This post tells the story of how I built an image classification system for Magic cards using deep convolutional denoising autoencoders trained in a supervised manner. There are tens of thousands different cards, many cards look almost identical and new cards are released several times a year. Combined, this makes for a highly interesting Machine Learning challenge.
Come join me on this journey from inception of the idea through to the analysis of existing systems over lows when it looked like it would never work, to highs such as discovering how well-known methods could be combined in novel ways to solve the seemingly unsolvable, and finally the feeling of redemption when the system finally came alive!
While Magic cards are indeed toys, this is not a toy example. It is an example of a real-world problem, to which the solution could be the basis for real, healthy businesses!
I should stress that this is not a tutorial, I will not provide source code (maybe in a later post) and I cannot promise you will know exactly how to build your own system after reading this post. What I can promise, though, is you will get a unique insight into the thoughts and process that went into creating a Machine Learning system for a real-world problem!
I don’t expect you to know (or even care) about Magic cards, but to get the most of this post, you should have at least a basic understanding of Machine Learning. You don’t need to be able to do backpropagation by hand, but you should at the very least know that a neural network consists of a number of layers (and now you do!).
Inception
I got the idea when I was working for Vivino. In case you don’t know Vivino, they have a really cool app by the same name which you can use to take photos of wines. The Vivino app can then detect what wine is in the image and show you detailed information for that wine, such as taste notes, ratings and reviews. Finally, if available, you will also get the opportunity to buy the wine online.


The Vivino iOS app
Now, Magic, or Magic: the Gathering, as it is properly called is a trading card game. In other words, a Magic card is a playing card. But these are far from ordinary playing cards — and there are a lot more different Magic cards than the 52 cards you have in an ordinary deck of cards. In fact, over 36,000 different cards have been released to this date (and that is counting English cards only).


More than 36,000 different Magic cards have been released to this date.
In many ways, Magic cards are a lot like wine. There are many thousand different cards just like there are many thousand different wines. Some cards are cheap, some are expensive. People collect them and they are traded online. One day, when I was playing Magic with some colleagues after work, it came to me: Why not build an app like Vivino but for Magic cards? You’d be able to shoot a photo of a card, have the app find the card in the database and give you detailed information about the cards, maybe tell you how many copies of that card you have in your collection and let you buy more online. Not too bad, eh?
Existing Systems
Unfortunately, like most great ideas, this one wasn’t new. Several card scanner apps such as the TCGplayer app were already in the App Store. So, reluctantly I put the idea to rest and tried not to think more about it. But, for some reason, the thought wouldn’t leave me. It kept popping up again and again. One evening, I started digging into how the existing apps worked, and found some videos and some blog posts. As it turned out, most — if not all — existing apps took the approach of combining something called rectangle detection and perceptual hashing. I will explain both rectangle detection and perceptual hashing below but let me start by pointing out that I used neither when building my system. But I do believe knowing what they are makes it easier to understand both the problem and my solution, and they are very useful techniques. So let’s dive right into the first one, perceptual hashing.
Existing Systems Explained: Perceptual Hashing
Perceptual hashing is a way to compute a hash, or fingerprint, of the image that somehow reflects the visual content of the photo. There’s a short introduction to perceptual hashing here and another one here. A simple form of perceptual hashing is average hashing (explained in both of the above links — if my short explanation below leaves you confused, please go back and read one or both of the links). The average hash is an array of bits which can be computed like this:
- First, resize the image to something small such as 8x8. This has the effect of making the remaining computations very fast and it also removes high frequency noise in the image.
- Convert the image to grayscale. Again, this makes the remaining calculations faster but it also has another desired effect: It makes the algorithm more robust to varying lighting conditions.
- Compute the mean of the grayscale values.
- Now the actual hash or fingerprint can be computed. Each bit in the hash is set to 0 or 1 based on whether the corresponding pixel in the (resized, grayscaled) image is below or above the mean computed in the previous step.
One real nice thing about perceptual hashing is the fingerprints of two images can easily and very quickly be compared by simply counting how many bits are different between the two images. This way of measuring how different two arrays are is called the hamming distance.
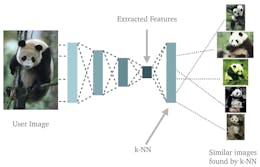
To use the fingerprints for classification you would first need to obtain a single image of every known card. We will call these images the reference images. You could then compute the fingerprint for each of those. At prediction time, the user would give you an image to classify. We will call this the query image. You would compute the fingerprint for the query image and then you can simply compare that fingerprint to the fingerprints of the reference images (using the hamming distance) and find the one with the smallest distance.
