










Introduction
Modern analytics teams are hungry for data. They are generating incredible insights that make their organizations smarter and are emphasizing the need for data-driven decision making across the board. However, data comes in many shapes and forms and is often siloed away. What actually makes the work of analytics teams possible is the aggregation of data from a variety of sources into a single location where it is easy to query and transform. And, of course, this data needs to be accurate and up-to-date at all times.
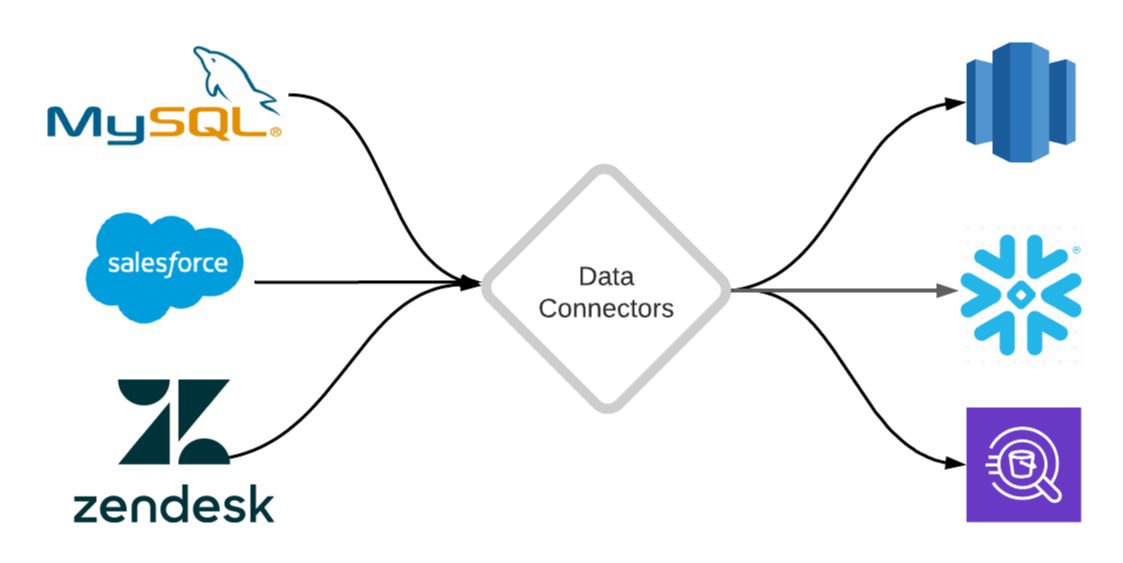
Let’s take an example. Maybe you’re trying to understand how COVID-19 is impacting your churn rates, so you can plan your sales and marketing spends appropriately in 2021. For this, you need to extract and combine data from a few different sources:
- MySQL database that details all the interactions your users are having with your product
- Salesforce account that contains the latest information about your current and prospective customers
- Zendesk account that has all support tickets raised by your customers
The data from all these sources needs to be loaded into an analytical database, aka a data warehouse, such as Amazon Redshift and updated frequently. Only then can a data analyst query and build reliable models to answer, on an ongoing basis, important business questions such as: “How is COVID-19 impacting our churn rates?”
This is a real story from one of our customers at Datacoral, the company where I work.


