









Authors:
(1) Yagci, Nurce, HAW Hamburg, Germany & [email protected];
(2) Sünkler, Sebastian, HAW Hamburg, Germany & [email protected];
(3) Häußler, Helena, HAW Hamburg, Germany & [email protected];
(4) Lewandowski, Dirk, HAW Hamburg, Germany & [email protected].
Table of Links
Objectives and Research Questions
Conclusion, Research Data, Acknowledgments, and References
METHODS
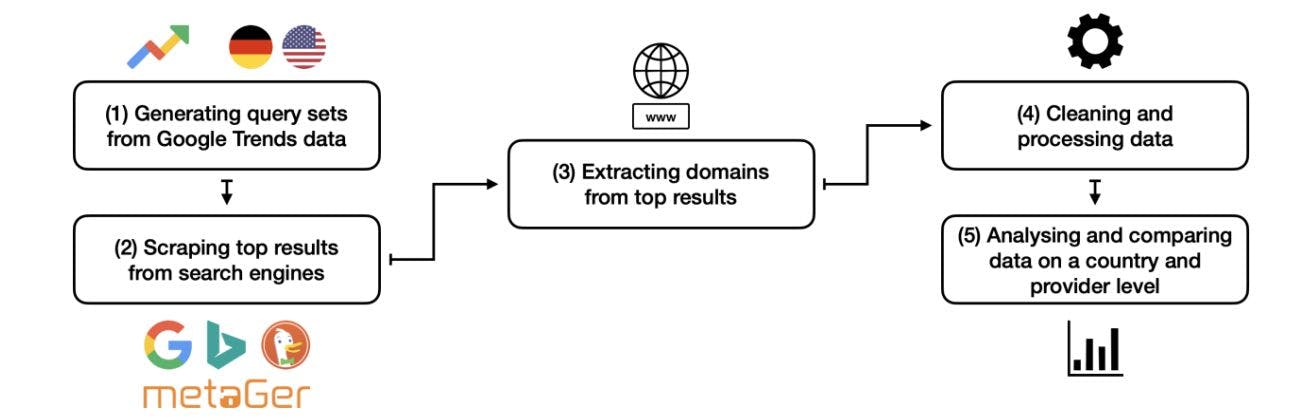
As illustrated in Figure 1, this study was conducted in five steps. In the first step, the query sets were generated from previously collected Google Trends data. The daily trends for both Germany and the US were collected daily at 3 am CET from November 10th, 2021, until March 31st, 2022. Since the daily number of trending queries can vary, the query sets for Germany and the US are not the same size. Two thousand nine hundred sixteen trending queries for Germany and 2,819 for the US were initially collected. However, since some topics of interest are longer lived than a single day, the same topics can be trending on multiple days. Therefore, after removing duplicates, our query sets consist of 1,821 queries for Germany and 2,126 queries for the US. The queries have a wide range, including topics like celebrities (e.g., "Sandra Bullock"), sports (e.g., "NFL," "Liverpool vs. Southampton"), seasonal events (e.g., "Macy's Thanksgiving Day Parade," "Restaurants open on Thanksgiving"), headline news (e.g., "TikTok classaction lawsuit settlement"), and more.

In step 2, for each query, the top 10 results from all four search engines were collected. We made sure to request results for the appropriate language and location by using URL parameters. Furthermore, we decided to limit the comparison to the top 10 results because users usually only consider these. Again, for our study, only the implications for the user perception are relevant. The Web scraping component of the Relevance Assessment Tool (RAT; Sünkler et al., 2022) was used to collect the data. The scraping took place between April 6th and 9th, 2022, with 230,315 results (Germany: 109,604; US: 120,711) gathered. It is important to note that only organic search results were considered. A fair comparison can be ensured when ranked result lists instead of vertical inserts of universal search results (e.g., Google News and Bing News) are considered. We also ignored ads since they are not part of the search engine's web index.
During step 3, the python library urllib was used to get the domain of each search result. To ensure a fair comparison between all search engines, in step 4, we removed results for any query that had less than ten results in any of the search engines. Additionally, the data was checked and stripped of any errors that might have occurred during the collection, like duplicate results. This resulted in a further reduced dataset consisting of 1,672 queries and 66,880 results for Germany and 1,865 queries and 74,600 results for the US. Lastly, the extraction of top-level domains was further refined in this step. We used basic string matching to unify URLs that pointed to the same domains. For example, the following three URLs would have been counted as separate domains without the string matching: https://www.facebook.com, "http://www.facebook.com", and "http://www.facebook.com/".
Finally, in step five, we used different methods of comparing the data collected. An initial comparison is made by using simple descriptive statistics. To measure source concentration, we adapt the Gini coefficient, a measure of statistical dispersion used to measure income or wealth inequality (Gini, 1936). The Gini coefficient is a single number ranging from 0 to 1, where 0 represents perfect equality, and 1 is the maximum inequality. As Ortega et al. (2008) demonstrated, adapting this measure to the distribution of values in different domains is appropriate. In the case of search result sets, this allows us to compare the various search engines easily. The lower the Gini coefficient, the more equally the results are distributed over all domains contributing to a particular result set.
Following that, we calculate the Jaccard similarity index (González et al., 2008). Puschmann (2019) demonstrates the usage of the Jaccard index to measure the similarity between two result sets. The Jaccard index is a single number ranging from 0 to 1, where 0 means that the two sets are entirely dissimilar, while 1 means that they are identical. We calculate the Jaccard index for every two-way combination of our four search engines (e.g., Google and Bing, Bing and Metager, etc.) for all stages between the top 1 and top 10 results (e.g., Google and Bing position 1 to 5).
This paper is available on arxiv under CC 4.0 license.












