The study of discriminative models is a common entry point into the field of Machine Learning. Discriminative models learn a distribution that defines how one feature of a dataset depends on the others. This distribution can then be used to discriminate between data points by, for example, partitioning a dataset into classes.
In addition to discriminative models, there also exist generative models. Rather than learn a distribution that defines how features of a dataset depend on each other, generative models learn the distribution that generates the features themselves. This distribution can then be used to generate new data that is similar to the training data. Variational Autoencoders, a class of Deep Learning architectures, are one example of generative models.
Variational Autoencoders were invented to accomplish the goal of data generation and, since their introduction in 2013, have received great attention due to both their impressive results and underlying simplicity. Below, you will see two images of human faces. These images are not of real people - they were generated using VQ-VAE 2, a DeepMind Variational Autoencoder (VAE) model.


In this tutorial, we’ll explore how Variational Autoencoders simply but powerfully extend their predecessors, ordinary Autoencoders, to address the challenge of data generation, and then build and train a Variational Autoencoder with Keras to understand and visualize how a VAE learns. Let’s get started!
If you want to jump straight to the code, you can do so here.
Introduction
Generating convincing data that mimics the distribution of a training set is a difficult task, one which harbors several peculiarities that make it a uniquely challenging problem. The task is unsupervised, and it necessitates that we consider the data as representative of a distribution. That is, rather than performing operations on the data points as points in their own right to accomplish some goal that is valuable in its own right, such as clustering with K-Means, we need to determine the underlying structure of the data sufficiently enough that we can exploit it to generate convincing forgeries. Given one-million pictures of human faces, how are we to train a model that can automatically output realistic images of human faces?
Recall that Autoencoders (AEs) are a method of bottlenecking the learning of an identity map in order to find a lower-dimensional representation of a dataset, something that is useful for both dimensionality reduction and data compression. While Autoencoders are a powerful tool for these purposes, their learning objective is not designed to make them useful for generating data that is convincingly similar to a training set.
Variational Autoencoders extend the core concept of Autoencoders by placing constraints on how the identity map is learned. These constraints result in VAEs characterizing the lower-dimensional space, called the latent space, well enough that they are useful for data generation. VAEs characterize the latent space as a landscape of salient features seen in the training data, rather than as a simple embedding space for data as AEs do.
In the following sections, we will first explore how ordinary Autoencoders work, and then examine how they differ from Variational Autoencoders. We will gain an intuition for why these differences result in VAEs being well-suited for data-generation, and finally put our knowledge to practical use by training a Variational Autoencoder to generate images of clothing using the MNIST Fashion dataset! Let's begin by reminding ourselves what an ordinary Autoencoder is.
What is an Autoencoder?
In a wide range of data-adjacent fields, it is often beneficial to learn compressed representations of the data you are working with. You might use these lower-dimensional representations to make other Machine Learning tasks more computationally efficient, or to make data storage more space-efficient. While knowing a compressed representation of a dataset is clearly beneficial, how might we discover a mapping that accomplishes this compression?
Autoencoders are a class of Neural Network architectures that learn an encoding function, which maps an input to a compressed latent space representation, and a decoding function, which maps from the latent space back into the original space. Ideally, these functions are pure inverses of each other - passing data through the encoder and then passing the result through the decoder perfectly reconstructs the original data in what is called lossless compression.

A very convenient fact about Autoencoders is that, given that they are Neural Networks, they can take advantage of specialized network architectures. While there are dimensionality reduction methods that have superseded Autoencoders in terms of popularity, such as PCA and Random Projections, Autoencoders are still useful for tasks such as image compression, where ConvNets can capture local relationships in the data in a way that PCA cannot.
We can use convolutional layers to map, for example, MNIST handwritten digits to a compressed form.

