













Authors:
(1) Todd K. Moon, Electrical and Computer Engineering Department, Utah State University, Logan, Utah;
(2) Jacob H. Gunther, Electrical and Computer Engineering Department, Utah State University, Logan, Utah.
Table of Links
Abstract and 1 Introduction and Background
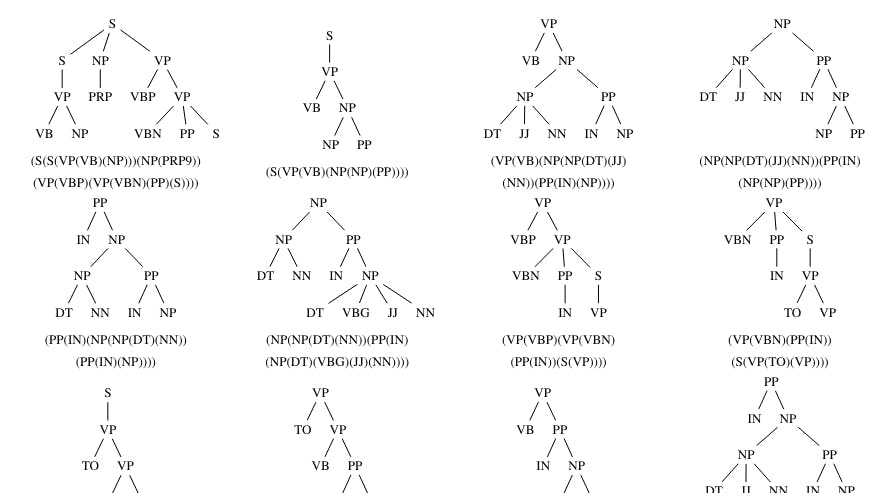
2 Statistical Parsing and Extracted Features
7 Conclusions, Discussion, and Future Work
A. A Brief Introduction to Statistical Parsing
B. Dimension Reduction: Some Mathematical Details
B Dimension Reduction: Some Mathematical Details
This material is drawn from [27]. The trace of Sw provides a measure of the clustering of the feature for each class around their respective centroids,


Note that Sw, being the sum of the outer product of n terms, generically has rank min(n, m). In the work here, the dimension of the feature vectors m is very large, so that rank(Sw) = n; Sw is singular.
Similarly, tr(Sb) measures the total distance between cluster centroids and the overall centroid,


A measure of cluster quality which measures the degree to which tr(Sw) is small and tr(Sb) is large is


To express the algorithm, the following matrices are defined. The scatter matrices Sw, Sb and Sm can be expressed in terms of the matrices


That is, Hm, Hb and Hm form factors of the respective scatter matrices.
The algorithm for computing G is shown below. (adapted from Algorithm 1 of [27]).


