








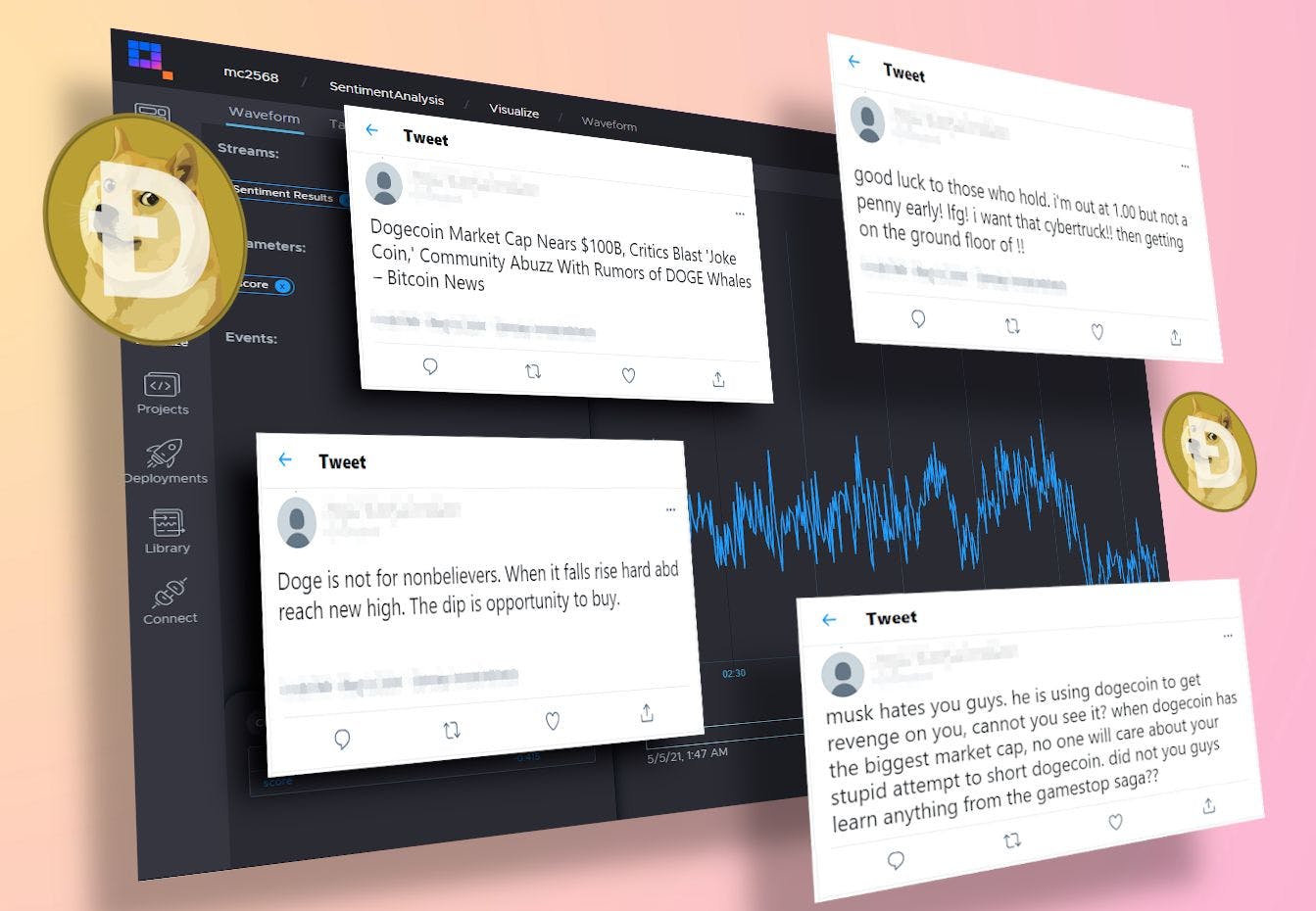

Setting up a scalable streaming analytics pipeline is notoriously difficult, especially if you’re trying to incorporate a machine learning model. But I was able to do it in 30mins with a tool called Quix. Before I go into the details about what I did, let’s first look at the end result.