How does the Autoencoder actually perform this compression? The convolutional layers in the network extract the salient features of each digit, such as the fact that an 8 is closed and has two loops, and a 9 is open and has a single loop. A fully connected network then maps these features to a lower dimensional latent space, placing it in this space according to which features are present, and to what degree, in the image. If we are already mapping images to a representative feature space, can we not use this space for image generation?
Can Autoencoders Be Used for Data Generation?
One might be tempted to assume that a Convolutional Autoencoder characterizes the latent space sufficiently enough to generate data. After all, if we are mapping digits to “meaning” in the latent space, then all we have to do is pick a point in this latent space and decode its “meaning” to get a generated image.
Unfortunately, this method will not work. As we will see, Autoencoders optimize for faithful reconstructions. This means that the Autoencoder learns to use the latent space as an embedding space to create optimal compressions rather than learning to characterize the latent space globally as a well-behaved feature landscape. We can see a simplified version of this schema in the below image, where our original space has three dimensions, and our latent space has two. Note that the original space of the MNIST digits actually has 784 dimensions, but three are used below for visualization.

We can see that the reconstructed image is not mapped exactly to where the input image lies in the original space. The nonzero distance between these two points is why the reconstructed image does not look exactly like the original image. This distance is called the reconstruction loss, and it is represented by a purple line between the two red points.
We can also see that randomly sampling a point in the latent space (i.e., latent vector) and passing it through the decoder outputs an image that does not look like a digit, contrary to what we might expect.
But Why Doesn’t This Work?
To understand why Autoencoders cannot generate data that sufficiently mimics a training set, we’ll consider an example to develop our intuition. Consider the following set of two-dimensional data points:

How might an autoencoder learn to compress this data to one dimension? Recall that a neural network is a composition of continuous functions. Therefore, a neural network can represent, in principle, any continuous function. Let’s say that the encoder of our network learns to interpolate the points as such:

And then compress the data to one dimension by using the path distances of the points along this curve as their locations in the one-dimensional space. Below you can see how this would work. The path distances of two points are shown as red and green curves in the two-dimensional space on the left. The lengths of these curves represent the distances from the same points to the origin in the one-dimensional space (along the x-axis) on the right.

Encoding to One-Dimension Based on Interpolated Curve Path Distance
The decoder will learn the inverse of this map - i.e. to map the distance from the origin in the latent one-dimensional space back to the distance along the curve in the two-dimensional space.
From here, it seems a straightforward task to generate data - we simply need to pick a random latent vector and let the decoder do its work:

Simple as that! Right?
Wrong. While it seems like we may have hit the nail on the head, we have only learned to generate points along our interpolated curve in the original space. Our network has just learned one such curve in the original space that could represent the true underlying distribution of the data. There are an infinite number of curves in two-dimensional space that interpolate our data points. Let’s assume that the true underlying distribution looks like this:

Then our encoding-decoding schema has not understood the underlying structure of the data, making our data generation process inherently flawed. If we take our previously generated data point, we can see that it does not lie on the true generating curve (shown in orange here) and therefore represents poor generated data that does not mimic the true dataset. If we continued sampling from our true curve (in orange) ad infinitum, we would never get the generated point. There is a nonzero greatest lower bound on the distance between any true point we could sample and our generated one.

In the above example, our Autoencoder learned a highly effective and lossless compression technique for the data we saw, but this does not make it useful for data generation. We have no guarantee of the behavior of the decoder over the entire latent space - the Autoencoder only seeks to minimize reconstruction loss. If we knew that the data were sampled from a spiral distribution, we could place constraints on our encoder-decoder network to learn an interpolated curve that would be better for data generation.
In general, we will not know the exact form of a substructure which constitutes the data’s distribution, but can we still use this concept of constraining the learning process in order to tailor Autoencoders to be useful for data generation?
What is a Variational Autoencoder?
While the above example was just a toy example to develop our intuitions, there are two important insights to take from it. The first is that, of all possible encoding-decoder sequences that are useful for data compression, only a small subset of them yield decoders that are useful for data generation. The second is that, in general, we do not know a priori the underlying structure of the data in such an exploitable way. How can we constrain our network to overcome these issues?
Variational Autoencoders accomplish this challenge with a simple but crucial differentiating factor - rather than map input data to points in the latent space, they map to parameters of a distribution that describe where a datum “should” be mapped (probabilistically) in the latent space, according to its features.