Of course, the above procedure requires that you can obtain the reference images in order to compute their fingerprints. Luckily, this is relatively easy because nice, clean and tightly cropped scans of every card ever released are widely available online.
Existing Systems Explained: Rectangle Detection
Let’s now look at the other main part of existing Magic card scanner apps, namely rectangle detection. As we saw above, the procedure for classification using perceptual hashing is relatively straightforward. Remember I said the reference fingerprints are computed on nice, clean and tightly cropped scans of the cards? The query images, taken by the users, however are most likely neither clean nor tightly cropped and they are definitely not scans (from a flatbed scanner or similar). Most likely, they are taken from an oblique angle, the card may be in a sleeve and reflections from artificial lighting will be all over the place as seen in the example below.


Left: User photo on a black wooden table. The user has been sloppy when taking the photo — the card is rotated, there’s a lot of reflection and someone has written the letters MP on the sleeve. Right: The corresponding reference image.
Because of this difference between users’ photos and reference images, the query fingerprints will be very different from the reference fingerprints and consequently comparing them for classification will not work well. Rectangle detection can to some degree remedy this. Rectangle detection is used, as the name suggests, to detect rectangles in images. This can be used to detect the border of the card. Knowing the location of the border, the photo can be cropped and straightened.

Left: User photo with rectangle detection applied. It now more closely resembles the reference image but upper left corner is still showing reflections, lower left corner is darker from the shadow cast by the user’s hand and the text writen on the sleeve is still visible. Right: The corresponding reference image.
Having cropped and straightened the photo to make it look more like a scan, the fingerprint can now be computed, and hopefully comparing this improved fingerprint will work better. Even with rectangle detection however, there are still problems for the perceptual hashing approach, mainly:
- The cropping and straightening does not remove reflections.
- The rectangle detection is very sensitive to the background. Put the card on a gray table and it will likely work every time. Put it on a wooden table and it will probably fail most of time.
- For the perceptual hashing to work well, the images need to be downsized to remove high frequency noise. This causes a loss of detail which hurts the prediction accuracy.
Alternative to Existing Systems: Deep Learning
Luckily for me, this was exactly what I had been waiting for: An excuse to build my system! While I think perceptual hashing is tremendously cool (and it’s extremely fast), my hope was, using a deep learning approach, I could solve the three problems mentioned above:
- Instead of using rectangle detection to crop and straighten the images, I could train the system to simply ignore the reflections and the oblique angles.
- Instead of forcing the user to take photos on a gray table, I could provide training examples with all sorts of colored and patterned backgrounds.
- I would only have to scale down the images enough to make the classifier train and make predictions in a reasonable time.
So that’s how the idea for the system was born. Let us now move on to take a look at some interesting characteristics of our classification problem.
Requirements
As you will remember from above, over 36,000 different cards have been released. Further, many of them look very similar and new ones are released regularly. Some of the cards are long out of print, extremely rare and thus extremely expensive. It’s not unusual for cards to sell for a few hundred USD and the most expensive ones sell for more than 10,000 USD. Therefore we are highly unlikely to ever get our hands on them and consequently we cannot take photos of them to include in our training data. This sets us up for an interesting challenge. We must build a system that can:
- Handle image classification into over 36,000 different classes
- Work without expensive retraining when new classes are added to the universe
- Work on classes that we do not have training data for
- Be trained without a prohibitively huge dataset
We will discuss the outlook of using a relatively standard deep convolutional network and based on that rather bleak outlook, we will turn our focus to the denoising autoencoder and see how that is implemented. But first, let’s look at our problem in a bit more detail.
Standard Image Classification With Deep Neural Networks?
Image classification is an area where deep learning and especially deep convolutional networks have really proven their strength. Put very simply, in image classification the task is to assign one or more labels to images, such as assigning the label “dog” to pictures of dogs. Let’s say we were building an image classifier to distinguish between images of cats, dogs and birds. One way to go about this would be to build a neural network with three outputs: One for cat, one for dog and one for bird. We could then train the network to output the value 1.0 on the output node corresponding to the animal in the input image and 0.0 on the other nodes. This is completely standard.