It’s a stream of Tweets about Dogecoin that were being assessed in real-time in the run-up to Elon Musk’s much-awaited SNL appearance. Like every other tech journalist and crypto market observer, I was interested in how much influence his appearance would have on the sentiment towards this meme coin.
The real-time price fluctuations are easy for anyone to observe in trading platforms like Coindesk, but I want to create my own utility to measure the real-time sentiment fluctuations. And yes, I know there are also plenty of tools that measure crypto sentiment too, such as the Bison Crypto raider and the “Fear and Greed” index.


But tools like these require a bit of time and expertise to set up. I wanted to see how easy it would be for yours truly….who only knows a smattering of code…to get up and running.
And as the title suggests, it was surprisingly easy. Once I had the code ready and was done with the busy work of creating developer accounts, it took me about 30mins.
I picked Dogecoin because it was a great opportunity to showcase streaming analytics (I’m not especially interested in Dogecoin or Elon Musk per see).
The Tweet analysis showcased, in real-time, the influence that a pop-culture occurrence has on public sentiment — just like those graphs that they show during political debates.
More importantly, it showcases how tools like Quix are rapidly democratising the streaming analytics space. A space that’s been previously out of reach to those who didn’t have the expertise to set up the underlying technologies like Kafka and Kubernetes.
OK, but what’s Quix?
Quix is an end-to-end platform for developers of data and event-driven products. It features a very simple UI that lets you create “topics” which are kind of like storage buffers for incoming data feeds. You can create a project that lets you read and write to different topics, run your project in its own environment and then visualize the result. There are other tools that kind of let you cobble together a similar pipeline, but nothing that pulls everything together in one platform.
Naturally, this point is easier to prove if I just show you, so let’s get to it
First, set up your Twitter and Quix developer accounts
I find that tutorials often gloss over how long it takes in setting up accounts. If you don’t already have a Twitter developer account, it might be an hour or two before you can get to the Twitter part of this tutorial. Getting a Twitter developer account isn’t complicated but can take a while for them to approve your application.
The Quix sign up, on the other hand, takes only a few minutes. So you can do the Quix-specific tasks while you’re waiting for your Twitter application to be approved.
- Sign up for a developer account on the Twitter developer portal.
- Sign up for a free account on the Quix platform.
An overview of the steps
I’ll be guiding you through the following major tasks in the Quix platform
- Create your workspace
Basically, this is like a folder that stores your different projects and code. - Create your topics
One topic to store the incoming Tweets from the Twitter stream.
Another topic to store incoming sentiment scores that we’ll calculate. - Create your projects
One project for the code that reads from the Twitter API and writes to the “Tweets” topic
Another project for the code that calculates the sentiment scores for each Tweet and writes the scores to the “Scores” topic
Deploy your projects to run in the cloud as Quix services
Deploy the Twitter code to continuously stream in the Tweets
Deploy the sentiment analysis code to continuously stream out the scores
We’ll be using code that I’ve prepared for you as a GitHub Gists.
Create your workspace
Once you have your Quix account, log in and create a workspace for this tutorial. Call it “TutorialWorkspace” or something similar.
- Click the ‘NEW WORKSPACE’ tile or the CREATE NEW WORKSPACE button

Create your topics
Once your Tutorial Workspace has been created, click the Topics icon at the bottom of the workspace tile.

- Click the CREATE TOPIC button near the top left of this page.

- Call it “Tweets”, then click CREATE.
- Copy and paste the topic ID somewhere safe. You’ll find it by expanding the topic in the topics table. You’ll need the ID for your code later on.
- Create another topic and call it “SentimentScores”.
This time, turn on the “Persist” toggle. This will persist the data since it would be nice to keep the scores for historical analysis. - Again, paste topic ID somewhere handy.
Create your Projects
Your two projects are going to store the code for the tweet streaming and the sentiment analysis respectively.
- In the left-navigation click Projects and then click CREATE PROJECT.

- Name your project “ReadTweetStream” and leave the language as Python.
- Follow the same process and create another project — call it “CalculateSentimentScore” — again, leave the language as Python.
Set up the “ReadTweetStream” Project
Open the ReadTweetStream project you just created and take a closer look.