As a result, the VAE does not simply try to embed the data in the latent space, but instead to characterize the latent space as a feature landscape, a process which conditions the latent space to be sufficiently well-behaved for data generation. Not only can we use this landscape to generate new data, but we can even modify the salient features of input data. We can control, for example, not only whether a face in an image is smiling, but also the type and intensity of the smile:

Understanding Variational Autoencoders with MNIST
To understand how VAEs work, let’s look at a concrete example. We will go through how a Keras VAE learns to characterize the latent space as a feature landscape for the MNIST Handwritten Digit dataset. The MNIST Digit set contains tens of thousands of 28-by-28 pixel grayscale images of digits. Here are some example images to familiarize yourself 1. Let’s start off with some baseline assumptions.
Problem Setup
- First, let’s assume that the convolutional feature extractors in our encoder network are already trained. Therefore, the learning that the encoder is doing is in how to map extracted features to distribution parameters.
- Initially, latent vectors are decoded to meaningless images of white noise. Therefore, let’s say that our decoder network is partially trained. This means that the latent space is partially characterized so that our decoded images are legible and have some meaning.
- We set the dimensionality of the latent space equal to two so that we can visualize it. That is, the location of a generated image in our 2D plane corresponds spatially to the point in the latent space that was decoded to yield the image.
- Lastly, let’s assume that our encoder network is mapping to distribution parameters for multivariate Gaussians with diagonal log covariance matrices.
With our baseline assumptions in place, we can move on to understanding how Variational Autoencoders learn under the hood!
Training on a Six
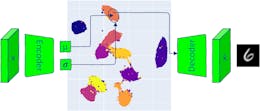
Given our above assumptions, let’s assume that we are inputting an image of a six to our Keras VAE for training2. Our encoder network extracts the salient features from the digit, and then maps them to distribution parameters for a multivariate Gaussian in the latent space. In our case, these parameters are a length two mean vector and a length two log covariance vector.
Below you can see our two-dimensional latent space visualized as a plane. The red dot indicates the mean of the distribution that our input image was mapped to, and the red curve indicates the 1-sigma curve of this distribution.
Now, we sample from this distribution and pass the resulting data point into the decoder. The error is measured with respect to this randomly generated point. It is this difference that differentiates ordinary and variational Autoencoders, and what makes VAEs useful for data generation. The randomly sampled point is represented by a green dot in the below image.

We assumed that our decoder was partially trained. Therefore, since input images that “look like” six are mapped to this area by our encoding network, our decoding network will learn to associate this area to images that have the salient features seen in sixes (and similar digits, which will be relevant later). This means that our decoder will transform the randomly sampled green point above into an image that has the salient features of a six. Below you can see that we have replaced the green dot with its corresponding decoded image.

Since this image looks similar to our input image of a six, the loss will be low, telling the network that it is doing a good job characterizing this area of the latent space as one which represents the salient features seen in six-like images.
Training on a One
Further on during training, let’s say that an image of a one is input into our network3. For the sake of the example, let’s assume that the encoder network maps the image’s extracted features to the distribution parameters seen below, where again the red dot represents the mean of the distribution, and the red curve represents its 1-sigma curve.

Note that these distribution parameters land the bulk of the distribution in the area that we previously saw represented (and therefore decoded to) six-like images. Once again, a point will be randomly sampled from this area and passed through to the decoder to calculate the loss. Remember, the decoder is not a priori aware of the fact that the point was sampled from a distribution that relates to the input image. All the decoder sees is a point in a region of the latent space which has features seen in images that look like “6”, so when a point is randomly sampled from this distribution, it will be decoded to look something like this:

Recall that our original input was a one. Since the decoded image does not look like a one, the loss is going to be very high, and the VAE will adjust the encoder network to map ones to distribution parameters that are not near this region.
Training on a Zero
Let’s continue with one last training example - say we have an input image of a zero and that again it is encoded to distribution parameters that end up randomly sampling near the “six-like region”. Let’s assume we sample the point below, which has been decoded into its corresponding image:

“6” and “0” are a lot “closer” in salient features than “6” and “1” - they both have a loop and can be relatively easily transformed continuously from one to the other 4. Therefore, our decoded image could be reasonably interpreted as six or as a zero. In fact, if you look closely, you will see that the curve shared by both 6 and 0 is strong in the decoded image (outlined in red), whereas the curve unique to 0 (outlined in blue) and the curve unique to 6 (outlined in green) are weaker.

