










Continuous Integration is the process of building and testing software every time a team member commits changes to a central repository to reduce integration problems and improve software quality. Continuous Integration (CI) is a development practice that requires developers to integrate code into a shared repository several times a day. Each check-in is then verified by an automated build, allowing teams to detect problems early.
The first CI/CD toolset was developed in the late 90s to meet the needs of small and medium DevOps teams. Since then, continuous integration and delivery have become the standard and are supported by several cloud services platforms. One of the first teams to realize the benefits that CI/CD pipelines offer was Amazon’s AWS team. The team used Jenkins to help them build their core platform components as well as develop tools for internal use.
Are you looking to transform your software development process from high-effort, slow-paced waterfall to fast-paced Agile or DevOps? If yes, then this blog post provides an easy-to-follow introduction to the continuous integration (CI) and continuous delivery (CD) practices with Amazon Web Services (AWS).
What are The Prime Challenges Associated with Software Delivery ?
Enterprises today face the challenges of rapidly changing competitive landscapes, evolving security requirements, and performance scalability. Enterprises must bridge the gap between operations stability and rapid feature development. Continuous integration and continuous delivery (CI/CD) are practices that enable rapid software changes while maintaining system stability and security.
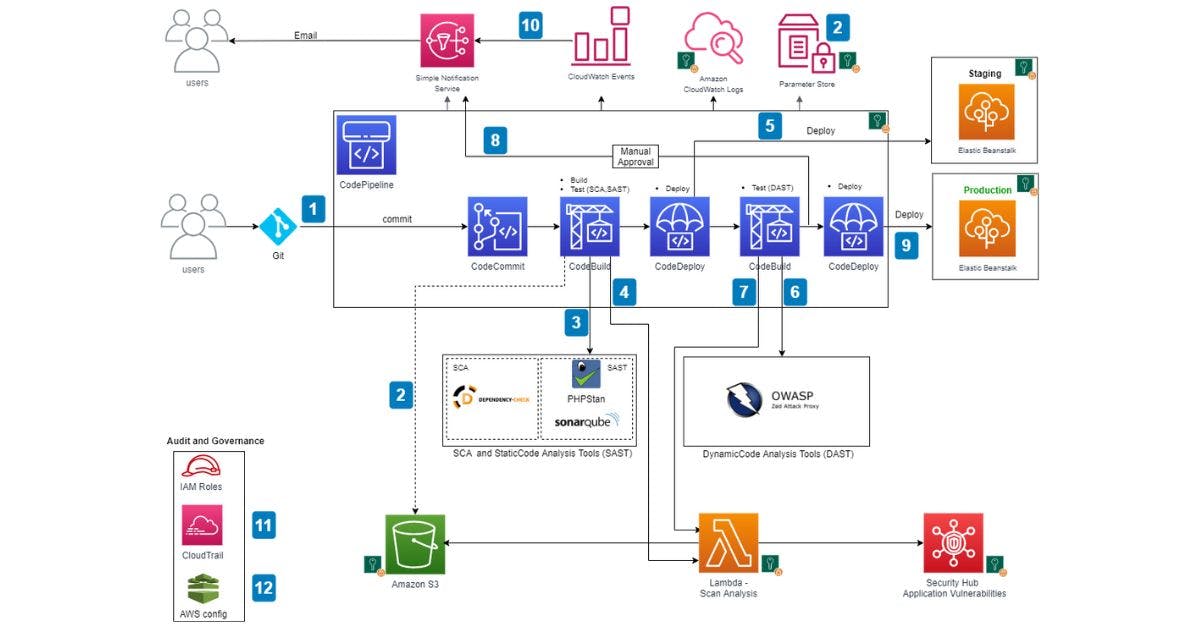
Let’s see how Amazon has tackled the challenge of building and delivering software. One can use AWS CodeStar, AWS CodeCommit, AWS CodeBuild, AWS CodeDeploy, and AWS CodePipeline to realize an automated CI/CD pipeline to deliver software that is more reliable and secure.
The services rendered by AWS can be leveraged by the DevOps professionals to scale-up and secure their software services. One can securely store and can apply version control to the source code of the applications. One can use AWS CodeStar to rapidly orchestrate an end-to-end software release workflow leveraging these services. For an existing environment, CodePipeline has the flexibility to integrate each service independently with the help of your existing tools. These are highly available and easily integrated services that can be accessed through the AWS Management Console, AWS application programming interfaces (APIs), and AWS software development toolkits (SDKs), like any other AWS service.