What makes Magic card classification an interesting challenge are the four requirements we stated above (a system that works with 36,000 different classes, doesn’t need retraining when new classes are added, works on classes we don’t have training data for and can be trained without an enormous training set). They are the reason why the standard deep neural network doesn’t cut it. Let’s see why.
- The first requirement is in theory satisfied: You could make a neural network with 36,000 outputs.
- Unfortunately, the second requirement doesn’t hold: we cannot add more classes when new cards are released without having to retrain the system. The reason is we would have to add a number of output nodes equal to the number of newly released cards and thus have to retrain the entire system.
- The third requirement doesn’t hold either: The network would have no chance of working for cards we do not have training data for, even if we made sure to add output nodes for them.
- Finally, training the system would require an enormous training set. When training a deep neural network for image classification, a rule of thumb says you need roughly 1,000 training examples per class to achieve “good” performance and 10,000 examples to achieve “excellent” performance. If we settle for “good” performance (and why should we?) we would still need around 36,000,000 training examples according to the rule of thumb.
So, at this point it was clear that a standard neural network for image classification would not suffice. I had to think of something else. Maybe a technique such as transfer learning could be the answer? Read on to find out.
Transfer Learning?
One extremely useful technique in deep learning is what is called transfer learning. As the name suggests, you can transfer what you have learned for one problem to a system used for another problem. You typically do this by taking an existing network and reusing all layers except for the last few layers. Let’s see why this often works and why it doesn’t suffice for our problem.
In image recognition based on deep convolutional networks, the early layers of the network learn to detect very simple features in the image such as edges or corners. The next layers then learn to combine the simpler features to more abstract features, possibly detecting circles or rectangles or other geometric shapes. The later layers learn to combine the more abstract features to even more abstract features such as an eye or an ear. The later layers again then learn to combine those features to detect for example cats or dogs. Imagine you are to build a system to distinguish between bears and wolves. If you already have a network that you — or someone else — have trained to distinguish between cats, dogs and birds, this would be a great case for transfer learning. All the most basic features such as edges and corners all the way up to the abstract ones such as eyes and ears that the network has previously learned would most likely be relevant for classifying bears and wolves as well. Thus, we could reuse all the layers from the existing networks except the last few layers which are specific to each of the three animals. Reusing most layers of the existing networks, we would have good chances of building a usable classifer using as few as hundreds or even tens of images per class.
As you can see, transfer learning can be very useful. And the network you use to transfer from doesn’t have to be your own. Several big networks that have been trained for weeks on millions of images to distinguish between thousands of classes are available for free online. Unfortunately, just using transfer learning does not satisfy our requirements either. First, we would still have to retrain the system when new cards are released (though being able to reuse the layers from the original network would definitely cut down on training time). Secondly, transfer learning does not in itself help us build a system that can work for cards we do not have training data for. And finally, while transfer learning drastically reduces the number of required training examples per class to as few as ten that would still mean we would have to obtain 360,000 labeled images.
The Solution: Fingerprinting With Neural Networks
Having thought long and hard on the challenges detailed above, I admit I didn’t think the outlook was too good. I would never be able to get 360,000 images let alone 36 million labeled training images. I would have to find a away around needing that much training data. Then it occurred to me, I could take inspiration from the fingerprinting approach taken by the existing systems! As we have seen, the usual networks for classification have a number of outputs equal to the number of classes they can distinguish and they learn to set the output corresponding to the class of the input image to 1.0 and all others to 0.0. That kind of architecture works well if you have only a few classes but it is exactly what causes the problems we have seen with regards to the amounts of training data required for our 36,000 classes. So why not forget about making the network compute a classification and instead simply make it compute a fingerprint?
If I had a network that could compute robust fingerprints, I could use a process almost identical to the one used when building classification on top of perceptual hashing:
- Obtain a set of reference images consisting of exactly one scan of every card.
- Make the neural network compute the fingerprint for all reference images.
- At prediction time, compute the fingerprint for the query image and compute the distance to all the reference fingerprints and find the closest reference image.
This approach was what eventually made me succeed in building the system. But before we get to that, let’s discuss three important challenges.
First, it’s not immediately clear how we could learn such fingerprints. It’s not even clear, given an image, what the fingerprint for that image should be. Because we do not know what the fingerprint for each reference image should be it appears we cannot use a supervised approach (spoiler: but eventually we will).
