










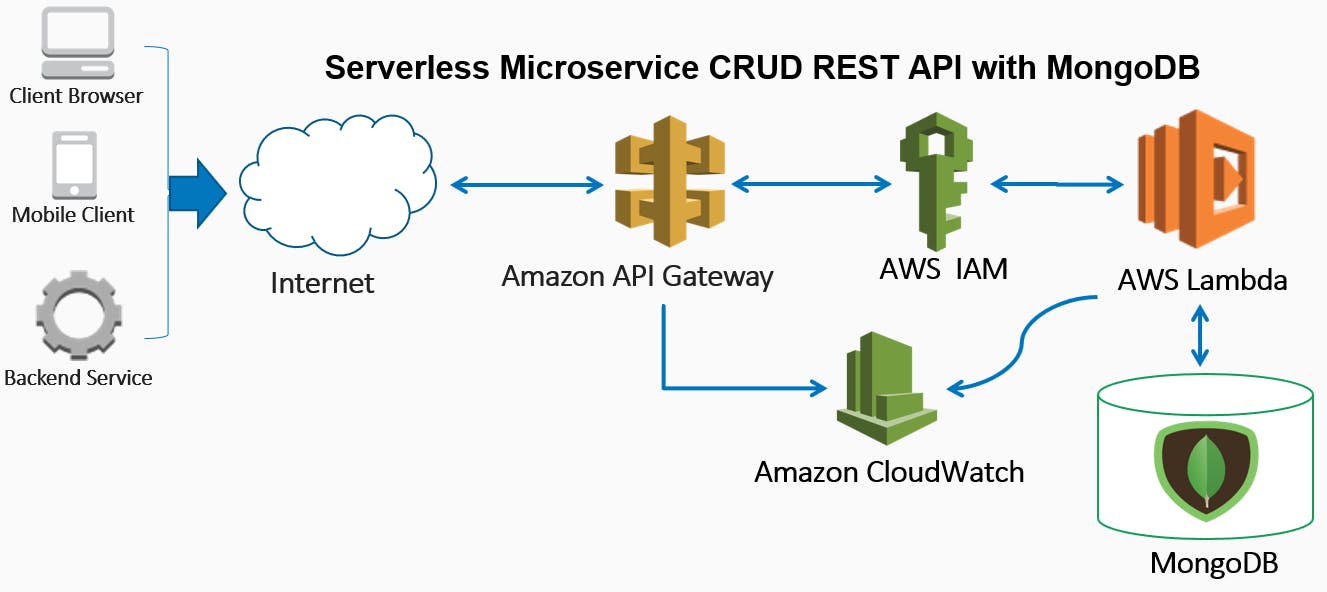

In this post we will build a Serverless Microservice that exposes create, read, update, delete (CRUD) operations on a fully managed MongoDB NoSQL database. We will be using the newly release Lambda Layers to package the 3rd party libraries needed to integrate with MongoDB. We will use Amazon API Gateway to create, manage and secure our REST API and it’s integration with AWS Lambda. The Lambda will be used to parse the request and perform the CRUD operations. I’m using my own open sourced code and scripts, and AWS Serverless Application Model to test, package and deploy the stack.
Serverless Microservice CRUD REST API with MongoDB
Serverless is gaining more and more traction and can complete or complement containers. In serverless there are still servers, it’s just that you don’t manage them, you pay per usage and it auto scales for you. It’s also event-driven in that you can focus more on business logic code, and less on inbound integration thanks to growing number of Lambda event sources triggers such as Alexa, S3, DynamoDB and API Gateway built and maintained by AWS.
To make it more interesting, in this post I’m using a simplified version and subset of the pattern that I presented at AWS re:Invent 2016 and in the AWS Big Data Blog post you could use to implement real-time counters at scale with DynamoDB, from billions of web analytics events in Kinesis Streams as used in our in-house RAVEN Data Science Platform. Here the focus will be creating the front end for that rather than backend, i.e. a serverless CRUD REST API using API Gateway, Lambda and MongoDB.
MongoDB and my History with it
There are many NoSQL databases out there, such as Amazon DynamoDB which is a key-value and document store and integrates easily with the rest of the serverless stacks in AWS for which there are many blog posts, books, documentation and video courses including my own. As we have covered DynamoDB before lets talk about using MongoDB instead. If we look at some of the DB rankings it is doing very well at number 5 overall and number 1 for document-stores databases, and has some big names using it.