From a data engineering perspective, what enabled the data science team to answer the question on churn was the reliable replication of data from three data sources into a data warehouse. This is what a data connector does.
What is a data connector?
A data connector is defined as a process that runs on a schedule, extracts data from a source location and writes into a destination location.
There are significant variations in sources, destinations, and schedules that are possible, but we will focus on the ones that are commonly seen in use cases for data analytics teams.
Sources
There has been an explosion in the different sources that are capturing data for organizations today. Broadly, these data sources can be categorized as follows:
- Databases
- SaaS applications
- File systems
- Events
With a growth in microservices architectures for applications and data mesh architectures for infrastructure, we are also witnessing a corresponding increase in the number of databases used by organizations. Similarly, we are seeing close to 40 SaaS applications being used by companies under 50 employees and more than 200 SaaS tools used by companies with 1000+ employees. This points to a skyrocketing number of sources that contain your business’s data.
In this article, we will only touch on databases and SaaS applications, although it is common to see data from event streams and file drops that also needs to be analyzed by teams.
Destinations
Analytics teams want data to be made available in environments where a large amount of data can be stored and queried/transformed through SQL. In modern data analytics stacks, these environments have either meant cloud data warehouses such as Redshift and Snowflake or data lakes (or lakehouses!) such as S3 + Athena and Databricks Delta.
Data warehouses and data lakes have become popular because they provide storage and compute that can scale rapidly at very affordable prices. This is evidenced by the fact that the data warehousing market is projected to grow from $1.4B in 2019 to $23.8B in 2030.
For the purposes of this article, we will focus on data warehouses as destinations, which are more commonly seen today in data analytics.
Running on a schedule
The final piece of the puzzle is that data must move from the source to a destination on a schedule. For example, an analytics team might want to analyze their Salesforce data and decide to replicate their Salesforce objects as tables in their Snowflake warehouse. However, it’s not enough to copy this data once -- sales teams are updating records continuously. So the team might decide they want their data in Snowflake updated at least every six hours. This allows them to always work with an updated copy of their data.
A connector running on a schedule implies that there are multiple “runs” of a connector at a time interval that is specified by the schedule. For example, a daily connector will have one run every 24 hours, and an hourly connector will have 24 runs in a day. As a technical detail, schedules are often defined using a CRON expression.
Recap
Before we dive into the details of sources, destinations and schedules, here’s a quick recap of a data connector. The goal of a data connector is to extract data from some sources and load that data into some destination, on a periodic basis. Data connectors are an integral part of data engineering today and support the incredible data analytics teams in an organization.
What does it mean to extract data from a source?
A data source will typically have many objects (check out the huge list of standard objects Salesforce offers, as an example). We have also established that a data connector runs on a schedule.
With this in mind, let’s first discuss what happens in a specific "run" for a specific object. At a high-level, there are two modes of extracting data from a data source:
- Snapshot mode: In this mode, all the data for an object is fetched at every run.
- Incremental mode: In this mode, partial data for an object is fetched at every run, and typically, only the data that has been updated or created since the last fetch happened.
Not all data sources will support both modes of extracting data. Shortly, we will look at what this means for the two common types of data sources - databases, and SaaS applications. In the meantime, let’s consider the pros and cons involved with the snapshot and incremental modes.
Incremental fetches are almost always preferable when the data source APIs are well-designed. With incremental mode, less data needs to be retrieved from the source and processed by the data connector.
This leads to less load on the data source, lower network/storage/compute costs, and faster data extraction. Snapshot fetches, on the other hand, typically involve simpler code and might be preferred when the amount of data being fetched is small. Snapshot fetches are also a good way to propagate any records that might have been deleted at source (lookout for a future article on this topic).
As an aside, there is a technique called pagination which is employed when fetching a large amount of data. This is also important when building a data connector, but we will skip for the purposes of this post.
Read this if you want to learn more.
Databases
Databases support fetching data in either mode. For example, consider the following queries:
-- fetch all data for table (snapshot)
select * from schema.table;
-- fetch all data since last run at midnight Jan 21 (incremental)
select * from schema.table where updated_at > ‘2021-01-21 00:00 00’;
Having said this, the recommended way to replicate data from databases is through change data capture (CDC). CDC for databases involves replicating data by reading from database logs, rather than by running SQL queries. With CDC, more granular data can be extracted with less impact on the source database.
SaaS applications
With SaaS applications, available extraction modes are heavily dependent on the APIs that the applications make available. In some cases, both extraction modes are available for all objects (Salesforce, for example), but in most cases, this has to be looked at on a case-by-case basis. Let’s look at a couple of objects (and corresponding APIs for fetching data from them) that enable either a snapshot fetch or an incremental fetch.
For an example of where snapshot mode is supported, but not incremental, let’s look at Jira’s Get all Labels API.


The endpoint (GET /rest/api/3/label) allows a user to fetch all Jira labels used by an organization. As can be seen, the endpoint returns all labels available (albeit in a paginated fashion) and doesn’t provide a way to only fetch labels created or updated within a time interval. This means that we would not be able to make an API call to only fetch the labels that were created or updated since the last connector “run”. Therefore, snapshot mode is supported, but not incremental mode.
Now, for an example of where the incremental mode is supported, but not snapshot mode, let’s look at Stripe’s List Events API.