Secondly, the fingerprints must contain enough information to correctly distinguish between even the most similar looking cards. One approach to tackling the first challenge and making the system train in a supervised way might be to output fingerprints identical to the ones resulting from perceptual hashing. This could possibly make the system robust to different backgrounds and to reflections but it would not solve the other inherent problem with the fingerprints: Information loss resulting from downscaling the images during hashing. To understand why this is important, we have to dig a bit deeper into the history of Magic. The first cards were released in 1993. Since then, new cards have been released on a regular basis in so-called sets. Each set can be distinguished from the others by more or less obvious visual clues. Newer sets have so-called set symbols, small icons on the right side of the cards. Some of the older sets do not have such symbols. Some cards are printed in multiple sets, sometimes with the exact same artwork. One such card is Elvish Archdruid, which has been printed in several different sets.


The same card, Elvish Archdruid, printed in three different sets.
As can be seen from the above three versions of Elvish Archdruid, only very tiny visual clues distinguish the three different versions of the card. Especially hard to distinguish are the center and rightmost cards as only the set symbols and the tiny white bottom text differ. The fingerprints we choose must contain enough detail that we can predict not only the correct card but the correct card from the correct set.
Now to the third and final challenge. No matter what kind of fingerprints we train the system to output, they must have one very important property: They must be easily and reliably compared to each other. The perceptual hashes are really nice because they can be compared using hamming distance. But that is definitely not the case for all fingerprints. If there is no meaningful way of comparing the fingerprints, our strategy of finding the most similar reference images will not work. Luckily, the deep learning toolbox provides us with a technique for building fingerprints, except they are not called fingerprints, they are called representations, codes or encodings. This technique is called autoencoders.
Autoencoders
Autoencoders are nothing new, they go back to at least 1987. They were used to help train multilayer networks before modern techniques such as batch normalization, various forms of intelligent initilization and better optimization techniques were invented. Indeed, they helped start the deep learning revolution because at the time it was more or less impossible to train deep networks without them (see for example Greedy Layer-Wise Training of Deep Network by Bengio et al.).
A vanilla autoencoder works like this: You train a network to output exactly what you give it as input. This may seem silly because it’s hard to see how that could be useful. But as you will soon see it is in fact quite brilliant! The idea is that in addition to training the network to output its input, you also apply some constraints. A common constraint is to insert a bottleneck layer in the middle of the network. This bottleneck layer is given a dimensionality much smaller than the input and output. This forces the network to not just pass the input through to the output (by learning the identity function) because the bottleneck layer is deliberately too small to contain all the information in the input image. You can think of the bottleneck layer as computing a distilled or compressed version of the input which the decoder part of the autoencoder then learns to decode back to the original input. This compressed version of the input is called a representation, encoding or sometimes simply code. More importantly, it is what we will use as our fingerprint. Generally, when the autoencoder has been trained, you throw away the decoder part and use only the encoder (because the encodings or fingerprints are what you are really after).


The basic architecture of an autoencoder.
This kind of learning is called self-supervised learning because the system is indeed trained in a supervised manner using a loss function and backpropagation but it does not need labeled data. Consequently, autoencoders can be trained when you have access to only very little labeled data but vast amounts of unlabeled data which is a quite common situation. Autoencoders have traditionally been used for pretraining: You would first train the autoencoder on an unlabeled dataset and then add a couple of fully connected layers, freeze the original weights and then train the last layers on your smaller set of labeled data. This way, an autoencoder is used as the base for training a classifier and, indeed, if you use your favorite search engine to search for autoencoders for classification you will see several examples of this.
Unfortunately, I could not use the approach of adding layers on top of the encoder and training the system to directly output class predictions. This would result in all the trouble with regards to not working on new cards as well as requiring training examples for all cards that we discussed earlier (because basically it would just be a standard image classification network). My approach was, as discussed above, to use the representations as fingerprints and compute the classifications by comparing query and reference fingerprints. As we also discussed above, this assumes that the representations or fingerprints computed by the autoencoder can be easily and reliably compared. And as we shall see below, fortunately, they can.
Cosine Distance
The representations computed by the encoder turn out to have the very convenient property that they can be compared using cosine distance. The cosine distance is basically the angle between two vectors. Remember how the fingerprint used in perceptual hashing were arrays of bits. The fingerprints computed by the autoencoder are different in that they are not bit arrays, they are vectors of real numbers — and those vectors can be compared using cosine distance. While the actual fingerprints computed by the autoencoder are vectors of hundreds of dimensions, imagine for a moment they had only two dimensions: each fingerprint would consist of two real numbers. We can think of those two numbers as a pair consisting of an x-value and a y-value. This means we can visualize them as shown below.