I’ve had some history with MongoDB. When we begun our journey of deploying machine learning in production in 2013 at JustGiving, a tech-for-good crowdfunding and fundraising platform that raised over $5 billion for good causes from 26 million users, and acquired for $121M by Blackbaud in 2017. I chose to call the product PANDA, and the second system we built was an offline batch training and inference engine (back then embedding data science in product was extremely rare and it was more local data science on a laptop, no Apache Spark, serverless or stable docker either). Those batch scores, inference or predictions would then be inserted at regular intervals in to MongoDB, and we would serve the predictions, recommendations and suggestions via our PANDA REST API that our front end services and mobile app would call. The beauty of this architecture, I came up with, was that we decoupled data science serving from frontend products, allowing us to move at different speeds and update the backends without them noticing.
At the time I chose MongoDB for the backend data store as it was a NoSQL database giving us flexibility to store data in JSON, retrieve it at very low latency, and could easily scale out through sharding. This was a great AI success story at JustGiving, and was the start of many subsequent case studies, keynotes, books, and recognitions. We no longer use MongoDB but PANDA is still used and new exciting features and experiments being added regularly. I got inspired to write this post from reading Adnan Rahić’s post on building a serverless API using node.js and MongoDB but here I’m using the more up to date serverless features from Re:Invent, my current favourite language Python, and the open-source AWS Serverless Application Model (SAM).
MongoDB Setup
MongoDB Atlas is what we will be using as it has a free tier with no credit card, and is a fully managed service.
Setting up a New Cluster
1. In your browser, go to the MongoDB web interface2. Choose Start free3. Type your email, first name, last name, password4. Check I agree to the terms of service.5. Choose Get started free7. Choose Off for Global Cluster Configuration6. Choose AWS for Cloud Provider & Region7. Choose a region with the free tier available * For those in America choose us-east-1 * For those in Europe choose eu-central-1 * For those in Asia chose ap-southeast-1 or ap-south-18. For Cluster Tier leave it at M0 (Shared RAM, 512 MB Storage)9. For Additional Settings leave defaults10. For Cluster Name type user-visits11. Choose Create cluster * You will get captcha too * This will begin creating the cluster
Configuring and Connecting to your Cluster
Lets now create a database user that the Lambda function can use, allow the Lambda to access the database by whitelisting the IP range and connect to the cluster.
1. Choose the Security tab and MongoDB Users2. Choose Add New User sub-tab3. In the SCRAM Authentication * For username type lambdaReadWriteUser * For password type a secure password * For User privilege choose Read and write to any databases4. Choose IP Whitelisting sub-tab5. Choose Add IP Address6. Choose Allow access from Anywhere* Security risk — you will see that CIDR 0.0.0.0/0 has been added allowing any system to access the database, generally a very bad security practice but fine for a proof of concept with demo data here.7. Choose Confirm8. Choose the Overview tab9. Choose Connect in the Sandbox window10. Choose Short SRV connection string under Copy the connection string compatible with your driver11. Install the Python dependent packages pymongo, dnspythonand bson$ sudo pip install pymongo dnspython bsonor with sudo pip install -r requirements.txt
Connecting to MongoDB Locally using Python
Create a Python script called mongo_config.py and type or paste the following which stores the
db_username = "lambdaReadWriteUser"db_password = "<my-super-panda-password>"db_endpoint = "user-visits-abcde.mongodb.net/test?retryWrites=true"db_port = "27017"
The db_endpointis the host in the Short SRV, i.e. the part after the @symbol. Here testis going to be the name of the database, replace it with the desired name.
Security recommendations
There are some security risks with the above, so for production deployments I recommend:* Use MongoDB AWS VPC peering Peering Connection (you will need to used payed M10+ instances)* Do not use 0.0.0.0/0in the IP white list, rather launch the Lambda in a VPC and restrict it to that Classless Inter-Domain Routing (CIDR) or IP Range* Do not use mongo_config.py to store the password instead use KMS to encrypt it and store it in the Lambda environment variables.
Lets now create the four CRUD methods.