Understanding Continuous Integration & Continuous Delivery or Deployment
a) Continuous Integration
Continuous integration (CI) is a software development practice wherein developers merge their code changes into a central repository, after which automated bids and tests are deployed. CI, in general, refers to the build or integration stage of the software release process and requires both an automation component (for example learning to integrate frequently). The key goals of CI are to find and address bugs more quickly, improve software quality, and reduce the time taken to validate and release new software updates.
Continuous integration focuses on smaller commits and smaller code changes to integrate. A developer commits code at regular intervals at a minimum of once a day. The developer pulls code from the code repository to ensure the code on the local host is merged before pushing it to the build server. At this stage, the build server runs the various tests and either accepts or rejects the code commit.
There are some basic challenges that come with the implementation of CI such as more frequent commits to the common codebase, maintaining a single source code repository, automating builds and automating testing. Additional challenges include testing in environments similar to production, providing visibility of the process to the team, and allowing developers to easily obtain any version of the application.
b) Continuous Delivery
A common misconception associated with continuous delivery happens to be that every change committed is applicable to the production, once it passes the automated tests. However, the point of continuous delivery is not to apply every change to production immediately, but to ensure that every change is ready to go to production.
Before a change is deployed to production, one can implement a decision process to ensure that the production deployment is authorized and audited. This decision can be made by a person and executed by tooling.
Continuous delivery makes the decision to go live a business decision instead of a technical one. Technical validation occurs on every commit.
Rolling out a change to production is not a disruptive event. Deployment doesn’t involve the technical team to stop working on a certain set of challenges, it doesn’t even need a project plan, a handover document, or a maintenance window. Continuous deployment makes deployment repeatable that’s carried out multiple times in testing environments.
How Continuous Delivery is Beneficial?
CD provides numerous benefits for your DevOps team including automating the process, improving the productivity of the developers, improving code quality, and delivering updates to your customers faster.
Automating the Software Release Process
CD enables teams to check in code that is automatically built, tested, and prepared to be released for production so that your software delivery is efficient, resilient, rapid, and secure.
Optimizing the Productivity of Developers
With the help of CD, you can optimize the productivity of your teams. This happens as developers free themselves from manual tasks, untangle complex dependencies, and return focus to developing new features in software. Developers can focus on coding logic that delivers the features that they need instead of integrating their code with other parts of the business and spending cycles on how to deploy this code to a platform.
CD Improves Code Quality
With the help of CD, marketers can easily develop and address bugs. This allows them to secure the delivery process before the bugs translate into bigger problems. Your team can easily perform additional kinds of code tests because the entire process has been automated. As more testing is facilitated more frequently, teams can iterate faster with immediate feedback on the impact of changes. This allows teams to drive quality code with a high assurance of stability and security.
The Updates Can Be Delivered Faster
Capitalizing on CD, your teams can deliver updates to customers quickly and more frequently. When CI/CD is being implemented, the efficiency of the entire team in terms of the release of features and bug fixes is optimized. Enterprises can respond faster to market changes, security challenges, customer needs and cost pressures. For example, if only a security feature is required, your teams can implement the CI/CD with automated testing to introduce the fix quickly and reliably to production systems with high confidence. What used to take months can now be done in days or even hours.
Implementation of Continuous Integration and Continous Delivery
To help on your journey with the implementation of CI/CD model, AWS has collaborated with a number of certified DevOps partners who can provide resources and tooling. One can always move on to AWS Cloud and can refer to the
Continuous Integration and Continous Delivery - The Pathway
In the CI/CD pipeline new code is submitted at one end, tested over a series of stages (source, build, staging and production), and then published as production-ready code. The organizations that are new to CI/CD can approach this pipeline is an iterative fashion. This means that one needs to start small, and iterate each stage so that one can understand and develop his code in a way that will aid their organizational growth.
Each stage of the CI/CD pipeline is structured as a logical unit in the delivery process. Additionally, each stage acts as a gate that vets a certain aspect of the code. As the code progresses through the pipeline, the quality of the code improves as a general assumption, as more aspects of the code continue to be verified. Problems uncovered in an early stage stop the code from progressing through the pipeline. Results from the tests are immediately sent to the team and all further builds and releases are stopped if the software doesn’t pass the stage.