You’ll see that a “project” in fact is a little IDE where you can update the code and clone it to your local machine. But let’s not try that just yet.
First things first, let’s look at the boilerplate code that has already been generated for you.
You’ll find that boilerplate code in main.py. Copy all that and paste it somewhere safe. It contains values for variables in our tutorial code. You’ll need to replace placeholders with these values.
Now, let’s go and get the Twitter streaming code. It’s over here in this Gist.
In your project, copy and paste the code from the Gist into main.py.
Before we go any further, let’s quickly take a closer look at the API we’ll be using.
About Twitter’s Streaming API
Twitter offers an API endpoint called “Filtered Stream” that can continuously stream tweets. In the free tier, you only get a subset of all tweets but that’s enough for our purposes. We’re going to filter them anyway, by some specific criteria.


However, it’s important to remember that you can’t pull any more than 500k Tweets per month. I hit that limit faster than I expected because everyone was ranting about Dogecoin in the lead-up to SNL. So it depends on what your filter criteria are.
Incidentally, when signing up for your developer account, you might have noticed a couple of similar tutorials in Twitter’s own documentation:
- There’s one for streaming tweets in real-time.
- And another for analyzing Tweet sentiment using Microsoft Azure’s Text Analytics Cognitive Service.
But don’t get too excited, those tutorials are fine and good, but they’re two separate tasks. This tutorial is going to show you how to do both, together (without making you sign up with Microsoft Azure and wade through their documentation). Anyway, let’s continue…
Add your Twitter-specific variables to the project
Once you have an approved Twitter Developer account (that’s authorized to use the new V2 APIs), go ahead and note down your bearer token. You’ll need it for the next step. If you’re not sure how to get it, follow Twitter’s quick start to set up an app in their developer portal
We’re going to add the bearer token and the search query as environment variables to our project.
- In your project, click VARIABLES, and add the following variables in the window that appears.
:bearer_tokenREPLACE_WITH_YOUR_BEARER_TOKEN
: (twitter_search#dogecoin OR #Doge OR DOGE OR dogecoin)-is:retweet lang:en
If you want to use a different Twitter search, make sure you check out Twitter’s search operator's documentation first.

Make sure that you use the exact variable names that I’ve provided because the code is expecting them.
Now, remember that boilerplate code I asked you to copy when you first created this project? Time to go and retrieve it, along with the topic ID that you also copied.

- Replace the placeholder
with the topic ID that you copied earlier.THE_TOPIC_ID_TO_WRITE_TO - OK, click SAVE and you’re done with main.py.
Next, you need to configure the dependencies that your project needs to run. Luckily, there are only two.
- Click Requirements.txt and add the following items to the list, then click SAVE.
requests
pandas
Finally, in the Commit Messages panel on the right-hand side, give your latest changes a tag. I called mine “TwitterDoge” — this makes it easier to tell what snapshot to deploy.

- Then open that menu again and click DEPLOY.
- In the deploy options window that appears, select the tag that you just created, and change the deployment type to Service and click DEPLOY.

If all goes well, you should see your deployment show up in the deployments table and start to build. Once it’s running, check the logs to see all those lovely tweets streaming in.
- In the deployments table, mouse over your deployment and click Logs. Nice work! Now let's try and quantify the sentiment of those Tweets.

Nice work! Now let's try and quantify the sentiment of those Tweets.
Which leads to the second phase of our exercise.
Set up the “Sentiment Analysis” Project
To calculate the sentiment score, we’re going to use the wonderfully user-friendly Transformers library from HuggingFace. If you haven’t heard of it, it’s a machine learning library that makes it extremely easy to train and use machine learning models for general NLP tasks.
In this tutorial, we’ll initialize the sentiment analysis pipeline. As part of the initialization, the Transformers library will automatically select and download the appropriate pretrained model.
The first part of this process is pretty similar to the last section.
- In the Quix platform, open the SentimentAlaysis project you created previously.
- Just like before, copy the boilerplate code that Quix generates into notepad for safekeeping.
- Copy and paste the sentiment analysis code from this second Gist.
This time, you need to set just one environment variable, “max_samples”. This affects the average score, which is a rolling window that averages the scores of the “X” previous tweets. When I ran it, I decided to average the last 50 tweets, so my default value was 50.