Creating the PUT Method
Create and run Python script called mongo_modify_items.pyand type or paste the following
Here I use the repository design pattern and create a class MongoRepositorythat abstracts and centralizes all the interactions with MongoDB including the connection and insertion of JSON records. When the MongoRepositoryis instantiated we create the Short SRV connection string we saw earlier using the variables in mongo_config.pyand parameters mongo_db, table_name.
In the insert_mongo_event_counter_json() method I first shape the check the data has an EventId then create an entity_id entity_id with EventId and EventDay to serve as update filter similar to a primary key. The {“$set”:{‘EventCount’: event_data.get(‘EventCount’, 1)}}is the update action, here we overwrite the existing EventCount value for the update filter as it’s a PUT so should be idempotent — calling it many time has the same effect. Here I’m using update_one()to show you the $set operator but you could equally use simpler insert_one() to add the JSON document to a MongoDB collection, see Mongo documentation.
When you run this you should get the following in the console
{'n': 1, 'nModified': 0, 'opTime': {'ts': Timestamp(946684800, 2), 't': 1}, 'electionId': ObjectId('7fffffff0000000000000001'), 'ok': 1.0, 'operationTime': Timestamp(1546799181, 2), '$clusterTime': {'clusterTime': Timestamp(946684800, 2), 'signature': {'hash': b'~\n\xa5\xd9Ar\xa5 \x06f\xbd\x8e\x9d\xc39;\x14\x85\xb6(', 'keyId': 6642569842735972353}}, 'updatedExisting': True}
Process finished with exit code 0
Notice the ’ok’: 1.0 meaning that the update was successful and ’n’: 1, ‘nModified’: 0 indicating that one record was added and no others modified.
13. In your browser, go back to the MongoDB web interface14. Choose user-visits under Clusters on the left navigation bar15. Choose Collections tabYou should see something like this


Run it again and you will see that the EventCount : 1 which is the expected behavior.
Creating the GET Method
Let’s now add another two method called query_mongo_by_entityid() and query_mongo_by_entityid_date() to class MongoRepository
def query_mongo_by_entityid(self, entity_id):results = self.event_collection.find({'EventId': entity_id})print("Query: %s found: %d document(s)" % (entity_id, results.count()))return dumps(results.sort("EventDay", pymongo.ASCENDING))
def query_mongo_by_entityid_date(self, entity_id, entity_date):entity_id = {'EventId': entity_id, 'EventDay': {"$gt": int(entity_date)}}results = self.event_collection.find(entity_id)print("Query: %s found: %d document(s)" % (entity_id, results.count()))return dumps(results.sort("EventDay", pymongo.ASCENDING))
query_mongo_by_entityid()queries MongoDB byEventIdand sorts the results byEventDayin ascending order.query_mongo_by_entityid_date()queries MongoDB byEventIdand forEventDategreater than the specified parameter, and sorts the result byEventDayin ascending order.
Creating the POST Method
Let’s now add another method called upsert_mongo_event_counter_json() to class MongoRepository
def upsert_mongo_event_counter_json(self, event_data):entity_id = {'EventId': event_data.get('EventId', ''),'EventDay': int(event_data.get('EventDay', 0))}if event_data.get('EventId', '') != '':self.event_collection.update_one(entity_id,{"$inc":{"EventCount":event_data.get('EventCount',1)}},upsert=True).raw_resultelse:print("No EventId, skipping record")
and call it in the main with
def main():print(mongo_repo.upsert_mongo_event_counter_json(event_sample))
you will now see that the EventCount : 2 run it again and you will see that the EventCount will increase by 1. This is because the $inc increments the EventCount by the EventCount value in the event_sample dict if it is specficied otherwise it defaults to 1.
Creating the DELETE Method
Finally we need a method to delete the data too.
def delete_mongo_event_counter_json(self, entity_id):return dumps(self.event_collection.delete_many({'EventId': entity_id}).deleted_count)
Here we chose to delete the records that match the given entity_idparameter.
We now know how to connect locally and update records in MongoDB, lets now create the Lambda function with the same Mongo CRUD code as well as additional code needed for parsing the request, forming the response, and controlling the execution flow based on the HTTP Method. Before that let’s create the Role and policies needed by the Lambda.
Creating the Serverless Configuration
I assume that you have AWS CLI installed and with the keys, and if you have to be on Windows you are running a Linux Bash shell. You also have Python 3.6+ setup.
