






278 reads
96 Stories To Learn About Data Engineering
by Learn RepoJanuary 7th, 2024




Too Long; Didn't Read
Learn everything you need to know about Data Engineering via these 96 free HackerNoon stories.People Mentioned


Company Mentioned




Let's learn about Data Engineering via these 96 free stories. They are ordered by most time reading created on HackerNoon. Visit the /Learn Repo to find the most read stories about any technology.
1. How to Improve Query Speed to Make the Most out of Your Data
In this article, I will talk about how I improved overall data processing efficiency by optimizing the choice and usage of data warehouses.


2. Introduction to a Career in Data Engineering
A valuable asset for anyone looking to break into the Data Engineering field is understanding the different types of data and the Data Pipeline.

3. Meet The Entrepreneur: Alon Lev, CEO, Qwak
Meet The Entrepreneur: Alon Lev, CEO, Qwak


4. Cloud Services Will Take Over the World, says Noonies Nominee and Python Teacher, Veronika
2021 Noonies Nominee General Interview with Veronika. Read for more on cloud services, data engineering, and python.


5. Introduction to Great Expectations, an Open Source Data Science Tool
This is the first completed webinar of our “Great Expectations 101” series. The goal of this webinar is to show you what it takes to deploy and run Great Expectations successfully.


6. Data Engineering Tools for Geospatial Data
Location-based information makes the field of geospatial analytics so popular today. Collecting useful data requires some unique tools covered in this blog.


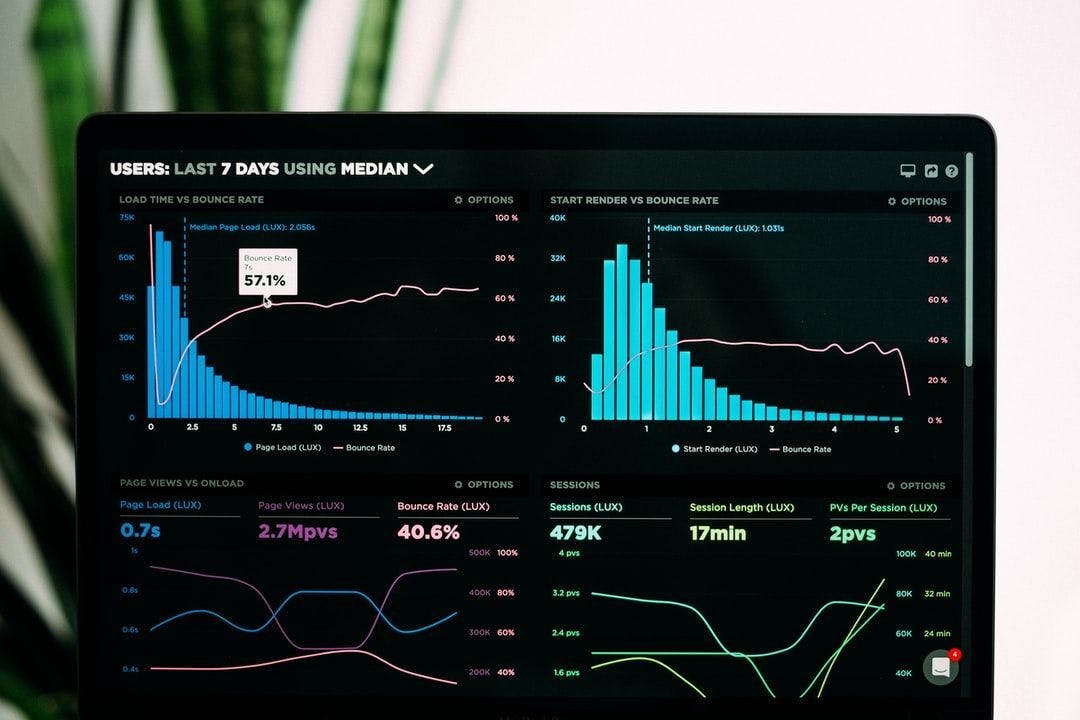
7. Best Types of Data Visualization
Learning about best data visualisation tools may be the first step in utilising data analytics to your advantage and the benefit of your company


