












Authors:
(1) Ben Athiwaratkun, AWS AI Labs;
(2) Sujan Kumar Gonugondla, AWS AI Labs;
(3) Sanjay Krishna Gouda, AWS AI Labs;
(4) Haifeng Qian, AWS AI Labs;
(5) Sanjay Krishna Gouda, AWS AI Labs;
(6) Hantian Ding, AWS AI Labs;
(7) Qing Sun, AWS AI Labs;
(8) Jun Wang, AWS AI Labs;
(9) Jiacheng Guo, AWS AI Labs;
(10 Liangfu Chen, AWS AI Labs;
(11) Parminder Bhatia, GE HealthCare (work done at AWS);
(12) Ramesh Nallapati, Amazon AGI (work done at AWS);
(13) Sudipta Sengupta, AWS AI Labs;
(14) Bing Xiang, Goldman Sachs (work done at AWS).
Table of Links
3.1. Notation and 3.2. Language Model Inference
3.3. Multi-Query, Multi-Head and the Generalized Multi-Query Attention
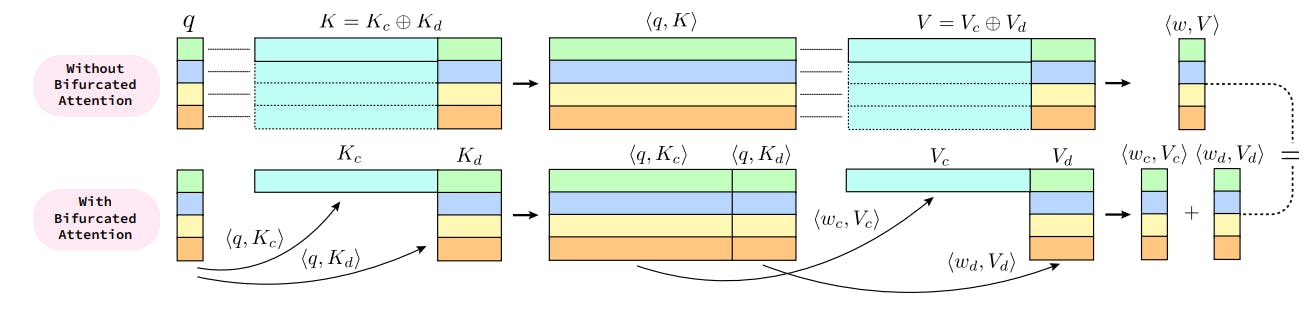
4. Context-Aware Bifurcated Attention and 4.1. Motivation
4.2. Formulation and 4.3. Memory IO Complexity
5.1. Comparing Capabilities of Multi-Head, Multi-Query, and Multi-Group Attention
5.2. Latencies of Capabilities-Equivalent Models
D. Multi-Group Attention Family
E. Context-Aware Bifurcated Attention
F. Applications: Additional Results
G. Compatibility with Speculative Decoding and Fast Decoding techniques
5. Experiments
We first conduct experiments to see how capabilities scale with respect to model size for each attention type in Section 5.1. We find that attention types with higher compression (lower number of attention groups g) require model size compensation, ≈ 10% for multi-query (g = 1). We use such findings to compare the latency between the multi-head and the larger multi-query models of equal capabilities in Section 5.2. In Section 5.2.2, we focus on the single-context batch sampling scenario where we demonstrate the significant latency reduction of bifurcated attention and revisit the comparison between multi-head and multi-query in light of bifurcated attention. We outline inference details in Appendix C.5.


5.1. Comparing Capabilities of Multi-Head, Multi-Query, and Multi-Group Attention


To compare the capabilities of different attention mechanisms, one can either scale other model configurations such as the number of layers ℓ, the number of heads h in order to make match the total model sizes between different attentions. However, it is often difficult to match the number of parameters exactly. In this work, we compare different attention mechanisms via the loss-vs-size scaling laws. For the setup, we use the model hyperparameters similar to that of GPT-3, where the size ranges from 125M to 13B, with hyperparameters such as ℓ, h, k increasing in tandem. Then, we consider three cases where g = 1 (multi-query), g = h (multi-head) and 1 < g < h (multi-group) where Appendix C.1 and C.2 shows the training and model configuration details. We train all three attention models of each size and plot the validation loss versus model size, shown in Figure 3. Our findings are summarized below.
Higher number of attention groups g leads to higher expressiveness The results in Figure 3 shows the validation loss versus model size (log scale). The results indicate that, for the same model size (vertical slice across the plot), multi-head attention g = h achieves the lowest validation loss compared to 1 < g < h (multi-group) and g = 1 (multiquery). This trend holds consistently over three orders of magnitude of model sizes, where the curves corresponding to multi-head, multi-group and multi-query do not cross, implying that the rank of model expressiveness, or relative capabilities per number of parameters, is quite stable. An intuitive explanation is that the lower g corresponds to a lower rank representation of the key and value tensors, which encodes lower representation power of the past context and therefore yields lower capabilities than higher g, given the same model size.
Scaling laws via downstream performance We use the average scores from two code generation benchmarks, multilingual HumanEval and MBXP (Athiwaratkun et al., 2022), as a proxy for model capabilities in addition to the validation loss. This approach is similar to that of the GPT-4 technical report (OpenAI, 2023) where HumanEval (Python) (Chen et al., 2021) is used to track the performance across multiple magnitudes of compute. In our case, we average across all 13 evaluation languages and two benchmarks to obtain a more stable proxy for capabilities. The result in Figure 3 demonstrates similar trend compared to the validation loss where the pass rate curves indicate the same relative expressiveness for multi-head, multi-group and multi-query attention.
Matching capabilities by model size compensation Given the same capabilities (horizontal slice of the plot in Figure 3), the distance between two curves indicates the model size difference that the lower-rank attention needs to compensate in order to match the multi-head model performance. Empirically, we average the distance along the interpolated lines (log scale) and find this to correspond to 1.104 times; that is, a multi-query model can have the same capabilities as the multi-head model if the size is increased


by ≈ 10% of the multi-head model size. Similarly, the gap is < 10% for multi-group attention. Alternatively, one can argue that a multi-query model of the same size could match a multi-head if the multi-query model is given more compute. However, in the regime where we train language models until or close to convergence and the performance saturates with respect to compute, the difference in capabilities will likely remain. Therefore, the size compensation is likely the most fair approach for comparison.
This paper is available on arxiv under CC BY 4.0 DEED license.