These stages are suggestions and one can adapt the stages based on their business need. Some stages can even be repeated for multiple types of testing, security and performance. Depending on the complexity of a project, and the structure of your team some stages can be repeated several times at different levels. For example, the end product of one team can become a dependency in the project of the next team. This employs that the end product of the first team is subsequently staged as an artifact in the next team’s project.
The presence of CI/CD pipeline has greater impact on maturing the capacities of your organization. The organization should start with small steps and not try to build a fully mature pipeline with multiple environments, many testing phrases, and automation in all stages is required at the start. Keep in mind that even organizations that have highly mature CI/CD environments still need to continuously improve their pipelines.
An organization with a CI/CD enabled framework is a journey and there are many destinations along the way. Let’s see how your organization can adopt a possible pathway starting with continuous integration through the levels of continuous delivery.
Continuous Integration – Source and Build


The first phase in the CI/CD journey involves the development of maturity in continuous integration. One should ensure that all the developers regularly commit their code to a central repository (such as one hosted in CodeCommit or GitHub). All the changes are finally merged to a release branch for the application. No developer should be holding code in isolation. If a feature branch is needed for a period of time, it should be kept up to date by merging from upstream as often as possible. Frequent commits and merges with complete units of work are recommended for the team to develop discipline and are encouraged by the process. Any developer merging a code early and often is likely to have fewer integration issues down the end.
One should also encourage developers to create unit tests as early as possible for their applications and to run these tests before pushing the code to the central repository. Errors caught early in software development process are the cheapest and easiest to fix.
When a code is pushed to a branch in a source code repository, a workflow engine monitoring that branch will send a command to a builder tool to build the code and run the unit tests in a controlled environment. This process should be appropriately sized to handle all activities including pushes and tests that might happen during the commit stage, for fast feedback. Other quality checks such as unit test coverage, style check, and static analysis, can happen at this stage as well. Finally, the builder tool helps create on for more binary builds and other artifacts, such as images, stylesheets, and documents for the application.
Continuous Delivery: Creating a Staging Environment


Continuous delivery (CD) is the next phase that entails the deploying of the application code in a staging environment, which is a replica of the product stack, and runs more functional tests. The staging environment can be a static one premade for testing, or one can provision and configure a dynamic environment with committed infrastructure and configuration code for testing and deploying the application code.
Continuous Delivery: Creating a Production Environment


In the deployment/delivery pipeline sequence, after the staging environment comes the production environment that is also built using infrastructure as a code (laC).
Continuous Deployment


The final phase in the CI/CD deployment pipeline is continuous deployment, which may include complete automation of the entire software release process from deployment to the production environment. In a fully complete CI/CD environment, the path to the production environment is fully automated, that allows code to be deployed with high confidence.
Maturity and Beyond
As an organization matures, it continues to develop its CI/CD model to include more of the following improvements:
· More staging environments for ensuring specific performance, compliance, security, and user interface (UI) tests.
· Unit tests of infrastructure and configuration code along with the application code
· Integration with other systems and processes such as code review, issue tracking, and event notification
· Integration with database schema migration (if applicable)
· Additional steps for auditing and business approval
Even the most mature organizations that have complex multi-environment CI/CD pipelines continue to look for improvements. DevOps is a journey, not a destination. Feedback about pipeline is continuously collected and improvements in speed, scale, security, and reliability are achieved as a collaboration between the different parts of the development teams.
How Developer Teams Must Be Organized to Implement CI/CD Environment
AWS recommends organizing three developer teams for the implementation of a CI/CD environment: an application team, an infrastructure team, and a tools team. The organization represents a set of basic practices that have been developed and applied in fast-paced startups, large enterprise organizations and in Amazon as well. A group of 10-12 people are recommended at most in a team for meaningful conversations to happen.
Application Team
This team is responsible for creating an application. Application developers own the backlog, stories, and unit tests, and they develop features based on a specified application target. The organizational goal of this team is to minimize the time these developers spend on non-core application tasks.
Along with having functional programming skills in the application language, the application team possesses platform skills and has a thorough understanding of the system configuration. This enables them to focus solely on developing features and hardening the application.
Infrastructure Team
This team is responsible for writing codes that both create as well as configure the infrastructure required to run the application. The team might use native AWS tools, including AWS CloudFormation, or generic tools such as Chef, Puppet, or Ansible. The infrastructure team specifies what tools are needed and it works closely with the application team. The same team might consist of only a couple of people for small application.