Given the fact 6 and 0 share many salient features, the loss will still be relatively small, even though this image could reasonably be interpreted as a 6 or as a 0.
Therefore, this general region of the latent space will come to represent both sixes and zeros because they have similar features. In between the latent space points that represent a “pure” six and a “pure” zero, (i.e. a shape that is obviously a 6 and couldn’t be interpreted as a zero and vice versa), the Variational Autoencoder will learn to map intermediate points to images that could reasonably be interpreted as “6” or “0”. The decodings of the intermediate points yield snapshots of continuous transformations from one shape to another.
We will end up with a local patch that looks like what can be seen below, where these transformations are directly observable:

Characterizing the Rest of the Latent Space
The process outlined above will be repeated with every image during training across the entire latent space. Images that don’t look like 6 or 0 will be pushed away, but clump together with similar images in the same way. Below we see a patch which represents nines and sevens, and a patch that represents eights and ones.

While we continue this process over the entire dataset, we will observe global organization. We saw above how good behavior on local patches emerges, but these local patches have to patch together in a way that “works” at every point, implying a continuous transition between feature regions. We therefore get a path between any two points in the latent space that has a continuous transition between their features along the path.
Below you can see an example of one such path that connects an 8 to a 6. Many of the points on the path create convincing data, including images that look like fives, threes, and twos:

We would like to highlight once again that our latent space has been characterized as a feature landscape, not as a digit landscape. The decoder doesn’t even know what “digits” are in the sense that the label information in the MNIST dataset never appears in the training process, yet the decoder can still create convincing digit images. Therefore, we can get a map as below, where each salient feature is associated with a particular locus:

Some of these loci have been highlighted in the image. Let’s describe the salient feature(s) associated with each locus:
-
Red = pure connected loop
-
Blue = connected loop with line
-
Green = multiple open loops
-
Purple = angular shapes
-
Orange = pure vertical line
-
Yellow = angled line, partially open
Remember, the grid above is a direct decoding of our two-dimensional latent space. None of the digit images in the grid are directly seen in our training dataset - they are simply representations of the salient features among the dataset that the VAE learned.
Building a Variational Autoencoder with Keras
Now that we understand conceptually how Variational Autoencoders work, let’s get our hands dirty and build a Variational Autoencoder with Keras! Rather than use digits, we’re going to use the Fashion MNIST dataset, which has 28-by-28 grayscale images of different clothing items5.
Setup
First, some imports to get us started.
from IPython import display
import glob
import imageio
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
import tensorflow_probability as tfp
import time
Let’s import the data using TensorFlow’s built-in fashion_mnist dataset. We display an example image, in this case a boot, to get an idea of what an image looks like.
(train_images, _), (test_images, _) = tf.keras.datasets.fashion_mnist.load_data()
plt.imshow(train_images[0,:,:], cmap='gray_r')
plt.axis("off")

We model each pixel with a Bernoulli distribution. Recall that the Bernoulli distribution is equivalent to a binomial distribution with n=1, and it models a single realization of an experiment with a binary outcome. In this case, the value of the random variable 𝝌 corresponds to whether or not a pixel is “on” or “off”. That is, a 𝝌=0 represents a completely white pixel (pixel intensity = 255) and a 1 represents a completely black pixel (pixel intensity = 0). Note that the color map above is reversed, so do not get confused if the pixel values seem flipped.
We scale our pixel values to be in the range [0, 1] and then binarize them with a threshold of 0.5, after which we display the example image from above post-binarization.
Finally, we initialize some relevant variables and create dataset objects from the data. The dataset object shuffles the data and segments it into batches
def preprocess_images(images):
images = images.reshape((images.shape[0], 28, 28, 1)) / 255.
return np.where(images > .5, 1.0, 0.0).astype('float32')
train_images = preprocess_images(train_images)
test_images = preprocess_images(test_images)
plt.imshow(train_images[0,:,:], cmap='gray_r')
plt.axis("off")
plt.tight_layout()
train_size = train_images.shape[0]
batch_size = 32
test_size = test_images.shape[0]
train_dataset = (tf.data.Dataset.from_tensor_slices(train_images)
.shuffle(train_size).batch(batch_size))
test_dataset = (tf.data.Dataset.from_tensor_slices(test_images)
.shuffle(test_size).batch(batch_size))