The cosine distance measures the angle between two vectors. A small angle means a small distance.
From the above figure we can easily grasp how the angle between two vectors could be measured if the vectors are two-dimensional. You can probably imagine that it would work if the vectors were in 3D as well. In fact, it works for any number of dimensions and thus we can use cosine distance to measure the distance between two fingerprints.
Cosine distance has commonly been used on what could be described as content based recommender systems. Imagine you have an online store that sells clothes. Perhaps you would like a recommender feature of the kind that says “if you like this item, maybe you will like these similar ones”. Such a system could be built by training an autoencoder on your entire set of product images. You can then recommend products which have encodings (fingerprints) similar to the encoding for the product the user is currently viewing.
So basically, we have seen two common uses for autoencoders:
- Pre-training a network for classification. When the autoencoder has been trained in a self-supervised manner, a couple of fully connected layers are added on top and trained in a standard supervised manner.
- Content based recommender systems for finding products with similar encodings using cosine distance.
My approach was, in a sense to simply combine the above. I use the autoencoder for classification but I did not add fully connected layers like in the first of the above. Instead I computed the cosine distance between query images and reference images like in the second of the above.
I had not previously seen this done. I’ve only been able to find one paper, which discusses combining autoencoders and nearest neighbor classification and they use it only for problems with few classes which are all known in advance. Thus, I believe my take is a novel approach. To stress why this approach is important, let’s remind ourselves of the challenges we set out to solve:
- The system should be able to handle image classification into over 36,000 different classes. Technically, I didn’t know yet whether this would work. But, since what is computed is fingerprints — as opposed to specific class predictions — it was at least not obviously limited to any number of classes.
- The system must work without expensive retraining when new cards are released. Since we are not using the actual classes when training the autoencoder, it does not know about the classes and hence should work without retraining once new cards are released. For this to work, however, the computed fingerprints must generalize to the newly released cards. This hinges on point three below.
- The system should work on cards that we do not have training data for. Again, since the autoencoder does not know about the classes, it can in theory work for classes not in training data. This assumes the fingerprints it learns are general enough that they work for unseen cards. It also assumes we have access to reference images of all cards including when new cards are released.
- Be trained without a prohibitively huge dataset. Whether this requirement could be satisfied was not clear yet. But at least the rule of thumb saying 1,000 images per class did no longer apply since the network was no longer doing classification by itself.
So, four out of four requirements now seem like they are surmountable or at least not definitely impossible! It seems plausible that the encodings computed by an autoencoder can be compared using cosine distance and thus can take the place of the fingerprints computed by perceptual hashing. And hopefully they can do an even better job. There is one thing we gracefully skipped, though, and that is the question of how we make the system robust to oblique angles, reflections, various backgrounds and other obstacles. In the section below, you will see how I did this using an approach to so-called denoising autoencoders that almost makes them not autoencoders.
Denoising Autoencoders
When I discovered I could possibly use autoencoders for this problem, I did not yet have any training data. So I had to get started building a dataset. For the system to work, I would at the very least have to gather a set of reference images. Several places online have more or less complete sets of card scans. One such place is magiccards.info. Another one is the official Gatherer site. I chose to build my set of reference images on the former but in hindsight I should probably have chosen the latter. In any case, I wrote a script that could download the images, let it run and then went to sleep.
When the download script had completed, I had a complete set of reference images. I made sure they were all labeled in the sense that the particular card name and set was reflected in the filename. The only question now was, how do I go about training this system?
I quickly realized just training a regular autoencoder on the reference images would not be of much help: The system may very well learn to encode and decode the reference images perfectly but we have no reason to believe that such a system would produce usable encodings on the user images. Specifically, it would not have had a chance to learn to crop and straighten the images or ignore the reflections. I needed some way to train the system to produce the same encoding for a given card no matter if the input was a user image or the reference image.
Then it dawned on me: I should not just use the reference image as both input and output. I should also feed it the user photo as input and train the system to output the reference image. This was something I had not seen anywhere else but eventually it turned out to be what made the entire system work!


The basic architecture of my denoising autoencoder.