Creating Environment Variables
First I create config file called common-variables.sh for storing all the environment variables. I like to do this is later on I can configure these in a CI/CD tool and it makes it easier to port to different AWS accounts.
Here I determine the AWS Account ID using the CLI, but you can also hardcode it as shown in comments, you can do the same with the region. You will also see that I have some Layers variables we will be using shorty to create the layer with the MongoDB packages that the Lambda will need for CRUD access to MongoDB.
Creating a Lambda Execution Role
First lets create a Lambda IAM Role than will allow the Lambda to write to CloudWatch.
Create a file called assume-role-lambda.json with the following JSON content
Then we create a shell script called create-role.sh with the following
Here we create a new Role called lambda-mongo-data-api with the AWS Managed Policy AWSLambdaBasicExecutionRole attached. This will allow us to store the logs in CloudWatch for any debugging and monitoring.
Run the shell script with ./create-role.sh to create the Lambda execution role and attach the policy.
Creating the SAM Template
AWS Serverless Application Model (SAM) is a framework that allows you to build serverless applications on AWS, that includes creating IAM Roles, API Gateway and Lambda resources. I prefer SAM over other popular frameworks like Serverless which is the frontrunner, as SAM is supported by AWS and not based on node.js but Python. It uses SAM Templates to define the serverless applications and uses AWS CLI to build and deploy it, which is based on CloudFormation.
Create a file called lambda-mongo-data-api.yaml with the following
From top to bottom, I first define the type of SAM template with a description, then we define a set of parameters that are passed in at deploy time from common-variables.sh. If the values are no passed in then they fall back to a default value:* PythonVersion default to python3.6* AccountId to the default value specified as 000000000000* AWSRegion the region* LayerName the name we will give to the layer* LayerVersion as each layer has a version each time you publish a new versionEach of these parameters is a placeholder that is replaced in the YAML with the [!Sub](https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/intrinsic-function-reference-sub.html) CloudFormation function.
We then have the CORS settings, Lambda configuration handler, code, name and other settings.
Then use the IAM Role we just created. I prefer to create the Roles separate from SAM as they can be reused more easily as they will not get deleted with the serverless stack. I also have an environment variable called demo. I’m then listing the full GET POST PUT DELETE methods explicitly for security reasons, but you could shorten it to Method: ANY.
Creating the Lambda Function
Next lets create the Lambda function called lambda_crud_mongo_records.py with the following:
There are three classes here from top to bottom.
* The class HttpUtils is a set of utility methods for parsing the query string, body and returning a response.* The class MongoRepository we talked about earlier which abstracts and centralizes all the MongoDB interactions.* The class Controller controls the main flow and calls different Mongo methods based on the method, request parameters, and request body. Here the methods are GET, DELETE, POST and PUT. For the GET method there are two types of queries we can do on Mongo depending if a startDate is provided or not.
I’ve coded most of it defensively, so things like dealing with invalid JSON and non-numbers in the request, will not bring down the Lambda.
Creating the Packages
Once deployed to AWS, the Lambda will need the Python dependent packages pymongo, dnspython and bson.These need to be packaged and deployed for it to work. There are two ways this can be done. The first is using a virtualenv to create the dependent packages and add the Lambda code, and compress them all together as a Zip package. The second and newer way, is the use Lambda Layers which is to have one package with the dependent packages as a Zip, and another one for the Lambda source code itself.
Create a Layer with MongoDB Depend Packages
What are Layers? They were introduced at RE:Invent 2018 and one of the most useful features for Lambda package and dependency management. In the past any non standard Python library or boto3 packages, had to be packaged together with the Lambda code. This made the package larger than it needed to be and also prevented reuse between Lambdas. With Layers any code can be packaged and deployed separately from the Lambda function code itself. This allows a layer to be reused for different Lambdas and for a smaller Lambda package with your code. Each Lambda function supports up to 5 Layers allowing you to abstract 3rd party dependency packages but also your own organization’s code.
Here lets create a package with the three dependent Python packages we need for the Lambda to connect and perform CRUD operations on MongoDB.
Create a file called lambda-requirements.txt with the following
bson>=0.5.6dnspython>=1.15.0pymongo>=3.6.1
this contains the dependent packages that will be packaged in the Layer. I’ve added this as I don’t want to include other testing packages that are not needed which are in the requirements.txt.
Create a script called create-dependent-layer.sh with the following
All the environment variables are created from the `common-variables.sh` shell script we ran above.