Defining the Variational Autoencoder
Encoder Network
Now we can move on to defining the Keras Variational Autoencoder model itself. To begin, we define the encoding network, which is a simple sequence of convolutional layers with ReLU activation. Note that the final convolution does not have an activation. VAEs with convolutional layers are sometimes referred to as "CVAEs" - Convolutional Variational AutoEncoders.
The final layer of our network is a dense layer that encodes to twice the size of our latent space. Remember, we are mapping to parameters for a distribution defined on our latent space, not into the latent space itself. We use Gaussians with diagonal log covariance matrices for these distributions. Therefore, the output of our encoder must yield the parameters for such a distribution, namely a mean vector with the same dimensionality of the latent space, and a log variance vector (which represents the diagonal of the log covariance matrix) with the same dimensionality of the latent space.
class CVAE(tf.keras.Model):
"""Convolutional variational autoencoder."""
def __init__(self, latent_dim):
super(CVAE, self).__init__()
self.latent_dim = latent_dim
self.encoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(
filters=32, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Conv2D(
filters=64, kernel_size=3, strides=(2, 2), activation='relu'),
tf.keras.layers.Flatten(),
# No activation
tf.keras.layers.Dense(latent_dim + latent_dim),
]
)
Decoder Network
Next up is defining our decoder network. Instead of the fully-connected to softmax sequence that is used for classification networks, our decoder network effectively mirrors the encoder network. Autoencoders have a pleasant symmetry - the encoder learns a function f which maps to the latent space; the decoder learns the inverse function f -1 which maps from the latent space back into the original space. The Conv2DTranspose layers provide learnable upsampling to invert our convolutional layers.
self.decoder = tf.keras.Sequential(
[
tf.keras.layers.InputLayer(input_shape=(latent_dim,)),
tf.keras.layers.Dense(units=7*7*32, activation=tf.nn.relu),
tf.keras.layers.Reshape(target_shape=(7, 7, 32)),
tf.keras.layers.Conv2DTranspose(
filters=64, kernel_size=3, strides=2, padding='same',
activation='relu'),
tf.keras.layers.Conv2DTranspose(
filters=32, kernel_size=3, strides=2, padding='same',
activation='relu'),
# No activation
tf.keras.layers.Conv2DTranspose(
filters=1, kernel_size=3, strides=1, padding='same'),
]
)
Forward Pass Functions
Training is not as simple for a Variational Autoencoder as it is for an Autoencoder, in which we pass our input through the network, get the reconstruction loss, and backpropagate the loss through the network. Variational Autoencoders demand a more complicated training process. This starts with the forward pass, which we will define now.
Encoding Function
To encode an image, we simply pass our image through our encoder, with the caveat that we bifurcate the output. Recall from above that we are encoding our input to a vector with twice the dimensionality of the latent space because we are mapping to parameters which define how we sample from the latent space for decoding.
Operationally, the definition of these parameter vectors happens here - where we split our output into two vectors, each with the same dimensionality of the latent space. The first vector represents the mean of our multivariate Gaussian in the latent space, and the second vector represents the variances of the same Gaussian’s diagonal log covariance matrix.
def encode(self, x):
mean, logvar = tf.split(self.encoder(x), num_or_size_splits=2, axis=1)
return mean, logvar
Reparameterization Function
Recall that we are not decoding an encoded input directly, but rather using the encoding to define how we sample from the latent space. We instead decode a point in the latent space that is randomly sampled according to the distribution defined by the parameters output by our encoding network. One may be tempted to simply use tf.random.normal() to sample such a point; but remember that we are training our model, which means that we need to perform backprop. This is problematic because backprop cannot flow through a random process, so we must implement what is known as the reparameterization trick:
We define another random variable which is deterministic in our mean and log variance vectors. It takes in these two vectors as parameters, but it maintains stochasticity via a Hadamard product of the log variance vector with a vector whose components are independently sampled from a standard normal distribution. This trick allows us to retain randomness in our sampling while still allowing backprop to flow through our network so that we can train our network. Backprop cannot flow through the process that produces the random vector used in the Hadamard product, but that does not matter because we do not need to train this process.
def reparameterize(self, mean, logvar):
eps = tf.random.normal(shape=mean.shape)
return eps * tf.exp(logvar * .5) + mean
Decoding Function
Given a latent space point, decoding is as simple as passing the point through the decoder network. We allow the option to output either logits directly or their sigmoid. By default, we do not apply sigmoid for purposes of numerical stability which will be highlighted later.
def decode(self, z, apply_sigmoid=False):
logits = self.decoder(z)
if apply_sigmoid:
probs = tf.sigmoid(logits)
return probs
return logits
Sampling Function
Given a reparameterized sampling from a distribution, the sampling function simply decodes the input. If no such input is provided, it will randomly input 100 points in the latent space sampled from a standard normal distribution.
The function is decorated with @tf.function in order to convert the function into a graph for faster execution.
@tf.function
def sample(self, z=None):
if z is None:
z = tf.random.normal(shape=(100, self.latent_dim))
return self.decode(z, apply_sigmoid=True)
Loss Computation
We have defined our Variational Autoencoder as well as its forward pass. To allow the network to learn, we must now define its loss function. When training Variational Autoencoders, the canonical objective is to maximize the Evidence Lower Bound, which is a lower bound for the probability of observing a set of latent variables given data. That is, it is an optimization criterion for approximating a posterior distribution.