So-called denoising autoencoders are trained in a similar yet still different way: When performing the self-supervised training, the input image is corrupted, for example by adding noise. The task for the denoising autoencoder is then to recover the original input. This is similar to my approach because the input and expected output are not identical. But it’s different in the sense that in the ordinary denoising autoencoder, the input is generated by corrupting the expected output while my approach was to use two different images of the same card, namely a user photo and the reference image.


The evolution of the autoencoder as it is being trained. Top: Training images. Bottom: Output from the autoencoder.
The above video shows the evolution of the autoencoder as it it is being trained. The top row shows the input images and the bottom row is the output from the decoder. You can see how it learns to crop and straighten the images. It’s important to note that the input images are images from the training data. Running on images from the test set provides far less impressive reconstructions. (This, however, is in itself interesting: The encoder part of the autoencoder clearly learns generalizable features — otherwise the system as a whole would not provide good classifications. But the decoder may be overfitting to the training data. Luckily, the decoder is thrown away after training, so it is not of much concern but still somewhat interesting that the decoder can severely overfit while the encoder does not).
Are these really autoencoders?
If (denoising) autoencoders are defined by the way they are trained in a self-supervised manner, we could almost say that my system is not even an autoencoder: While the classic autoencoder is trained to output the exact input it was given, the denoising autoencoder is trained to input a non-distorted version of a distorted input. In both cases, the input training data can be generated from the output training data. This is not the case in my system. Here the output is a reference image while the input is a photo. It’s a photo of the same card but it is not generated from the reference image. In this sense, my system is not self-supervised and hence you might prefer to not call it an autoencoder at all. That is however only one perspective. Another perspective is, both the reference images and the input photos are images of the same cards, and as such the input photos could have been generated from the reference images: Given enough time and resources, I could have printed the reference images on cardboard, cut them out and shot the photos. In that case the input photos would absolutely be noisy versions of the output images — the noise would just have been manually generated. That is why I think of the system as an autoencoder.
The Data
At this point in time, I did not have any real user images. I did not yet know how many I would need but I guessed it would at the very least be in the thousands. So I figured I might try to artificially build images visually similar to user photos from the reference images using augmentation. This would make the approach much closer to a regular denoising autoencoder since the input would now be generated from the expected output. Unfortunately, this approach did not work at all. The figure below shows a reference image on the left and the augmented image on the right.


Left: Reference image. Right: Reference image augmented to simulate a user photo.
As you can see, the augmentations I used were rather crude, especially the reflections. This probably explains why it didn’t work and there is definitely room for further work with regards to the augmented images. I currently believe the augmentations were simply not visually similar enough to the actual user images. If I ever get the time to investigate this further, I would look into actual 3D renderings of the cards, preferably using a raytracer or similar. Then I could have proper reflections and shadows as well as lens distortions and proper perspective.
When I had given up on the augmented images, I pulled up the sleeves, found my collection of cards and started taking photos. This was a slow and tedious process but since I hadn’t made the augmentations work, it had to be done. I made sure to add some variance to the photos by shooting from different angles and distances. I shot some photos on a wooden dinner table, some on our blackened steel kitchen table, some on a piece of gray cardboard with lots of paint stains and so on. I also made sure to shoot at different times of the day, moving around to get natural light from different directions and moving the artificial light sources to have reflections and shadows vary. To some extend I also used different camera phones to avoid overfitting to the lens and sensor of a particular brand and model. Arranging the cards on the table for taking photos does take some time, so I made sure to take several pictures of each card from different angles and distances to maximize the outcome of the time spent arranging the cards.


Cards lined up, ready to shoot photos!
Shooting the photos was time consuming but the most mind numbing work was actually annotating or labeling them afterwards. I decided to simply use the filenames for the labeling so each image file would have to be renamed to match the filename of the corresponding reference image (which was in turn named after the number that particular card was given on magiccards.info). Fortunately, after having manually renamed the first few thousand images, I could train the system and then have it help me rename the files. That helped a lot. Instead of manually renaming every single image, all I had to do was verify the predictions and change the few among them that were wrong.
A Couple of Notes on the Test Set
Remember, one of the requirements for the system was that it should work on cards which were not seen in the training data. We will now dive a bit deeper into that requirement.