This script first creates a virtualenv and installs the packages we specified in the lambda-requirements.txt using pip3 several options to minimize the amount of code and time it takes to install the dependent packages we are after.
The script then copies the dependent packages installed the a virtualenv into a directory ${packages_path}/${python_version}/site-packages/ which here is ../../build/python3.6/site-packages/ folder. Here I list the package folders explicitly as I found that sometimes the packages you pip install have different folder names so get missed out. For example the package dnspython is actually stored under the dns folder and not dnspython like you would expect. I iterate over a list ${packages_array[@]} of packages and use rsync to copy the files and directories. Note that for the Layer to work it need to follow a directory convention as shown here:


Lambda Layers Folder Structure and Build
The convention for the Python3.6 folder structure is python/lib/python3.6/site-packages/.
We then create the Zip archive with packages. Here the ${target_package_folder#../} is used to strip off the leading ../ prefix as we only want to go up one level, and create the Zip archive under the package folder. This create a mongodb-layer.zip archive with the 3rd party packages in the correct folder structure python/lib/python3.6/site-packages/.
We then copy the Zip archive to S3 using aws s3 cp so that it can be used added as a Layer.
Finally we run aws lambda publish-layer-version to publish this as a layer, again using the environment variables we created in the common-variables.sh.
Run the script ./create-dependent-layer.sh to create the mongodb-layer.zip
You will notice that each time you run this script, it will create a new Layer Version. The current version that the Lambda will use is specified in the common-variables.sh.
There are other ways to create the packages used in a Layer such as using a docker container or EC2, but essentially the process is similar also using virtualenv and pip. At moment of writing AWS only has a SciPy available, but I expect more to be added in the future.
Now that we have the Layer we need to build the Lambda archive.
Create a Package with Lambda
We then Zip the Lambda and packages using create-lambda-package.sh
Here we create a Zip archive of the two python scripts lambda_crud_mongo_records.py which has the Lambda code and mongo_config.py which has the MongoDB credentials.
Run the script ./create-lambda-package.sh to check that the Zip archive get created.
We now have a Zip file with both the Lambda as lambda-mongo-data-api.zip and it’s 3rd party dependent packages as reusable Layer mongodb-layer.zip that has already been deployed. This layer can be used by any other Lambda in the account! Lets now look at how we can deploy API Gateway and the Lambda function using SAM.
Alternatively you can have SAM create the Zip file, but I prefer to control this process as for example a CI/CD step could create the Zip as an artifact that could be rolled back, and you could also introduce further optimizations to reduce the size or use byte code for example.
Building and Deploying the Serverless Microservice
Now that we have the Zip packages, either as one fat Zip with the Lambda and it’s 3rd party packages (as it would have been done in 2018 prior to AWS RE:Invent), or one Lambda Zip archive and one Zip for the Layers that we already deployed, lets deploy the full stack.
Building and Deploying the Lambda and packages as one Zip
Here are the contents of shell script build-package-deploy-lambda-mongo-data-api.sh
* aws cloudformation package packages the artifacts that the AWS SAM template references, creates a `lambda-mongo-data-api-output.yaml` template and uploads them to S3.* aws cloudformation deploy deploys the specified AWS SAM / CloudFormation template by creating and then executing a change set. Here that is the API Gateway and Lambda function. You can see that I can passing in some parameters that we saw earlier in the SAM YAML Template: AccountId, LayerName, LayerVersion, PythonVersion which we specified in the common-variables.sh.
Now we just need to run the script to create the Lambda Zip, package, and deploy it along with the API Gateway.
$ ./build-package-deploy-lambda-mongo-data-api.sh
Testing the Deployed API
Now that you understand how to deploy the serverless stack and you could test the API Gateway and Lambda in the AWS Management Console or do automated testing on the API or Lambda, but here let’s focus on using an API testing tool called Postman to manually test it is behaving as expected. For the GET or DELETE methods we could use the browser, but we need a tool like Postman or insomnia because to test the PUT and POST methods we need to provide a JSON Body in the request.