In practice, only a single sample Monte Carlo estimate of the ELBO is computed:

We start by defining a helper function, namely the probability distribution function of standard log-normal distribution, which will be used in the final loss computation.
def log_normal_pdf(sample, mean, logvar, raxis=1):
log2pi = tf.math.log(2. * np.pi)
return tf.reduce_sum(
-.5 * ((sample - mean) ** 2. * tf.exp(-logvar) + logvar + log2pi),
axis=raxis)
Now we define our loss function, which contains the following steps:
- Compute the distribution parameters for an image via encoding
- Use these parameters to sample from the latent space in a backprop-compatible way by using the reparameterization trick
- Calculate the binary cross entropy between the input image and decoded image
- Calculate the values of the conditional distribution, the latent distribution prior (modeled as a unit Gaussian), and the approximate posterior distribution.
- Calculate the ELBO
- Negate the ELBO and return it
-
You may be wondering why we returned the negative of the ELBO. We did this because we are trying to maximize the ELBO, but gradient descent works by minimizing a loss function. Therefore, rather than attempting to implement gradient _as_cent, we simply flip the sign and proceed normally, taking care to correct for the sign-flip later.
Lastly, we note that tf.nn.sigmoid_cross_entropy_with_logits() is used for numerical stability, which is why we compute logits and do not pass them through sigmoid when decoding
def compute_loss(model, x):
mean, logvar = model.encode(x)
z = model.reparameterize(mean, logvar)
x_logit = model.decode(z)
cross_ent = tf.nn.sigmoid_cross_entropy_with_logits(logits=x_logit, labels=x)
logpx_z = -tf.reduce_sum(cross_ent, axis=[1, 2, 3])
logpz = log_normal_pdf(z, 0., 0.)
logqz_x = log_normal_pdf(z, mean, logvar)
return -tf.reduce_mean(logpx_z + logpz - logqz_x)
Training Step
Finally, we define our training step in the usual way. We compute the loss on a GradientTape, backprop to calculate the gradient, and then take a step with the optimizer given the gradient. Again, we decorate this method as a tf.function for a speed boost.
@tf.function
def train_step(model, x, optimizer):
"""Executes one training step and returns the loss.
This function computes the loss and gradients, and uses the latter to
update the model's parameters.
"""
with tf.GradientTape() as tape:
loss = compute_loss(model, x)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
Training
Setup
We’ve finished defining our Keras Variational Autoencoder and its methods, so we can move on to training. We choose the dimensionality of our latent space to be 2 so that we can visualize the latent space as we did above. We set our number of epochs to 10, and instantiate our model.
latent_dim = 2
epochs = 10
model = CVAE(latent_dim)
Plotting Function
The plotting function below allows us to track how the latent space is characterized during learning. The function takes a grid of points in the latent space and passes them through the decoder to generate a landscape of generated images. In this way, we can observe how different regions in the latent space evolve to represent features, and how these feature regions are distributed across the space, with continuous transitions between them.
def plot_latent_images(model, n, epoch, im_size=28, save=True, first_epoch=False, f_ep_count=0):
# Create image matrix
image_width = im_size*n
image_height = image_width
image = np.zeros((image_height, image_width))
# Create list of values which are evenly spaced wrt probability mass
norm = tfp.distributions.Normal(0, 1)
grid_x = norm.quantile(np.linspace(0.05, 0.95, n))
grid_y = norm.quantile(np.linspace(0.05, 0.95, n))
# For each point on the grid in the latent space, decode and
# copy the image into the image array
for i, yi in enumerate(grid_x):
for j, xi in enumerate(grid_y):
z = np.array([[xi, yi]])
x_decoded = model.sample(z)
digit = tf.reshape(x_decoded[0], (im_size, im_size))
image[i * im_size: (i + 1) * im_size,
j * im_size: (j + 1) * im_size] = digit.numpy()
# Plot the image array
plt.figure(figsize=(10, 10))
plt.imshow(image, cmap='Greys_r')