As before, you need to configure the dependencies that your project needs to run. This time we have a few more:
transformers[torch]
bs4
emoji(We‘re using beautiful soup and the emoji library to preprocess the tweets.)
- Tag your latest commit like you did with the first project.
- Open that same menu again and select DEPLOY again.
In the New Deployment window that appears, you’ll need to make one extra configuration. To recap, these are the changes you should make:
- Select your tag.
- Change the type from Job to Service.
- In the Memory in Mb field, type 1000 (don’t use the slider, it only goes up to 500).
The transformers model needs a lot of memory which is why we’re cranking it up so high.
Again, click DEPLOY and cross your fingers. Once the status changes to Running, it’s time to check the logs. You should start to see the scores rolling in:

Now, there’s just one last thing left to do: Visualize the scores
Visualizing the Sentiment Scores as they come in
It’s a little tricky to get a handle on the sentiment fluctuations just by looking at a set of numbers, so let’s set up the rolling graph that I showed at the beginning of this article.
In the left-hand side nav, Navigate to Data and you should see the Sentiment Results stream in the list of streams. Hover over the row and click the Visualize button.

You’ll be taken to the Visualize section where you can select the parameters (data points) that you want to visualize (as a waveform or as a table).

You can also click the LIVE button and click + to zoom in on the stream and watch the data coming in real-time.
And that’s about it! Hopefully, you can see how easy it is to set up a project that uses streaming data.
Quix dramatically simplifies the process of working with data streams
To appreciate how difficult such a task would be without Quix, check out one of the tutorials that inspired this one (and from which I used some of the tweet-processing code).

Tutorial for setting up a sentiment analysis service using Flask and ElasticBeanstalk
It’s an older tutorial on how to do sentiment analysis on Tweets with the FastText library.
The second part of the tutorial shows you how to deploy a sentiment analysis service with Flask and AWS ElasticBeanstalk. It’s a lot more complex, even though ElasticBeanstalk is supposed to be the “simple” way to deploy apps.
Plus, it doesn’t even show you how to set up the streaming part. It’s just a service that will evaluate any text that you send it.
Or check out the Confluent quick start for Apache Kafka. Confluent is a managed service that’s designed to make Kafka more accessible to wider audiences, but the procedure is still considerably more complex. It would take me a lot longer to reproduce what I’ve just shown you here.
The beauty of the Quix platform is that it abstracts away a lot of the complexity and decisions that need to be made when working with Kafka or data streams in general.
Democratizing access to real-time analytics
When I set up this tutorial, I had an “aha” moment. I had always wanted to experiment with Kafka and data streams, but I found the set up simply too intimidating.
I’ve been waiting for a tool that would democratize access to real-time analytics in the same way that Google’s Teachable Machine or RunwayML made machine learning more accessible to a wider audience. Quix still requires a bit of coding know-how, but it’s the closest thing I’ve seen so far to the tool I’ve been hoping for.
Anyone with a general knowledge of coding: data scientists, back-end engineers, and tinkerers like me can now deploy an application that does something useful with data streams. You no longer need to be a Kafka specialist.
If you’re an early-stage startup, this is a godsend. You might have a small team who needs to multitask and get involved in several different aspects of your operations. Quix is simple enough that anyone from your Business Intelligence team can set up streaming analytics — without involving a data engineer (if you’re lucky enough to have one).
The possibilities are endless
My use case of tracking currency data is a pretty typical use case. Especially, for crypto which is extremely volatile and changes by the minute. Like when Elon Musk admits that Dogecoin was a “hustle” on SNL and its value plummeted (or was it the Hospital Generation Z skit that did it?). In that case, the value of real-time data is obvious.
But there are so many other use-cases that the platform could address. For example, you could keep a predictive machine learning model trained on up-to-date traffic data or transactional data (for fraud detection).
Or you don’t need to involve a machine learning model at all. You could build an event-driven e-commerce platform that emulates the cutting-edge architectures seen at Zalando or Uber. It really depends on the nature of the data you’re dealing with.
I’m excited about what new use cases might emerge when more people have a chance to play with Quix. Sure, I expect a lot of financial apps. But I also expect to see some imaginative and left-field use cases that would have never occurred to me.
That’s generally what happens when you democratize a technology that’s previously had a high entry barrier. So go ahead — try it out, track something more exciting than Dogecoin sentiment. I’d love to see what you come up with.
Full disclosure: I work for the VC that invested in Quix (Project A Ventures). This is how I heard about their product. Nevertheless, I would not have written this tutorial had I not been genuinely enthusiastic about the Quix platform.
Also published behind a paywall at: https://insights.project-a.com/streaming-analytics-just-got-a-whole-lot-easier-b428acae254