This endpoint (GET /v1/events) allows a user to fetch Stripe events. One of the parameters that could be an input to the endpoint is called created, which allows a user to only fetch events that were created within a time interval. This enables an incremental fetch of data for Stripe events. However, the same API lists that only events going back 30 days can be fetched using this API (shown in the first sentence of the image above), which means that a snapshot fetch won’t be possible.
Hopefully, these examples convey the key differences between snapshot and incremental modes. It is important to understand which modes any given source provides support for and then build the connector accordingly.
What does it mean to write data into a destination?
Now that we have fetched data from a source (in either snapshot or incremental mode), we need to write this into a destination. Typically, data from a given object at the source maps to a corresponding table at the destination. At a high-level, there are three modes of writing data into data warehouses such as Snowflake or Amazon Redshift:
- Replace mode: In this mode, the data fetched replaces the existing data in the warehouse table every run.
- Append mode: In this mode, the data fetched is appended to the warehouse table every run.
- Merge mode: In this mode, the data fetched is merged (or upserted) into the warehouse table in every run. For the merge operation (between the recent batch of data fetched and the destination table) to work, a primary key is required for the table. To see examples of how the merge command works, check Snowflake’s documentation here.
Extract modes x Write modes
Now, let’s think about what happens when different extract modes (snapshot or incremental) are combined with different write modes (replace, append or merge). There are six combinations that are possible, although some are more useful than the others. We will leave the discussion of the relative pros and cons of the six combinations as an exercise for the readers.


As a final thought, when building data connectors, one might not have control over both the extract modes (since the source might not support it), but all the write modes are possible.
What does it mean to run a connector on a schedule?
Once the source (and the extract mode) and destination (and write mode) have been determined, the final piece to determine is how frequently the data should be refreshed inside the warehouse. This is best determined by answering the following question: for consumers of your data, what is the minimum “data update latency” required? Put another way, are there “data freshness SLAs” that you’ve determined with the consumers of this data? Let’s consider a couple of examples to clarify this.
Say you’re an engineering leader and want to understand productivity across your teams. For that, you might be using a Jira connector to write data into your warehouse. You plan to look at the dashboards based on this data once every 2 weeks, since that is the sprint cycle for your teams. In that case, it might be acceptable for the connector to run once a day.
Alternatively, let’s say you’re in charge of financial reporting at your company and are using Stripe and Shopify connectors to provide reports for your customers that are up-to-date to the closest hour. In that case, running your connectors once-a-day would be too slow, and you might consider running them once every 10 minutes.
Generally speaking, running connectors more frequently is expensive in the following ways:
- Queries against the source: More load on databases and more API usage for SaaS sources
- Data: More data is transferred over the network, more storage needed and more compute for your data pipelines
- Writes against destination: More write queries run against your data warehouse.
Our recommendation is to match the schedule closely to the business needs, and not run data connectors more frequently than necessary.
Other challenges
While we have covered the basics of what it takes to build a data connector, there are often other challenges that teams run into. Some of the ones that frequently come up are the following:
- Schema Change Capture: Aside from data changing at source, often schemas can also change at the source. For example, there might be new tables/objects that get created or columns/fields that get added, and these changes to the schema need to be migrated to the destination. There are many kinds of schema changes that are possible, and all of them need to be handled appropriately.
- Historical Syncs: For large tables where data is being extracted in incremental mode, an initial historical sync of data needs to be done. Depending on the size of the data, this can take days to weeks and can put significant pressure on the source.
- Capturing Deletes: It can be tricky to capture records which have been deleted at the source in incremental mode. This is because APIs often don’t return deleted items (only new and updated items) and a different process might be needed.
- Handling errors: There are many different types of errors that could happen in a data pipeline. Everything from HTTP 500 error codes from APIs to API throttling to network issues when connecting to databases. The connector must be robust to these errors and should retry when appropriate.
These are not trivial challenges. Often, building the first pipeline is easy, but the management of the pipeline over many months/years and handling all the edge cases that inevitably come up is what makes data connectors challenging.
Conclusion
If you’ve made your way through to the end of this article, you should have a good understanding of the following:
- What is a data connector and what are the problems it solves?
- What are the components of a data connector (source, destination, schedule)?
- What are the tradeoffs involved when making decisions about building a data connector?
While there is so much more that we could have covered in this article, we hope that this gives you a framework for the many decisions involved in building a connector. Data connectors aren’t easy, but they are a necessary first step in enabling data analytics teams to be productive.
Also published on: https://blog.datacoral.com/data-connectors-101/