References
[1] R. Lord, “de Morgan and the Statistical Study of Literary Style,” Biometrica, vol. 3, p. 282, 1958. [2] A. Morton, Literary Detection. New York: Charles Scribner’s Sons, 1978.
[3] T. Mendenhall, “A Mechanical Solution of a Literary Problem,” Popular Science Monthly, 1901.
[4] C. D. Chretien, “A Statistical Method for Determining Authorship: The Junius Letters,” Languages, vol. 40, pp. 95–90, 1964.
[5] D. Wishart and S. V. Leach, “A Multivariate Analysis of Platonic Prose Rhythm,” Computer Studies in the Humanities and Verbal Behavior, vol. 3, no. 2, pp. 109–125, 1972.
[6] C. S. Brinegar, “Mark Twain and the Quintis Curtis Snodgrass Letters: A Statistical Test of Authorship,” Journal of the Americal Statistical Association, vol. 53, p. 85, 1963.
[7] F. Mosteller and D. Wallace, Inference and Disputed Authorship: The Federalist. Reading, MA: Addison Wesley, 1964.
[8] P. Hanus and J. Hagenauer, “Information Theory Helps Historians,” IEEE Information Theory Society Newsletter, vol. 55, p. 8, Sept. 2005.
[9] D. Holmes, “The analysis of literary style — a review,” J. Royal Statistical Society, Series A, vol. 148, no. 4, pp. 328–341, 1985.
[10] J. L. Hilton, “On Verifying Wordprint Studies: Book of Mormon Authorship,” Brigham Young University Studies, 1990.
[11] D. Holmes, “A Stylometric Analysis of Mormon Scriptures and Related Texts,” Journal of the Royal Statistical Society, A, vol. 155, pp. 91–120, 1992.
[12] K. Luyckx and W. Daelemans, “Shallow text analysis and machine learning for authorship attribution,” in Proceedings of the Fifteenth Meeting of Computational Linguistics in the Netherlands, pp. 149–160, 2005.
[13] J. Grieve, “Quantitative authorship attribution: an evaluation of techniques,” Liter. Linguist. Comput., vol. 22, no. 3, pp. 251–270, 2007.
[14] F. Iqbal, H. Binsalleeh, B. Fung, and M. Debbabi, “A unified data mining solution for authorship analysis in anonymous textual communication,” Inform. Sci, vol. 231, pp. 98–112, 2007.
[15] E. Stamatos, “A survey of modern authorship attribution methods,” J. Am. Soc. Inform. Sci. Technol., vol. 60, no. 3, pp. 538–556, 2009.
[16] C. Zhang, X. Wu, Z. Niu, and W. Ding, “Authorship identification from unstructured texts,” Knowledge-Based Systems, vol. 66, pp. 99–111, 2014.
[17] I. Jolliffe, Principal Component Analysis. New York: Springer-Verlag, 1986.
[18] S. Corbara, B. Chulvi, and A. Moreo, Experimental IR meets multilingality, multimodality, and interaction, vol. 13390 of Lecture Notes in Computer Science, ch. Rythmic and Psycholinguistic Features for Authorship Tasks in the Spanish Parliament: Evaluation and Analysis. Springer, 2022.
[19] S. Corbara, C. C. Ferriols, P. Rosso, and A. Moreo, Natural Language Processing and Information Systems, vol. 13286 of Lecture Notes in Computer Science, ch. Investigating Topic-Agnostic Features for Authorship Tasks in Spanish Political Speeches. Springer, 2022.
[20] M. Sanchez-Perez, I. Markov, H. Gomez-Adorno, and G. Sidorov, ´ Experimental IR Meets Multilinguality, Multimodality, and Interaction, vol. 10456 of Lecture Notes in Computer Science, ch. Comparison of Character n-grams and Lexical Features on Author, Gender, and Language Variety Identification on the Same Spanish News Corpus. Springer, 2017.
[21] D. Klein and C. D. Manning, “Accurate unlexicalized parsing,” in Proceedings of the 41st Annual Meeting on Association for Computational Linguistics, vol. 1, pp. 423–430, 2003. https://doi.org/10.3115/1075096.1075150.
[22] M. P. Marcus, B. Santorini, and M. A. Marcinkiewicz, “Building a Large Annotated Corpus of English: The Penn Treebank,” Computational Linguisistics, vol. 19, no. 2, pp. 313–330, 1993.
[23] A. Taylor, M. Marcus, and B. Santorini, “The Penn Treebank: An Overview.” https://www. researchgate.net/publication/2873803_The_Penn_Treebank_An_overview, 2003.
[24] D. Klein and C. D. Mannning, “Accurate unlexicalized parsing,” in Proceedings of the 41st Meeting of the Association for Computational Linguisistics, pp. 423–430, 2003.
[25] T. S. N. L. Group, “Software: Stanford parser.” https://nlp.stanford.edu/software/ lex-parser.html, 2020.
[26] D. Juraksky and J. H. Martin, Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition. Upper Saddle River, NJ: Prentice-Hall, 2009.
[27] P. Howland, M. Jeon, and H. Park, “Structure preserving dimension reduction for clustered text data based on the generalized singular value decomposition,” SIAM J. Matrix Anal. Appl., vol. 25, no. 1, pp. 165–179, 2003.
[28] T. K. Moon, P. Howland, and J. H. Gunther, “Document author classification using generalized discriminant analysis,” in SIAM Conference on Text Mining, (Baltimore, MD), May 23–25 2006.
[29] P. Howland, J. Wang, and H. Park, “Solving the small sample size problem in face recognition using generalized discriminant analysis,” Pattern Recognition, vol. 39, pp. 277–287, 2006.
[30] A. Hamilton, J. Madison, and J. Jay, “The Federalist,” in American State Papers (R. M. Hutchins, ed.), vol. 43 of Great Books of the Western World, pp. 29–266, Encyclopedia Britannica, Chicago ed., 1952.
[31] A. Hamilton, J. Madison, and J. Jay, “The Federalist (machine readable).” http://www.gutenberg.org /etext/18.
[32] P. Poplawski, A Jane Austen Encyclopedia. London: Aldwych Press, 1998.
[33] J. Austen and A. Lady, Sanditon. London: Peter Davies, 1975.
[34] D. Hopkinson, “Completions,” in The Jane Austen Companion (J. D. Grey, ed.), Macmillan, 1986.
[35] “Sanditon (machine readable).” http://etext.lib.virginia.edu/toc/modeng/public/ AusSndt.html.
This paper is available on arxiv under CC BY 4.0 DEED license.












