










Keeping chaos at bay in the distributed world, one cluster at a time


What a Kafka Controller’s job feels like
Introduction
Kafka is an ever-evolving distributed streaming platform. It is the current go-to solution for building maintainable, extendable and scalable data pipelines. If you are not too familiar with it, make sure to first check out my other article — A Thorough Introduction To Apache Kafka.
Continuing from that article, I thought it would be beneficial if we took a bit more time to dive into some of the internal workings of Kafka itself.
Today I want to introduce you to the notion of a controller — the workhorse node of a Kafka cluster — the one who keeps the distributed cluster healthy and functioning.
Controller Broker
A distributed system must be coordinated. If some event happens, the nodes in the system must react in an organized way. In the end, somebody needs to decide on how the cluster reacts and instruct the brokers to do something.
That somebody is called a Controller. A controller is not too complex — it is a normal broker that simply has additional responsibility. That means it still leads partitions, has writes/reads going through it and replicates data.
The most important part of that additional responsibility is keeping track of nodes in the cluster and appropriately handling nodes that leave, join or fail. This includes rebalancing partitions and assigning new partition leaders.
There is always exactly one controller broker in a Kafka cluster.
Duties
A Controller broker has numerous extra responsibilities. These are mainly administrative actions, to name a few — create/delete a topic, add partitions (and assign them leaders) and deal with situations in which brokers leave the cluster.
Handle a node leaving the cluster
When a node leaves the Kafka cluster, either due to a failure or intentional shutdown, the partitions that it was a leader for will become unavailable (remember that clients only read from/write to partition leaders). Thus, to minimize downtime, it is important to find substitute leaders as quickly as possible.
A Controller is the broker that reacts to the event of another broker failing. It gets notified from a ZooKeeper Watch. A ZooKeeper Watch is basically a subscription to some data in ZooKeeper. When said data changes, ZooKeeper will notify everybody who is subscribed to it. ZooKeeper watches are crucial to Kafka — they serve as input for the Controller.
The tracked data in question here is the set of brokers in the cluster.
As shown below, Broker 2’s id is deleted from the list due to the expiry of the faulty broker’s ZooKeeper Session (Every Kafka node heartbeats to ZooKeeper and this keeps its session alive. Once it stops heartbeating, the session expires).
The controller gets notified of this and acts upon it. It decides which nodes should become the new leaders for the affected partitions. It then informs every associated broker that it should either become a leader or start replicating from the new leader via a LeaderAndIsr request.


Handle a node re-joining the cluster
Correct partition leader placement is critical for load balancing of the cluster. As shown, in the event of failures, some nodes take over and become leaders for more partitions than they originally were. This places additional load on each broker and undermines the performance and health of the cluster. As such, it is beneficial to restore balance as soon as possible.
Kafka assumes that the original leader assignment (when every node was alive) is the optimal one that results in the best balanced cluster. These are the so-called preferred leaders — the broker nodes which were the original leaders for their partitions. Since Kafka also supports rack-aware leader election (where it tries to position partition leaders and followers on different racks to increase fault-tolerance against rack failures), leader placement can be tightly tied to cluster reliability.
By default (auto.leader.rebalance.enabled=true), Kafka will check if the preferred leader replica is not the current leader and, if it’s alive, try to elect it back.