plt.axis('Off')
# Potentially save, with different formatting if within first epoch
if save and first_epoch:
plt.savefig('tf_grid_at_epoch_{:04d}.{:04d}.png'.format(epoch, f_ep_count))
elif save:
plt.savefig('tf_grid_at_epoch_{:04d}.png'.format(epoch))
plt.show()
Training Loop
We’re finally ready to begin training! We save a snapshot of our latent space using the function above before we start learning and instantiate an Adam optimizer. After this, we enter our training loop, which simply involves iterating through each training batch and executing train_step(). After all batches have been processed, we compute the loss on the test set using the compute_loss(), and then return the negative of the average loss to yield the ELBO. We return the negative average of the loss here because we flipped the sign in our compute_loss() function to use gradient-descent learning.
If we are within the first epoch, we save a snapshot of the latent space every 75 batches. This is because training happens so quickly that we need this level of granularity at the beginning to observe training. If we are not in the first epoch, we save a snapshot of the latent space at the end of every epoch.
tf.config.run_functions_eagerly(True)
plot_latent_images(model, 20, epoch=0)
optimizer = tf.keras.optimizers.Adam(1e-4)
for epoch in range(1, epochs + 1):
start_time = time.time()
for idx, train_x in enumerate(train_dataset):
train_step(model, train_x, optimizer)
if epoch == 1 and idx % 75 == 0:
plot_latent_images(model, 20, epoch=epoch, first_epoch=True, f_ep_count=idx)
end_time = time.time()
loss = tf.keras.metrics.Mean()
for test_x in test_dataset:
loss(compute_loss(model, test_x))
elbo = -loss.result()
#display.clear_output(wait=False)
print('Epoch: {}, Test set ELBO: {}, time elapse for current epoch: {}'
.format(epoch, elbo, end_time - start_time))
if epoch != 1:
plot_latent_images(model, 20, epoch=epoch)
Results
The below function allows us to string together all of our snapshots during training into a GIF so that we can observe how our Keras Variational Autoencoder learns to associate distinct features to different regions in the latent space, and organize these regions based on similarity to allow for a continuous transition between them.
anim_file = 'grid.gif'
with imageio.get_writer(anim_file, mode='I') as writer:
filenames = glob.glob('tf_grid*.png')
filenames = sorted(filenames)
for filename in filenames:
print(filename)
image = imageio.imread(filename)
writer.append_data(image)
image = imageio.imread(filename)
writer.append_data(image)
Here is an example of a training GIF generated with this function:

And here is the final snapshot at the end of training:

As you can see, even our small network trained for just ten epochs with a low-dimensional latent space produces a powerful Keras VAE. The feature landscape is learned well and yields reasonable instances of clothing, especially given how abstract and diverse the different classes within the training set are. We see boots, shoes, pants, t-shirts, and long-sleeve shirts represented within the image. It is easy to see how using large, multi-channel images and more powerful hardware could yield convincing results even using a simple network architecture, like the one laid out here.
Final Words
VAEs are an invaluable technique for generating data, and they currently dominate the field of data generation in conjunction with GANs. We saw how and why Autoencoders fail to produce convincing data, and how Variational Autoencoders extend simply but powerfully these architectures to be specially tailored for the task of image generation. We built a Keras Variational Autoencoder with Python, and used this MNIST VAE to generate plausible images of clothing.
Footnotes
- This image is sourced from this GitHub repository
- Image is sourced from this page
- Image is sourced from this page
- This transformation is actually not continuous because we need to “break” the zero and then reconnect it to a different part of itself, but the rest of the transformation is continuous
- This example is adapted from the TensorFlow website
Also Published Here