These teams have skills in infrastructure provisioning methods such as AWS CloudFormation or HashiCorp Terraform. The team leverages configuration and automation skills with the help of tools such as Chef, Ansible, or Salt.
Tools team
This team is responsible for building and managing the CI/CD pipeline. They are responsible for the infrastructure and tools that constitute a pipeline. These teams create the tools to be used by application and infrastructure teams within the organization. The organizational tools team need to be street smart and must stay ahead of the maturing application and infrastructure teams.
This team is skilled in building and integrating all the parts of CI/CD pipeline. This often includes the inclusion of building source control repositories, workflow engines, build environments, testing frameworks, and artifact repositories. The teams may choose to implement software such as AWS CodeDeploy, AWS CodeBuild, and AWS CodeArtifact, along with Jenkins, GitHub, Artifactory, Teamcity, and other similar tools. This leads to the development of DevOps teams that employ the sum of people, processes and tools in software delivery.
How to Test Different Stages in Continuous Integration and Continuous Delivery
The three CI/CD teams (as AWS suggests) should incorporate testing into the software development lifecycle at the different stages of the CI/CD pipeline. Overall, testing should start as early as possible. The following testing pyramid is a concept provided by Mike Cohn in the book Succeeding with Agile.
Unit tests are at the bottom of the pyramid. They are both the fastest to run and the least expensive. Therefore, unit tests should make up the bulk of our testing strategy. A good rule of thumb is about 70%. Unit tests must have almost-complete code coverage as bugs caught up in this phase can be fixed quickly or cheaply.
Service, component, and integration tests are above unit tests on the pyramid. These tests require detailed environments and therefore are most costly in infrastructure requirements and slower to run. Performance and compliance test are the next level. These require production quality environments and are still more expensive. UI and user acceptance tests top the pyramid and require a production-quality environment as well.
All these tests are a part of a complete strategy to assure high-quality software. However, for speed of development, emphasis is on the number of tests and the coverage in the bottom half of the pyramid.
Stages of CI/CD
At the beginning of a project, one must set up a source where one can store their raw code and configuration and schema changes. In the source stage, choose a source code repository such as one hosted in GitHub or AWS CodeCommit.
Setting up and Running Builds
Enabling automation is essential to the CI process. While setting up build automation, the first task should be to choose the right build tool. There are many build tools, such as:
a) Ant, Maven, and Gradle for Java
b) Make for C/C++
c) Grunt for JavaScript
d) Rake for Ruby
The build tool works the best for people depending on the programming language of their project the skill set of their team. Once marketers choose to build a tool, all the dependencies should be clearly defined in the build scripts, alongside the build steps. This is one of the best practices to version the final build artifacts, which makes it easier to deploy and keep track of issues.
Building
In the build stage, the tools will take as input any change to the source code repository, build the software the run the following types of tests post that:
a) Unit testing – This tests a specific section of code to ensure that the code does what it is expected to do. The unit testing is performed by software developers during the development phase. At this stage, a static code analysis, data flow analysis, code coverage and other software verification processes can be applied.
b) Static code analysis – This test is performed without actually executing the application after the build and unit testing. This analysis helps to figure out the coding errors and security holes and it also can ensure conformance to the coding guidelines.
Staging
In this phase, full environments are created that mirror the eventual production environment. The following tests are performed:
a) Integration Testing – This test verifies the interfaces between components against software design. Integration testing is an iterative process and facilitates building robust interfaces and system integrity.
b) Component testing – This testing tests message passing between various components and their outcomes. A key goal of this testing could be idempotency in component testing. Tests can include extremely large data volumes, or edge situations and abnormal inputs.
c) System testing – This tests the system end-to-end and verifies if software satisfies the business requirement. This might include testing the user interface (UI), API and backend logic, and end state.
d) Performance testing – This test determines the responsiveness and stability of a system as it performs under a particular workload. Performance testing is also used to investigate, measure, validate or verify the other attributes of the system such as scalability, reliability, and resource usage. Types of performance tests might include load tests, stress tests, and spike tests. Performance tests are used for benchmarking against predefined criteria.
e) Compliance testing – Checks whether the code change complies with the requirements of a nonfunctional specification and/or regulations. It determines if you are implementing and meeting the defined standards.
f) User acceptable testing – This testing validates the end-to-end business flow. The testing is executed by an end-user in a staging environment and confirms whether the system meets the requirements of the requirement specification. Typically, customers employ alpha and beta testing methodologies at this stage.
