharded logic which is out of scope of this article.


Also with the sharding of the cache we can store the maximum resources at cache side itself as compared to the approaches which we have discussed earlier , for example if our service has 100GB of data then we can only have the 5 replicas of cache servers having capacity of 10 GB each to cover the 50 % of the recently used data of the service which ultimately increase the hit rate of the cache result in increasing the performance of the application as a whole with minimum number of cache replica.
Again designing and implementation of this sharded system is really cost and also its increase the complexity of the system as a whole as now we have to take of the reliability and resiliency of the proxy servers too.
Some of the concepts like availability , reliability , resiliency and scalability we do have to take care while implementing this strategies in production so that it can actually play a vital role in the distributed system which we will cover later in the next series of articles.
But one golden rule we can always follow in the distributed system is to always design by the strategy called “Two Mistakes High” which means design the resiliency strategy by taking care of the failures at two levels rather than one so that in case of any failover system should have one chance to bear the mistake rather than failing instantaneously.