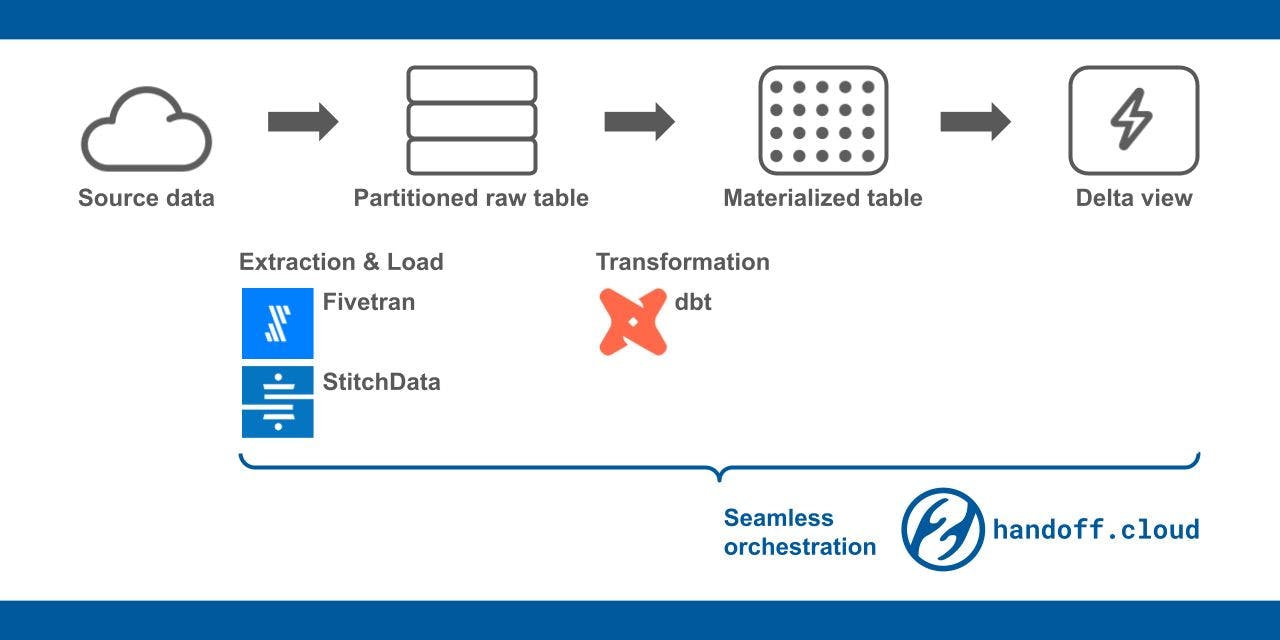
8. Cost Effective Data Warehousing: Delta View and Partitioned Raw Table
The worst nightmare of analytics managers is accidentally blowing up the data warehouse cost. How can we avoid receiving unexpectedly expensive bills?

9. The Growth Marketing Writing Contest by mParticle and HackerNoon
mParticle & HackerNoon are excited to host a Growth Marketing Writing Contest. Here’s your chance to win money from a whopping $12,000 prize pool!


10. What is the Future of the Data Engineer? - 6 Industry Drivers
Is the data engineer still the "worst seat at the table?" Maxime Beauchemin, creator of Apache Airflow and Apache Superset, weighs in.


11. Why Businesses Need Data Governance
Governance is the Gordian Knot to all Your Business Problems.


12. A Guide to Implementing an mParticle Data Plan in an eCommerce App
See mParticle data events and attributes displayed in an eCommerce UI, and experiment with implementing an mParticle data plan yourself.


13. Six Habits to Adopt for Highly Effective Data
Put your organization on the path to consistent data quality with by adopting these six habits of highly effective data.


14. 5 Ways to Become a Leader That Data Engineers Will Love
How to become a better data leader that the data engineers love?

15. Towards Open Options Chains - Part III: Get Started with Airflow
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.


16. Crunching Large Datasets Made Fast and Easy: the Polars Library
Processing large data, e.g. for cleansing, aggregation or filtering is done blazingly fast with the Polars data frame library in python thanks to its design.


17. Certify Your Data Assets to Avoid Treating Your Data Engineers Like Catalogs
Data trust starts and ends with communication. Here’s how best-in-class data teams are certifying tables as approved for use across their organization.


18. Data Observability that Fits Any Data Team’s Structure
Data teams come in all different shapes and sizes. How do you build data observability into your pipeline in a way that suits your team structure? Read on.

19. Serving Structured Data in Alluxio: Example
In the previous article, I described the concept and design of the Structured Data Service in the Alluxio 2.1.0 release. This article will go through an example to demonstrate how it helps SQL and structured data workloads.