The most common failure case of broker failures is transient, meaning brokers usually recover after a short while. This is why when a node leaves the cluster, the metadata associated with it is not deleted and the partitions it is a follower for are not reassigned to new followers.
When the controller notices that a broker joined the cluster, it uses the broker ID to check if there are partitions that exist on this broker. If there are, the controller notifies both new and existing brokers of the change. The new broker starts replicating messages from the existing leaders, once again.
Since the Controller knows the re-joined broker’s past partitions, it will attempt to reassign leadership back to the broker in order to optimally balance the cluster.
Note, though, that the rejoined node cannot immediately reclaim its past leadership — it is not eligible yet.
In-sync replicas
An in-sync replica (ISR) is a broker which has fully caught up to a partition it is following. In other words, it cannot be behind on the latest messages for a given partition. Partition leaders themselves are responsible for keeping track of which broker is an ISR and which isn’t. They store said state in ZooKeeper.
It is very important to have a sufficient amount of in-sync replicas online at all times. Kafka’s main availability and durability guarantees rely on data replication.
For a follower broker to be promoted to a leader, it must be an in-sync replica. Every partition has a list of in-sync replicas and that list is updated by partition leaders and the controller.
The process of electing an in-sync replica as a partition leader is called clean leader election. Users can opt-out of it if needed, choosing availability over consistency by electing out of sync replicas in some edge cases where no in-sync replicas are alive and the has leader died.
Remember that clients only produce to and consume from partition leaders — if we elected a leader with stale data it would cause the cluster to lose messages! Not only would we lose messages, but we could have conflicts in the consumers since the lost messages’ offsets will be taken by newer messages.
Unfortunately, this conflict might still be a possibility even with clean leader election_(hint: it’s not, but more on that later)_. Even an in-sync replica is not fully in-sync. By that I mean that if a leader‘s last message has an offset of 100, an in-sync replica might very well not have it yet. Said replica might be up to 95, 99, 80 — depending on multiple factors. Since the replication is done asynchronously, it is impossible to guarantee that a follower is up to the very latest message.
The criteria for considering a partition follower in-sync with its leader is the following:
- It has fetched messages from the partition leader in the last X seconds. (configurable through
replica.lag.time.max.ms). It is not enough to fetch any messages — the fetch request must have requested all messages up to the leader log’s end offset. This ensures that it is as in-sync as possible. - It has sent a heartbeat to Zookeeper in the last X seconds. (configurable through
zookeeper.session.timeout.ms)
Inconsistent durability?
Apparently, there is now a possible sequence of events in which a leader dies, an in-sync replica is elected as its replacement and we lose a small amount of messages. For example, if a leader saves some new records right after it responds to a follower’s fetch request, there will be a time frame in which those new messages will not have been propagated to the follower yet. If the leader happens to die within that time frame, the replica would still be considered in-sync (perhaps X seconds have not passed yet) and would be elected as the new leader.


Producer’s acks setting
In the example above, the leader broker acknowledges a producer’s write after it has saved it locally (producer has set acks=1). The broker happens to crash right after it has acknowledged the new message.Since Broker 2 is an ISR, the controller will elect it as the new leader for Partition 1 even though it lacks the newest message with offset 100.
This is theoretically avoidable if we use the configuration setting acks=all, which means that the leader broker will only acknowledge messages once all the in-sync followers (ISRs) have successfully replicated the messages themselves. Unfortunately, this setting results in a bit less performant cluster — it limits maximum throughput. The partition leader can only acknowledge the write once it knows that the followers have replicated the message. Since replication uses a pull model, it can only know for sure that the message is saved on the second received follower request. This, in turn, makes the producer need to wait more time before sending the next batch of messages.
Some Kafka use cases would rather have the added performance of not waiting for replicas and opt out of the aforementioned setting.
So what happens if we don’t want to set acks=all? Will we lose messages? Won’t some consumers read data which gets lost?
Long story short — no, that won’t happen. Some produced messages might get lost, but they will never make it to the consumer. This ensures consistency across the end-to-end system.
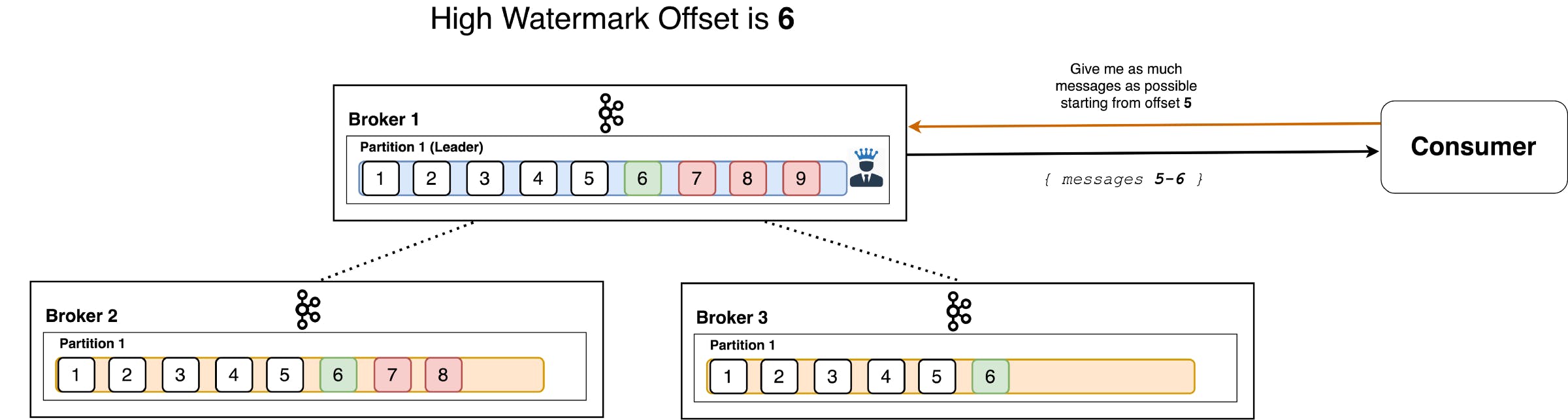
High Watermark Offset
Leader brokers never return messages which have not been replicated to all ISRs. Brokers keep track of the so-called high watermark offset — the largest offset which all in-sync replicas have. By returning messages no greater than the high watermark to the consumer, Kafka ensures that consistency is maintained and that non-repeatable reads cannot happen.