Production
Finally after passing the previous tests, the staging is repeated in production environment. In this phase, a final Canary test can be complemented by developing the new code only on a small subset of servers or even one on server, or one AWS region before deploying code to the entire production environment. Specifics on how to safely deploy to production are covered in the Deployment Methods section.
Let’s now have a look at how to build the pipeline to incorporate these stages and tests.
The Pipeline Formation
Building a pipeline starts by establishing a pipeline with just the components needed for CI and then transitioning later to a continuous delivery pipeline with more components and stages. Let’s now see how we can consider AWS Lamdba functions and manual approvals for large projects, plan for multiple teams, branches, and AWS Regions.
Start With a Minimum Viable Pipeline For Continuous Integration
The journey of an organization toward continuous delivery begins with a minimum viable pipeline (MVP). When it comes to the implementation of continuous integration and continuous delivery, teams can start with a very simple process, such as implementing a pipeline that performs a code style check or a single unit test without deployment.
A key component happens to be a continuous delivery orchestration tool. In order to build this pipeline, Amazon developed AWS CodeStar.
AWS CodeStar uses AWS CodePipeline, AWS CodeBuild, AWS CodeDeploy with an integrated setup process, tools, templates, and dashboard. AWS CodeStar provides everything you need to quickly develop, build and deploy applications on AWS. This allows marketers to start releasing code faster. Customers who are already familiar with the AWS management console and seek a higher level of control can manually configure their developer tools of choice and can provide individual AWS services as needed.
AWS CodePipeline is a CI/CD service that can be used through AWS CodeStar or through the AWS Management Console for builds, tests, and deploys your code every time there is a code change, based on the release process models that you define. This enables marketers to rapidly and reliably deliver features and updates. One can easily build out an end-to-end solution by using the pre-built plugins for popular third-party services like GitHub or by integrating your own custom plugins into any stage of your release process. With AWS CodePipeline one may pay for what one sees. There are no upfront fees or long commitments.
The steps of AWS CodeStar and AWS CodePipeline map directly to the stages viz. the source, build, staging and production CI/CD stages. While continuous delivery is desirable, one can start out with a simple two-step pipeline that cracks the source repository and performs a build action:


For AWS CodePipeline, the source stage can accept inputs from GitHub, AWS CodeCommit, and Amazon Simple Storage Service (AWS S3). Automating the build process is a critical first step for implementing continuous delivery and moving toward continuous deployment. Eliminating human involvement in producing build artifacts removes the burden from your team, minimizes errors introduced by manual packaging, and allows you to start packaging consumable artifacts more often.
AWS CodePipeline works seamlessly with AWS CodeBuild, a fully managed build service, to make it easier to set up a build step within your pipeline that packages your code and runs unit tests. With AWS CodeBuild, one can make it easier to provision, manage, or scale their own build servers. AWS CodeBuild scales continuously and processes multiple concurrently so your brands are not left building in the queue. AWS CodePipeline also integrates with build servers such as Jenkins, Solano CI, and TeamCity.
For example, in the build stage, three actions (unite testing, code style checks, and code metrics collection) run in parallel. Using AWS CodeBuild, these steps can be added as new projects without any further effort in building or installing build servers to handle the load.
The source and build stages shown in the figure AWS CodePipeline – source and build stages, along with supporting processes and automation that supports the transition of your team towards continuous integration. At this level of maturity, developers must regularly pay attention to build and test results. They need to grow and maintain a healthy unit test base as well. This, in turn bolsters the confidence of the entire team in the CI/CD pipeline and furthers its adoption.
AWS CodePipeline is seamlessly integrated with AWS CodeBuild, a fully managed build service to set up a build step within your pipeline that packages your code and runs unit tests. With AWS CodeBuild one needs not provision, manage or scale their own servers. AWS CodeBuild doesn’t allow you to provision, manage or scale your own in-built servers. AWS CodeBuild scales continuously and simultaneously processes multiple builds on one go so that your builds aren’t left waiting in a queue. AWS CodePipeline also integrates with in-build servers such as Jenkins, Solano CI, and TeamCity.