20. Solving Noom's Data Analyst Interview Questions
Noom helps you lose weight. We help you get a job at Noom. In today’s article, we’ll show you one of Noom’s hard SQL interview questions.


21. What is a Data Reliability Engineer?
With each day, enterprises increasingly rely on data to make decisions.


22. How To Create a Python Data Engineering Project with a Pipeline Pattern
In this article, we cover how to use pipeline patterns in python data engineering projects. Create a functional pipeline, install fastcore, and other steps.

23. Serving Structured Data in Alluxio: Example
In the previous article, I described the concept and design of the Structured Data Service in the Alluxio 2.1.0 release. This article will go through an example to demonstrate how it helps SQL and structured data workloads.

24. How to Build Machine Learning Algorithms that Actually Work
Applying machine learning models at scale in production can be hard. Here's the four biggest challenges data teams face and how to solve them.

25. Can Your Organization's Data Ever Really Be Self-Service?
Self-serve systems are a big priority for data leaders, but what exactly does it mean? And is it more trouble than it's worth?

26. How We Use dbt (Client) In Our Data Team
Here is not really an article, but more some notes about how we use dbt in our team.


27. An 80% Reduction in Standard Audience Calculation Time
Standard Audiences: A product that extends the functionality of regular Audiences, one of the most flexible, powerful, and heavily leveraged tools on mParticle.


28. Smartype Hubs: Keeping Developers in Sync With Your Data Plan
Implementing tracking code based on an outdated version of your organization's data plan can result in time-consuming debugging, dirty data pipelines, an


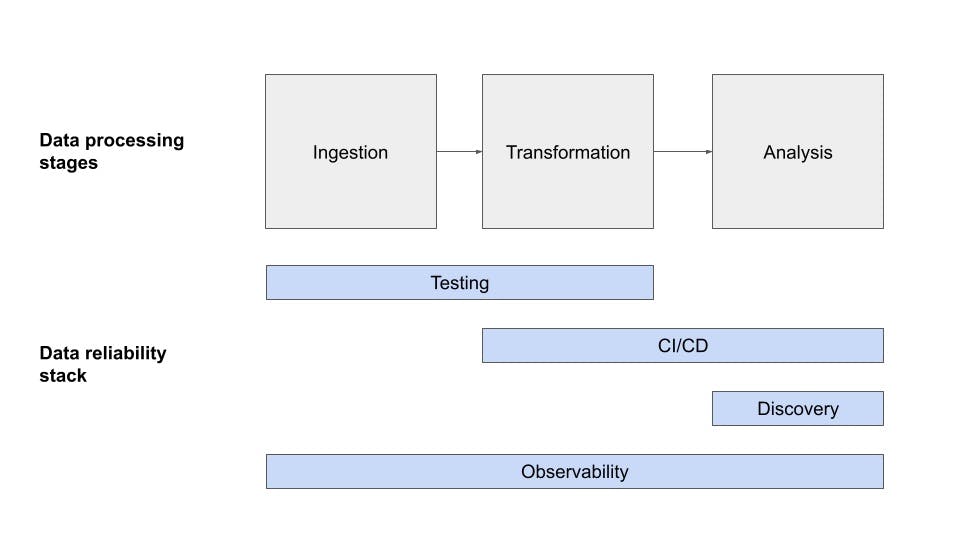
29. 80% of Issues Aren't Caught by Testing Alone: Build Your Data Reliability Stack to Reduce Downtime
After speaking to hundreds of teams, I discovered ~80% of data issues aren’t covered by testing alone. Here are 4 layers to building a data reliability stack.
30. How to Scrape NLP Datasets From Youtube
Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.


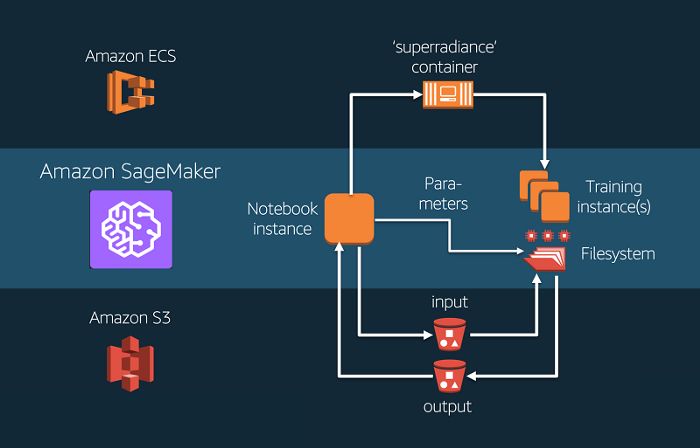
31. Introduction To Amazon SageMaker
Amazon AI/ML Stack