1. Sign in to the AWS Management Console and open the API Gateway console2. Choose Stages under APIs/apigateway-dynamo in the Amazon API Gateway navigation pane3. Select PUT under Prod/visits/PUT to get the invoke URL * The invoke URL should look like `https://{restapi_id}.execute-api.{region}.amazonaws.com/Prod/visits` * We will use the invoke URL next4. Download and install Postman5. Launch Postman6. Choose Request from Building Blocks or New > Request from the menu7. In new Save Request Window * In request name Type put-api-test * In Select a collection or folder to save to: Type api-test * Choose Create Collection “api-test” and select it in the list * Choose Save to api-test
Testing the Deployed API PUT Method
1. Open a New Postman Tab2. Choose PUT from the methods dropdown3. In Enter Request URL type your deployed PUT URL, e.g. `https://vjp3e7nvnh.execute-api.eu-west-1.amazonaws.com/Prod/visits` * Choose PUT under APIs > user-comments > Stages4. Choose Body tab5. In the row under body select raw from the radio buttons and JSON (application/json) to it’s right6. Type the following
{"EventId": "2011","EventDay": "20171013","EventCount": 2}
7. Choose Send8. Check the response body, if it is {“n”: 1, […] then it has been added otherwise you will get an exception message, check the URL, JSON body and method is correct.9. Choose Send again twice, this should have no effect lets now look at the GET response.
Testing the Deployed API GET Method
1. Open the same tab in Postman2. Change the method to GET3. Append /2011 to the URL4. Choose Send
You should get the following response body:
[{"_id": {"$oid": "5c3281a1b816a500d6a85afc"},"EventDay": "20171013","EventId": "2011","EventCount": 2}]
With the PUT method, the EventCount value remains constant no matter how many times you call it, what is known as an idempotent operation.
Testing the Deployed API POST Method
Now let’s test the POST method that increments a counter by the specified value each time it is called, i.e. not idempotent operation. This could be useful for implementing counters such as real-time page views or scores.
1. Open the same tab in Postman2. Change the method to POST3. Remove /2011 from the URL * Like the original PUT URL4. Choose Body tab5. In the row under body select raw from the radio buttons and JSON (application/json) to it’s right6. Type the following:
{"EventId": "2011","EventDay": "20171013","EventCount": 2}
7. Choose Send8. Choose GET on the left and Send
[{"_id": {"$oid": "5c3282c6b816a500d6a88210"},"EventDay": 20171013,"EventId": "2011","EventCount": 4}]
Run it several times and you will see EventCount increment, you can also increment it by less or more than 2 if you modify the request JSON body EventCount value.
Testing the Deployed API DELETE Method
1. Open the same tab in Postman2. Change the method to DELETE3. Append /2011 to the URL (like the GET)4. Choose Send
You can also check MongoDB Console and you will see that there are no records
1. Open the MongoDB Console2. In the navigation Select Clusters3. In the Overview tab select user-visits4. In user-visits select Collections5. Under Namespace choose Dev > user-vists * Mongo will run a query6. You should get Query Results 0
Cleaning up
As we have used SAM to deploy the serverless API, to delete it simply run ./delete-stack.sh here are the contents of the shell script:
The aws cloudformation delete-stack deletes API Gateway and Lambda. The Layers are deleted one at a time with the for loop. Here the ${layer_version} is fixed from the environment variables declared in common-variables.sh but could easily be made dynamic by finding the current layer version.
1. Open the MongoDB Console2. In the navigation Select Clusters3. In the Overview tab select user-visits4. In user-visits select Collections5. Next to Dev > user-vists select Delete Icon6. In the Drop Collection window type `user-visits`
Final Remarks
Well done you have deployed a serverless microservice with a full CRUD RESTful API with a MongoDB NoSQL backend. We have used the newly released Layers to package the MongoDB dependencies and tested it using Postman. I will be adding the full source code on GitHub shortly.
If you want to find out more on Serverless microservices and have more complex use cases, please have a look at my video courses and so support me in writing more free technical blog posts.
Additional implemented Serverless pattern architecture, source code, shell scripts, config and walkthroughs are provided with my video courses. For beginners and intermediates, the full Serverless Data API code, configuration and a detailed walk through


Building a Scalable Serverless Microservice REST Data API Video Course
For intermediate or advanced users, I cover the implementation of 15+ serverless microservice patterns with original content, code, configuration and detailed walk through.

Implementing Serverless Microservices Architecture Patterns Video Course
Feel free to connect and message with me on LinkedIn Medium or Twitter.