For example, in the following build stage three actions (unit testing, code style checks, and code metrics collection) run in tandem using AWS CodeBuild. These steps can be added as new projects without any further effort in building or installing build servers to manage and handle the load.


The source code and build stages are shown in the figure AWS CodePipeline – source and build stages, along with supporting processes and automation, enabling the transition of your team towards continuous integration. At this level of maturity, developers must constantly pay attention to building and testing the results. A key challenge remains to maintain the healthy unit test base as well. This, in turn, bolsters the confidence of the entire team in the CI/CD pipeline and furthers its adoption.
Continuous Delivery Pipeline
After the continuous integration pipeline has been implemented and supporting processes have been established; teams can start transitioning toward the continuous delivery pipeline. The transition requires teams to automate both the building and deploying applications.
A continuous delivery pipeline is characterized by the presence of staging and production steps, wherein the production step is performed after manual approval.
In the same manner, the continuous integration pipeline was built, and your teams can gradually build a continuous delivery pipeline by writing their deployment scripts.
As per the needs of the application, some of the deployment steps can be abstracted by existing AWS services. For example, AWS CodePipleline directly integrates with AWS CodeDeploy, a service that automates code deployments to Amazon EC2 instances and instances running on-premises, AWS OpsWorks is a configuration management service that helps end-users operate applications using Chef, and to AWS Elastic Beanstalk, a service for deploying and scaling web applications and services.
AWS has detailed documentation on the process of implementing and integrating AWS CodeDeploy with your infrastructure and pipeline.
Once your team successfully automates the deployment of application, the deployment stages can be expanded with various tests. For example, one can add other out-of-the-box integrations with services like Ghost Inspector, Runscope, and others as shown below:


Adding AWS Lambda Functionalities
AWS CodeStar and AWS CodePipleline support integration with AWS Lambda. This integration enables the implementation of a broad set of tasks such as the creation of custom resources within your environment, integration with third-party systems (such as Slack), and scrutinizing the following tasks:
· Rolling out changes to your environment by applying or updating an AWS CloudFormation template
· Creating resources on-demand in one stage of a pipeline using AWS CloudFormation and deleting them in another stage
· Deploy application versions with zero downtime in AWS Elastic Beanstalk with a Lambda function that swaps Canonical Name record (CNAME) values
· Deploying Amazon EC2 Container Service (ECS) Docker instances
· Back up resources before building or deploying by employing AMI snapshot
· Add integration with third-party products to your pipeline, such as posting messages to an Internet Rely Chate (IRC) client
Manual Approvals: AWS Identity and Access Management (IAM) Permissions
An approval action needs to be added to a stage in the pipeline at a point where one wishes the pipeline processing to stop so that someone with the required AWS Identity and Access Management (IAM) permissions can approve or reject the action.
Once the actions are approved, the pipeline processing resumes. If the action is rejected – or if nobody approves or rejects the action within 7 days of the pipeline reaching the action and stopping – the result is the same as an action failing, and the pipeline processing does not continue.


Deployment infrastructure code changes in a CI/CD Pipeline
AWS CodePipeline allows users to select AWS CloudFormation as a deployment action in any stage of your pipeline. One can then choose the specific actions that one would like AWS CloudFormation to perform such as creation or deleting stacks and creating or executing change sets. A stack is an AWS CloudFormation concept that represents a group of related AWS resources. There might be several ways of provisioning Infrastructure as Code, AWS CloudFormation is a comprehensive tool recommended by AWS as a scalable, complete solution that can describe the most comprehensive set of AWS resources as code. AWS recommends using AWS CloudFormation in AWS CodePipeline project to track infrastructure changes and tests.
CI/CD For Serverless Applications
One can use AWS CodeStar, AWS CodePipeline, AWS CodeBuild, and AWS CloudFormation to build CI/CD pipelines for serverless applications. Serverless applications integrate managed services such as Amazon Cognito, Amazon S3, and Amazon DynamoDB with event-driven service, and AWS Lambda to deploy applications in a manner that doesn’t require managing servers. The ones who are serverless application developers can use deploy a combination of AWS CodePipeline, AWS CodeBuild, and AWS CloudFormation to automate the building, testing, and deployment of serverless application developers and can deploy a combination of AWS CodePipeline, AWS CodeBuild, and AWS CloudFormation to automate the building, testing, and deployment of the serverless applications that are expressed in templates built with the AWS Serverless Application Model (SAM).