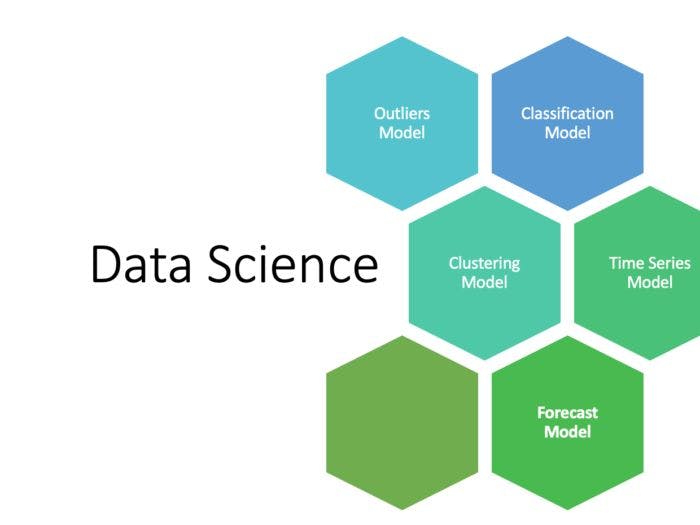
32. A Brief Introduction to 5 Predictive Models in Data Science
Predictive Modeling in Data Science is more like the answer to the question “What is going to happen in the future, based on known past behaviors?”

33. Data Engineering Hack: Using CDPs for Simplified Data Collection
From simplifying data collection to enabling data-driven feature development, Customer Data Platforms (CDPs) have far-reaching value for engineers.

34. Writing Pandas to Make Your Python Code Scale
Write efficient and flexible data-pipelines in Python that generalise to changing requirements.

35. Towards Open Options Chains Part V: Containerizing the Pipeline
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.

36. Apache Airflow: Is It a Good Tool for Data Quality Checks?
Learn the impact of airflow on the data quality checks and why you should look for an alternative solution tool


37. 5 Most Important Tips Every Data Analyst Should Know
The 5 things every data analyst should know and why it is not Python, nor SQL

38. Machine-Learning Neural Spatiotemporal Signal Processing with PyTorch Geometric Temporal
PyTorch Geometric Temporal is a deep learning library for neural spatiotemporal signal processing.


39. How Datadog Revealed Hidden AWS Performance Problems
Migrating from Convox to Nomad and some AWS performance issues we encountered along the way thanks to Datadog

40. Building a Large-Scale Interactive SQL Query Engine with Open Source Software
This is a collaboration between Baolong Mao's team at JD.com and my team at Alluxio. The original article was published on Alluxio's blog. This article describes how JD built an interactive OLAP platform combining two open-source technologies: Presto and Alluxio.


41. How to Build a Directed Acyclic Graph (DAG) - Towards Open Options Chains Part IV
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.

42. Understanding the Differences between Data Science and Data Engineering
A brief description of the difference between Data Science and Data Engineering.


43. Data Teams Need Better KPIs. Here's How.
Here are six important steps for setting goals for data teams.

44. How to Setup Your Organisation's Data Team for Success
Best practices for building a data team at a hypergrowth startup, from hiring your first data engineer to IPO.

45. How DAGs Grow: When People Trust A Data Source, They'll Ask More Of It
This blog post is a refresh of a talk that James and I gave at Strata back in 2017. Why recap a 3-year-old conference talk? Well, the core ideas have aged well, we’ve never actually put them into writing before, and we’ve learned some new things in the meantime. Enjoy!

46. Want to Create Data Circuit Breakers with Airflow? Here's How!
See how to leverage the Airflow ShortCircuitOperator to create data circuit breakers to prevent bad data from reaching your data pipelines.

47. Towards Open Options Chains Part II: Foundational ETL Code
In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.

48. Running Presto Engine in a Hybrid Cloud Architecture
Migrating Presto workloads from a fully on-premise environment to cloud infrastructure has numerous benefits, including alleviating resource contention and reducing costs by paying for computation resources on an on-demand basis. In the case of Presto running on data stored in HDFS, the separation of compute in the cloud and storage on-premises is apparent since Presto’s architecture enables the storage and compute components to operate independently. The critical issue in this hybrid environment of Presto in the cloud retrieving HDFS data from an on-premise environment is the network latency between the two clusters.


