








Many products solve for global issues and load balancing but unless a platform is built from the ground up with the necessary backbones, it becomes a nightmare to manage.
Enter Neil Huang and Chaitra Ramarao’s talk that discusses the concepts: Deep Dive on Cross-Platform, Multi-Region, Active-Active Replication.


First off, this talk gives an excellent overview of challenges that developers and architects need to overcome to remain viable in a very demanding environment.
I encourage you to share it with colleagues that could use an overview of any of these topics: data replication, cross-datacenter support, high-performance queries, multi-node, multi-cluster, geographic distribution, offline applications, and more. The above graphic shows today’s operating paradigm challenges.
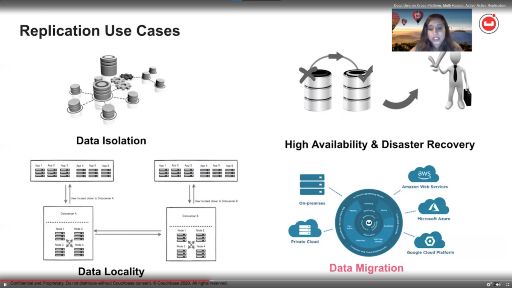
The presentation dives into several of these groupings, especially replication, and provides the context for different scenarios developers are dealing with. For example, replication use cases touch on concepts such as: data isolation, data locality (keeping it near your users), high availability (never going down), and disaster recovery (instant recovery from standby nodes).
If any replication technology you have been using does not address these use cases, then it is not hitting the mark. Also, it is imperative that much of this is managed automatically behind the scenes. Requiring administrators to keep it all held together only leads to disaster (and no Black Friday vacations for sysadmins!).

How does Couchbase handle these requirements?
Couchbase, as an example of a distributed platform, has a very powerful data backend that largely goes unnoticed by users but keeps things running well. The names of these subsystems is not important but just to give you some context for digging in further in any system…
The Data Change Protocol (DCP) keeps data up to date between nodes and services whenever data changes. This allows, for example, new documents to be stored in the document database but also pushes it to other services like the indexer or full-text search if enabled. It all happens automatically without user intervention to keep your cluster up to date. Learn more in the intra-cluster replication docs.
Then there is Cross-DataCenter Replication (XDCR) that does something similar but between multiple clusters. This is the core of the presentation and they show how you can filter data between clusters using this technology too — so some clusters will hold certain documents and not others if needed.
XDCR allows clusters to run in multiple geographic regions yet stay up to date. Application developers can point local users to the nearest cluster to reduce latency. Learn more in the XDCR introduction docs.
Reducing administrative headaches
As I’ve alluded to, by having these subsystems keep everything updated, automatically, it means there is no one in the server closet swapping cables to keep a service alive!
Clusters can see when a node becomes unavailable, and automatically failover to a live backup that has been running. Similarly, if one cluster disappears, the backup is still running and receiving updates until it returns. It can also inform applications to switch over.
The setup of clusters and XDCR are all done through a web-based GUI that makes it simple. You can even follow the stats to see the queues for documents and the rate at which they are distributed throughout the system. It’s all there and ready to be used much training at all.
Simplifying application development
How does all this infrastructure make it easier for developers? Similar to the above ease of management, developers can instead focus on writing applications and just pointing them to use a cluster. They don’t need a deep knowledge of how nodes work or how clusters are maintained.
Just write code!
Write your application code, test it on a laptop if needed, then point it to a real cluster to scale. All the benefits come from the power of the backend. Multi-cluster aware Couchbase libraries also allow applications to failover easily without manual intervention, so developers don’t have to write all their own complex pinging, etc.
I encourage you to watch the whole talk after registering here.
Also published at https://medium.com/couchbase/distribution-replication-and-resiliency-core-for-modern-data-platforms-cecf1c617403