As of today, I have a training set of 14,200 images and a test set containing 3,329 images. Note that the number of training images is less than half the number of classes (36,000). Further, the training set contains images of only 1,793 different cards which is less than 5% of the number of classes! In other words we have access to training examples for only a small fraction of the total number of cards. This makes it extremely likely that, once the system is running in the wild, it will be used predominantly on cards which it has not been trained on. When we measure the system’s performance using the test set, we want to most closely measure the performance we would see when running in the wild. Consequently, we must take deep care to measure performance on cards which were not in the training data. This is important so let me just reiterate. What I am saying is not just that the images must not be in the training set (as would be standard procedure when building a test set). Here, the cards in the test set are not seen in in the training data at all. In other words, we are only testing on completely unseen classes! This ensures we can expect our accuracy measurements to generalize to other unseen cards such as cards that are too expensive for me to buy or cards that are yet to be released.
It is also worth highlighting that the training set makes up almost 20% of the entire dataset which is a bit more than you would usually see. The reason is, cards were chosen for the test set first and then only the remaining cards were used for the training data. For every set, I did the following:
- First, I randomly chose a card of every color from the cards that I had photos of.
- All photos of the chosen cards were then added to the test set.
- Finally, all photos of remaining cards from that set are added to the training data.
This process ensures that the test set is as evenly distributed across colors and sets as possible given the cards that I had access to. Again, all this was done to maximize the chances that the accuracy results would generalize to cards that other people have, including cards yet to be released.
Results
I measured accuracy on the test set detailed above. When classifying user photos, we will of course strive to get the predictions fully correct in the sense that we find not only the right card but the right card from the right set. But in case that’s not possible, it is far better to get the right card from the wrong set than getting a completely wrong card. Consequently, I measured accuracy for correct card + correct set as well as for correct card (but not necessarily correct set). The numbers are shown below.
- Correct card + correct set: 91.29%
- Correct card: 97.12 %
Acknowledgements
Thanks a million times to the best local games and comics shop, Faraos Cigarer, for their support and encouragement and not least for letting me take pictures of their cards!
Future Work
There’s still a lot of stuff I’d like to do with this. First of all, I’d like to build a proper app and release it to the App Store. But there are also more machine learning related things I would like to try:
- Use a ray-tracer to build more realistically looking augmented training images.
- Experiment with decreasing the size of the network to make it faster (while retaining the accuracy).
- Train on more data.
Further Reading
In case you haven’t had enough already, I’ve listed a few suggestions for further reading below. As mentioned above, I have not been able to find anyone approaching a similar problem in a similar way, so I cannot provide links to that. The links below are papers that still are somehow relevant either because they tackle a similar problem or somehow use as similar approach.
- Deep Learning Face Representation from Predicting 10,000 Classes by Yi Sun et al.
- CNN Features off-the-shelf: an Astounding Baseline for Recognition by Ali Sharif Razavian et al.
- Signature Verification using a “Siamese” Time Delay Neural Network by Jane Bromley et al.
- Learning a Similarity Metric Discriminatively, with Application to Face Verification by Sumit Chopra et al.
- AEkNN: An AutoEncoder kNN-based classifier with built-in dimensionality reduction by Francisco J. Pulgar et al.
- Semantic Hashing by Geoffrey Hinton and Ruslan Salakhutdino
- Using Very Deep Autoencoders for Content-Based Image Retrieval by Alex Krizhevsky and Georey Hinton
-
Extracting and Composing Robust Features with Denoising Autoencodersby Pascal Vincent et al.
- FaceNet: A Unified Embedding for Face Recognition and Clustering by Florian Schroff et al.
- DeepFace: Closing the Gap to Human-Level Performance in Face Verification by Yaniv Taigman et al.
- Improved Audio Classification Using a Novel Non-Linear Dimensionality Reduction Ensemble Approach by Stéphane Dupont and Thierry Ravet
- Large Margin Aggregation of Local Estimates for Medical Image Classification by Yang Song et al.
Bonus Info
If you got this far, you deserve a little bonus info. As I’ve mentioned a few times by now, more than 36,000 cards have been released over the years. In fact the number is way bigger than that if you include non-English cards. Many cards have been printed in other languages, including German, Italian, Korean and Japanese. The non-English cards have the same artwork as the English versions but all text on the cards has been translated. My system was trained on photos of English cards only and the set of reference images is restricted to the English versions. But, interestingly the system seems to work very well, even on the non-English cards. I don’t have any accuracy numbers yet but still it’s a nice little bonus.


Left: Photo of Chinese card. Right: English card predicted by the system.