49. Getting Information From The Most Granular Demographics Dataset
Find out how to set up and work locally with the most granular demographics dataset that is out there.


50. Why Microservices Suck At Machine Learning...and What You Can Do About It
I've worked on teams building ML-powered product features, everything from personalization to propensity paywalls. Meetings to find and get access to data consumed my time, other days it was consumed building ETLs to get and clean that data. The worst situations were when I had to deal with existing microservice oriented architectures. I wouldn't advocate that we stop using microservices, but if you want to fit in a ML project in an already in-place strict microservice oriented architecture, you're doomed.

51. Using Data Aggregation to Understand Cost of Goods Sold
This case study describes how we built a custom library that combines data housed in disparate sources to acquire the insights we needed.


52. Are NoSQL databases relevant for data engineering?
In this article, we’ll investigate use cases for which data engineers may need to interact with NoSQL database, as well as the pros and cons.


53. The Advantages of a Hybrid Deployment Architecture
See how a hybrid architecture marries the best of the SaaS world and on-prem world for modern data stack software.


54. How We Improved Spark Jobs on HDFS Up To 30 Times
As the third largest e-commerce site in China, Vipshop processes large amounts of data collected daily to generate targeted advertisements for its consumers. In this article, guest author Gang Deng from Vipshop describes how to meet SLAs by improving struggling Spark jobs on HDFS by up to 30x, and optimize hot data access with Alluxio to create a reliable and stable computation pipeline for e-commerce targeted advertising.


55. Why Are We Teaching Pandas Instead of SQL?
How I learned to stop using pandas and love SQL.


56. How To Deploy Metabase on Google Cloud Platform (GCP)?
Metabase is a business intelligence tool for your organisation that plugs in various data-sources so you can explore data and build dashboards. I'll aim to provide a series of articles on provisioning and building this out for your organisation. This article is about getting up and running quickly.

57. Database Tips: 7 Reasons Why Data Lakes Could Solve Your Problems
Data lakes are an essential component in building any future-proof data platform. In this article, we round up 7 reasons why you need a data lake.

58. Event-Driven Change Data Capture: Introduction, Use Cases, and Tools
How to detect, capture, and propagate changes in source databases to target systems in a real-time, event-driven manner with Change Data Capture (CDC).


59. 7 Gotchas(!) Data Engineers Need to Watch Out for in an ML Project
This article covers 7 data engineering gotchas in an ML project. The list is sorted in descending order based on the number of times I've encountered each one.


60. HarperDB is More Than Just a Database: Here's Why
HarperDB is more than just a database, and for certain users or projects, HarperDB is not serving as a database at all. How can this be possible?


61. Introduction to Delight: Spark UI and Spark History Server
Delight is an open-source an cross-platform monitoring dashboard for Apache Spark with memory & CPU metrics complementing the Spark UI and Spark History Server.

62. Scale Your Data Pipelines with Airflow and Kubernetes
It doesn’t matter if you are running background tasks, preprocessing jobs or ML pipelines. Writing tasks is the easy part. The hard part is the orchestration— Managing dependencies among tasks, scheduling workflows and monitor their execution is tedious.


63. Is The Modern Data Warehouse Dead?
Do we need a radical new approach to data warehouse technology? An immutable data warehouse starts with the data consumer SLAs and pipes data in pre-modeled.

64. Efficient Model Training in the Cloud with Kubernetes, TensorFlow, and Alluxio Open Source
This article presents the collaboration of Alibaba, Alluxio, and Nanjing University in tackling the problem of Deep Learning model training in the cloud. Various performance bottlenecks are analyzed with detailed optimizations of each component in the architecture. This content was previously published on Alluxio's Engineering Blog, featuring Alibaba Cloud Container Service Team's case study (White Paper here). Our goal was to reduce the cost and complexity of data access for Deep Learning training in a hybrid environment, which resulted in over 40% reduction in training time and cost.