One can also create secure CI/CD pipelines that follow the best practices of your organization with the AWS Serverless Application Model Pipelines (AWS SAM Pipelines). AWS SAM Pipelines are a new feature of AWS SAM CLI that allows you access to benefits of CI/CD in minutes, such as accelerating deployment frequency, shortening lead time for changes, and reducing deployment errors. AWS SAM Pipelines come with a set of default pipeline templates for AWS CodeBuild/CodePipeline that follow AWS deployment best practices.
Pipelines for multiple teams, branches, and AWS Regions
For a large project, multiple project teams can work on different components. If a single code repository is being used by multiple teams, it can be mapped so that each team has its own branch. There also needs to be an integration or release branch for the final merge of the project. If a service-oriented or microservice architecture is used, each team could have its own code repository.
In the first scenario, if a single pipeline is used it’s possible that one team could affect the other teams’ progress by blocking the pipeline. AWS recommends creating specific pipelines for team braches and another release pipeline for the final product delivery.
Pipeline integration with AWS CodeBuild
AWS CodeBuild has been designed to enable organizations to build a highly available build process with almost unlimited scale. AWS CodeBuild enables quickstart environments for a number of popular languages plus the ability to run any Docker container that you specify.
With the advantages of tight integration with AWS CodeCommit, AWS CodePipeline, AWS CodePipeline, and AWS CodeDeploy, as well as Git and CodePipeline Lambda actions, the CodeBuild tool is highly flexible.
Software can be built through the inclusion of a buildspec.yml file that identifies each of the build steps, including pre-and post-build actions, or specified actions through the CodeBuild tool.
One can view the detailed history of each build using the CodeBuild dashboard. Events are stored as Amazon CloudWatch Logs files.


Pipeline integrations with Jenkins
Jenkins build tool can be used to create delivery pipelines. These pipelines use standard jobs that define steps for implementing continuous delivery stages. However, this approach might not be optimal for larger projects as the current state of pipeline doesn’t persist between Jenkins restarts, implementing manual approval is not straightforward, and tracking the state of a complex pipeline can be complicated.
With AWS one can implement continuous delivery with Jenkins by using the AWS Code Pipeline plugin. This plugin facilitates complex workflows to be described by leveraging Groovy-like domain-specific language and can be used to orchestrate complex pipelines. The AWS Code Pipeline plugin’s functionality can be enhanced by the use of satellite plugins such as the Pipeline Stage View Plugin, which visualizes the current progress of stages defined in a pipeline, or Pipeline Multibranch Plugin, which builds from an array of branches.
AWS recommends storing the pipeline configuration in Jenkinsfile and having it checked into a source code repository. This allows for tracking changes to pipeline code and becomes even more important when working with the Pipeline Multibranch Plugin. AWS also recommends that you should divide their pipeline into stages. This logically groups the pipeline steps and also enables the Pipeline Stage View Plugin to visualize the current state of the pipeline.
The following figure shows a sample Jenkins pipeline, with four defined stages visualized by the Pipeline Stage View Plugin.


Deployment Methods
One can consider multiple deployment strategies and variations for rolling out new versions of software in continuous delivery process. Here are the most common deployment methods – all at a place – rolling, immutable, and blue/green. AWS specified which of the methods are supported by AWS CodeDeploy and AWS Elastic Beanstalk.
The following table summarizes the characteristics of each deployment method.


In-Place Deployment (All at once)
All at once (in-place deployment), is a method that can be used to roll out new application code to an existing fleet of servers. This method replaces all the code in one deployment action. It requires downtime all servers in the fleet are updated at once. There is no need to update existing DNS records. In case of failed deployment, the only way to restore operations is to redeploy the code on all servers again.
In AWS Elastic Beanstalk, this deployment is called all at once and is available for single and load-balanced applications. In AWS CodeDeploy this deployment method is called in-place deployment with a deployment configuration of AllAtOnce.
Rolling Deployment
With rolling deployment, the fleet is divided into portions so that all of the fleets doesn’t get upgraded at once. During the deployment process two software versions, new and old, are running on the same fleet. This method allows a zero-downtime update. If the deployment fails, only the updated portion of the fleet will be affected.
A variation of the rolling deployment method, called canary release, involves the deployment of the new software version on a very small percentage of servers at first. This way, you can observe how the software behaves in production on a few servers, while minimizing the impact of breaking changes. If the rate of errors gets elevated from a canary deployment, the software is rolled back. Otherwise, the percentage of servers with the new version is gradually increased.