Split Brain
Imagine a controller broker dies. The Kafka cluster must find a substitute, otherwise it can quickly deteriorate in health when there is nobody to maintain it.
There is the problem that you cannot truly know whether a broker has stopped for good or has experienced an intermittent failure. Nevertheless, the cluster has to move on and pick a new controller. We can now find ourselves having a so-called zombie controller. A zombie controller can be defined as a controller node which had been deemed dead by the cluster and has come back online. Another broker has taken its place but the zombie controller might not know that yet.
This can easily happen. For example, if a nasty intermittent network partition happens or a controller has a long enough stop-the-world GC pause — the cluster will think it has died and pick a new controller. In the GC scenario, nothing has changed through the eyes of the original controller. The broker does not even know it was paused, much less that the cluster moved on without it. Because of that, it will continue acting as if it is the current controller. This is a common scenario in distributed systems and is called split-brain.
Let’s go through an example. Imagine the active controller really does go into a long stop-the-world GC pause. Its ZooKeeper session expires and /controller znode it registered is now deleted. Every other broker in the cluster is notified of this as they placed ZooKeeper Watches on it.


To fix the controller-less cluster, every broker now tries to become the new controller itself. Let’s say Broker 2 won the race and became the new controller by creating the /controller znode first.
Every broker receives a notification that this znode was created and now knows who the latest leader is — Broker 2. Every broker except Broker 3, which is still in a GC pause. It is possible that this notification does not reach it for one reason or another (e.g OS has too many accepted connections awaiting processing and drops it). In the end, the information about the leadership change does not reach Broker 3.


Broker 3’s garbage collection pause will eventually finish and it will wake up still thinking it is in charge. Remember, nothing has changed through its eyes.


You now have two controllers which will be giving out potentially conflicting commands out in parallel. This is something you obviously do not want to happen in your cluster. If not handled, it can result in major inconsistencies.
If Broker 2 (new controller node) receives a request from Broker 3, how will it know whether Broker 3 is the newest controller or not? For all Broker 2 knows, the same GC pause might have happened to it too!
There needs to be a way to distinguish who the real, current controller of the cluster is.
There is such a way! It is done through the use of an epoch number (also called a fencing token). An epoch number is simply a monotonically increasing number — if the old leader had an epoch number of 1, the new one will have 2. Brokers can now easily differentiate the real controller by simply trusting the controller with the highest number. The controller with the highest number is surely the latest one, since the epoch number is always-increasing. This epoch number is stored in ZooKeeper (leveraging its consistency guarantees).


Here, Broker 1 stores the latest controllerEpoch it has seen and ignores all requests from controllers with a previous epoch number.
Other responsibilities
The controller does other, more boring things too.
- Create new partitions
- Create a new topic
- Delete a topic
Previously, these commands could only be done in a whacky way — a bash script which directly modified ZooKeeper and waited for the controller broker to react to the changes.Since version 0.11 and 1.0, these commands have been changed to be direct requests to the controller broker itself. They are now easily callable by any user app through the AdminClient Api which sends a request to the controller.
Summary
In this short article, we managed to completely explain what a Kafka Controller is. We saw that it is a simple broker that still leads partitions and processes writes/reads but has a few additional responsibilities.
We went through how the Controller handles nodes that become unresponsive. First, in realizing a node is unresponsive via a ZooKeeper Watch on that node’s ZooKeeper Session expiring, then by picking new partition leaders and lastly, propagating that information by sending LeaderAndIsr requests to the rest of the brokers.
We also went through how the Controller welcomes nodes back into the cluster and what it does to eventually restore balance to the cluster. We introduced the concept of an in-sync replica and saw that Kafka ensures end-to-end consistency via a high watermark offset.
We learned that Kafka uses an epoch number to prevent a “split brain” scenario where two or more nodes believe they are the current controller and illustrated how that works step by step.
Kafka is a complex system that is only growing in features and reliability due to its healthy community. To best follow its development, I’d recommend joining the mailing lists.
Thanks for taking the time to read through this article!
If, by any chance, you found this informative or thought it provided you with value, please make sure to give it as many claps you believe it deserves and consider sharing with a friend who could use some extra knowledge about Kafka.
If, by another chance, you’re fascinated by the work that goes into Kafka, we at Confluent are hiring across the board. Feel free to message me to further understand what we’re building and why you’ll love working here.
~Stanislav Kozlovski