65. Data Location Awareness: The Benefits of Implementing Tiered Locality
Tiered Locality is a feature led by my colleague Andrew Audibert at Alluxio. This article dives into the details of how tiered locality helps provide optimized performance and lower costs. The original article was published on Alluxio’s engineering blog


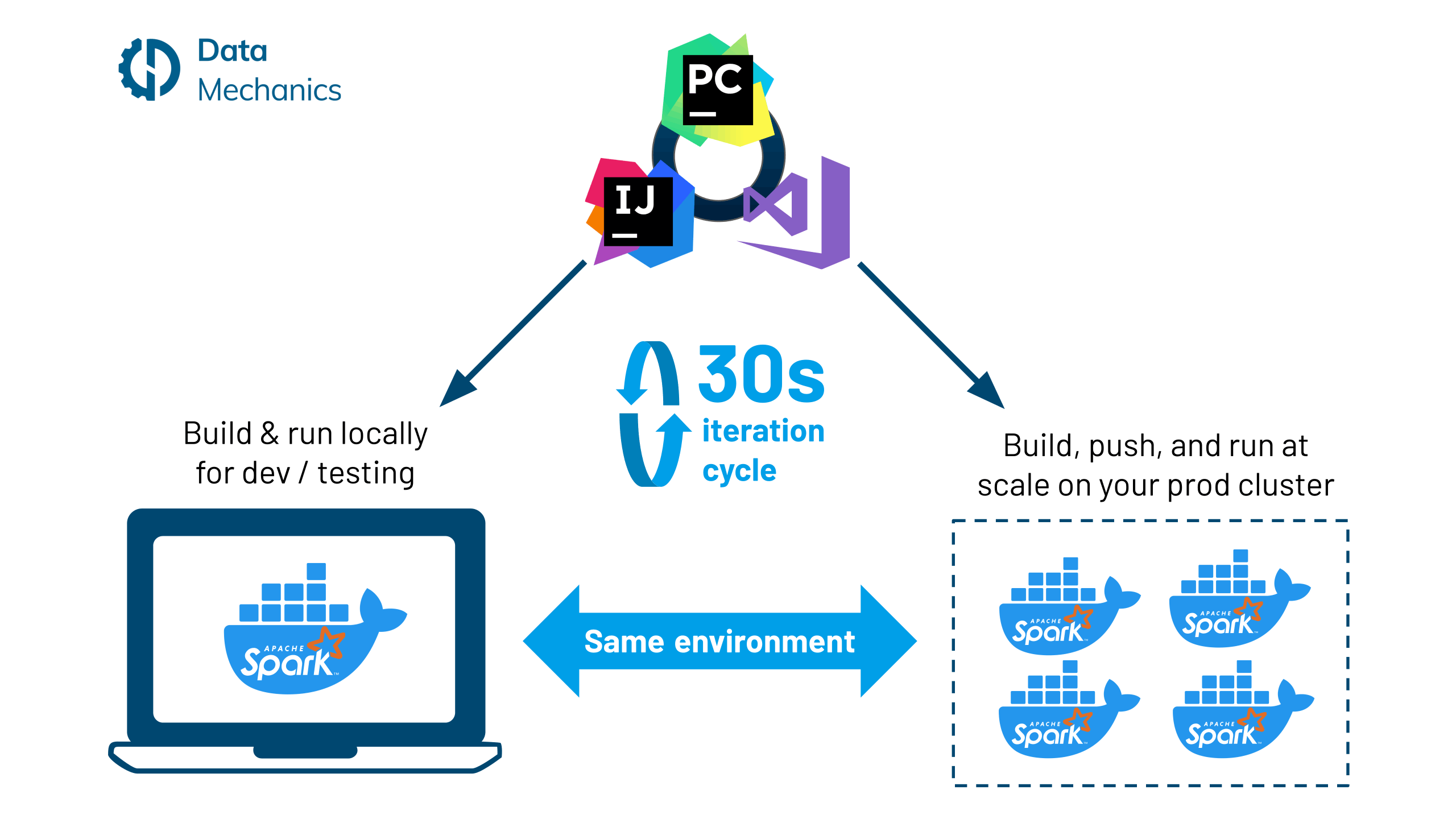
66. Docker Dev Workflow for Apache Spark
The benefits that come with using Docker containers are well known: they provide consistent and isolated environments so that applications can be deployed anywhere - locally, in dev / testing / prod environments, across all cloud providers, and on-premise - in a repeatable way.

67. What Is A Data Mesh — And Is It Right For Me?
Ask anyone in the data industry what’s hot and chances are “data mesh” will rise to the top of the list. But what is a data mesh and is it right for you?


68. 10 Key Skills Every Data Engineer Needs
Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments in AI-based SaaS products.