AWS Elastic Beanstalk has followed the rolling deployment pattern with two deployment options, rolling and rolling with an additional batch. These options allow the application to first scale up before taking servers out of service, preserving full capacity during the deployment. AWS CodeDeploy accomplishes this pattern as a variation of an in-place deployment with patterns like OneAtTime and HalfAtATime.
Immutable and blue/green deployments
The immutable pattern specifies a deployment of application code by starting an entirely new set of servers with a new configuration or version of the application code. This pattern leverages the cloud capacity that new server resources are created with simple API calls.
The blue/green deployment strategy is a type of immutable deployment that also requires the creation of another environment. Once the new environment is up and passed all tests, traffic is shifted to this new deployment. Crucially the old environment, that is a “blue” environment, is kept idle in case a rollback is needed.
AWS Elastic Beanstalk supports immutable or blue/green deployment patterns. AWS CodeDeploy also supports the blue/green pattern. Thus, AWS services accomplish these immutable patterns.
Changes in the Database Schema
Modern software are likely to have a database layer. Typically, a relational database is used, which stores both data and the structure of data. In the continuous delivery process, it’s often essential to modify the database. Handling changes in a relational database requires special consideration, and it offers multiple other challenges than the ones present when deploying application binaries. Usually, when an application binary is upgraded, you stop the application, upgrade it, and then start it again. You don’t really bother about the application state, which is handled outside of the application.
While upgrading databases, one needs to consider state because a database contains many states but comparatively little logic and structure.
The database schema before and after a change is applied should be considered different versions of the database. One can use the tools such as Liquibase and Flyway to manage versions.
In general, those tools employ some variants of the following methods:
· Add a table to the database where a database version is stored.
· Keep track of database change commands and club them together in a versioned changeset. In the case of Liquibase, these changes are stored in XML files. Flyway employs a slightly different method where the changesets are handled as separate SQL files or occasionally as separate Java classes for more complex transitions
· When Liquibase is required to upgrade a database, it gauzes at the metadata table and determines the changesets that must be run to keep the database up-to-date with the latest version
Wrap Up
While practicing continuous integration and continuous delivery on AWS here are some of the best practices for the end-users to abide by:
a) Treat your infrastructure as a code.
b) Employ version control for your infrastructure code
c) Employ bug tracking or ticketing systems
d) Implement changes according to peer reviews before applying them
e) Establish infrastructure code patterns and / designs
f) Test the infrastructure changes like code changes
The developers should be placed into integrated teams of not more than 12 self-sustaining members. All developers should have committed code to the main trunk frequently with no long-running feature branches.
Marketers can constantly adopt a build system such as Maven or Gradle across organizations and must standardize the builds.
The developers can build unit tests towards 100% coverage of the code base and must ensure that unit tests are 70% of the overall testing in duration, number, and scope. The marketers must ensure that the unit tests are up-to-date and are not ignored. The unit test failures should be fixed and should not be bypassed.
Users should treat their continuous delivery configuration as a code. One can establish role-based security controls (that is who can do what and when). Users may monitor/track every resource possible and should place alerts on services, availability and response times. Ultimately the continuous integration and continuous delivery pipelines must be allowed to be captured, learnt and improved. The access to the CI/CD pipeline must be shared with everyone on the team. Marketers must plan metrics and monitoring into their lifecycle. A track record needs to be kept for all the standard metrics in terms of the number of builds, number of deployments, and average time for changes to reach production and average time from first pipeline stage to each stage. The number of changes reaching production and the average build time needs to be kept a track record of. Marketers should use multiple distinct pipelines for each branch and team.
Marketers should not have long-running branches with large complicated merges and no manual tests need to be performed. There should have no manual approval process, gates, code reviews, and security reviews.
CI/CD pipelines provide an ideal scenario for the application teams within your organization. Developers should simply push code to a repository. The code will be integrated, tested, deployed, tested again, merged with infrastructure, go through security and quality reviews, and should be ready to be deployed with extremely high confidence.
When CI/CD is used, code quality is improved and software updates are delivered quickly and with high confidence that there will be no breaking changes. The impact of any release can be correlated with data from production and operations. It can be leveraged for planning the next cycle, too – a vital DevOps practice that drives the cloud transformation for your organization.