69. Build A Crypto Price Tracker using Node.js and Cassandra
Since the big bang in the data technology landscape happened a decade and a half ago, giving rise to technologies like Hadoop, which cater to the four ‘V’s. — volume, variety, velocity, and veracity there has been an uptick in the use of databases with specialized capabilities to cater to different types of data and usage patterns. You can now see companies using graph databases, time-series databases, document databases, and others for different customer and internal workloads.


70. Serving Structured Data in Alluxio
This article introduces Structured Data Management (Developer Preview) available in the latest Alluxio 2.1.0 release, a new effort to provide further benefits to SQL and structured data workloads using Alluxio. The original concept was discussed on Alluxio’s engineering blog. This article is part one of the two articles on the Structured Data Management feature my team worked on.


[71. Towards Open Options Chains:
A Data Pipeline Solution - Part I](https://hackernoon.com/towards-open-options-chains-a-data-pipeline-solution-for-options-data-part-i) In "Towards Open Options Chains", Chris Chow presents his solution for collecting options data: a data pipeline with Airflow, PostgreSQL, and Docker.

72. Why Data Science is a Team Sport?
Today, I am going to cover why I consider data science as a team sport?

73. Why Data Quality is Key to Successful ML Ops
In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.


74. 9 Best Data Engineering Courses You Should Take in 2023
In this listicle, you'll find some of the best data engineering courses, and career paths that can help you jumpstart your data engineering journey!


75. 4 Critical Steps To Build A Large Catalog Of Connectors Remarkably Well
The art of building a large catalog of connectors is thinking in onion layers.

76. Everything You Need to Know About Deep Data Observability
What's Deep Data Observability and how it's different from Shallow.


77. Python & Data Engineering: Under the Hood of Join Operators
In this post, I discuss the algorithms of a nested loop, hash join, and merge join in Python.

78. How We Built A Cross-Region Hybrid Cloud Storage Gateway for ML & AI at WeRide
In this blog, guest writer Derek Tan, Executive Director of Infra & Simulation at WeRide, describes how engineers leverage Alluxio as a hybrid cloud data gateway for applications on-premises to access public cloud storage like AWS S3.


79. How To Productionalize ML By Development Of Pipelines Since The Beginning
Writing ML code as pipelines from the get-go reduces technical debt and increases velocity of getting ML in production.


80. Goldman Sachs, Data Lineage, and Harry Potter Spells
Goldman Will Dominate Consumer Banking


81. Performance Benchmark: Apache Spark on DataProc Vs. Google BigQuery


When it comes to Big Data infrastructure on Google Cloud Platform , the most popular choices Data architects need to consider today are Google BigQuery – A serverless, highly scalable and cost-effective cloud data warehouse, Apache Beam based Cloud Dataflow and Dataproc – a fully managed cloud service for running Apache Spark and Apache Hadoop clusters in a simpler, more cost-efficient way.
82. Build vs Buy: What We Learned by Implementing a Data Catalog
Why we chose to finally buy a unified data workspace (Atlan), after spending 1.5 years building our own internal solution with Amundsen and Atlas


83. Save and Search Through Your Slack Channel History on a Free Slack Plan
Sometimes, we might not be able to afford a paid subscription on Slack. Here's a tutorial on how you can save and search through your Slack history for free.


84. The DeltaLog: Fundamentals of Delta Lake [Part 2]
Multi-part series that will take you from beginner to expert in Delta Lake

85. Deep Learning at Alibaba Cloud with Alluxio: How To Run PyTorch on HDFS
This tutorial shows how Alibaba Cloud Container team runs PyTorch on HDFS using Alluxio under Kubernetes environment. The original Chinese article was published on Alibaba Cloud's engineering blog, then translated and published on Alluxio's Engineering Blog


86. Introducing Handoff: Serverless Data Pipeline Orchestration Framework
handoff is a serverless data pipeline orchestration framework simplifies the process of deploying ETL/ELT tasks to AWS Fargate.


87. How Machine Learning is Used in Astronomy
Is Astronomy data science?


88. Influenza Vaccines: The Data Science Behind Them
Influenza Vaccines and Data Science in Biology


89. Data Testing: It's About Both Problem Detection and Quality of Response
Congratulations, you’ve successfully implemented data testing in your pipeline!


90. Top 6 CI/CD Practices for End-to-End Development Pipelines
Maximizing efficiency is about knowing how the data science puzzles fit together and then executing them.


91. Power-up: Machine Learning and Data Engineering (R)evolution for Optimizing Marketing Efforts
This blog covers real-world use cases of businesses embracing machine learning and data engineering revolution to optimize their marketing efforts.


92. An Introduction to Data Connectors: Your First Step to Data Analytics
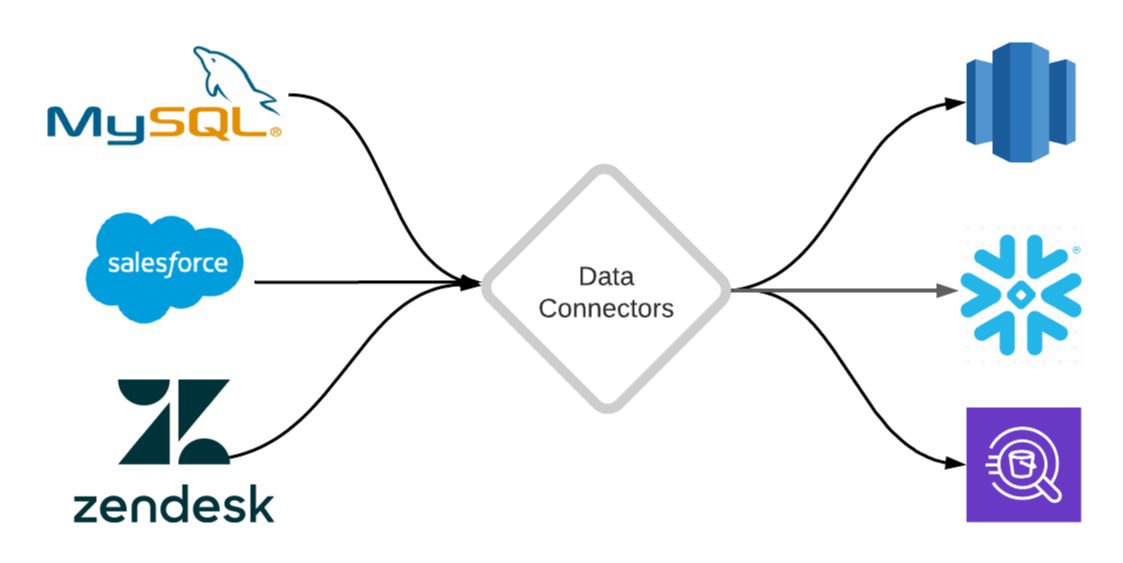
This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse

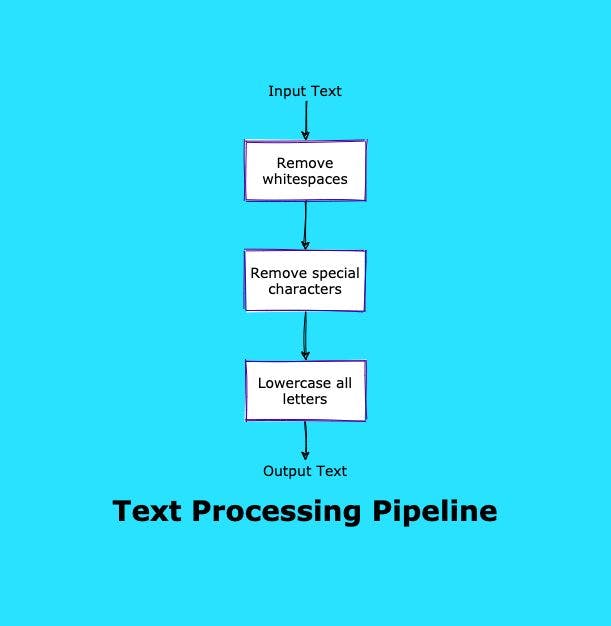
93. How To Build An n8n Workflow To Manage Different Databases and Scheduling Workflows
Learn how to build an n8n workflow that processes text, stores data in two databases, and sends messages to Slack.


94. How to Build a Data Stack from Scratch
Overview of the modern data stack after interview 200+ data leaders. Decision Matrix for Benchmark (DW, ETL, Governance, Visualisation, Documentation, etc)

95. How to Get Started with Data Version Control (DVC)
Data Version Control (DVC) is a data-focused version of Git. In fact, it’s almost exactly like Git in terms of features and workflows associated with it.

96. How to Perform Data Augmentation with Augly Library
Data augmentation is a technique used by practitioners to increase the data by creating modified data from the existing data.


Thank you for checking out the 96 most read stories about Data Engineering on HackerNoon.
Visit the /Learn Repo to find the most read stories about any technology.

L O A D I N G
. . . comments & more!
. . . comments & more!












