












Let's learn about Data Science via these 537 free stories. They are ordered by most time reading created on HackerNoon. Visit the /Learn Repo to find the most read stories about any technology.
The science of using computer programs to sift through thousands of data points and then using computer programs to present that data in a visual format.
1. How To Scrape Google With Python
Ever since Google Web Search API deprecation in 2011, I've been searching for an alternative. I need a way to get links from Google search into my Python script. So I made my own, and here is a quick guide on scraping Google searches with requests and Beautiful Soup.


2. You Don't Need a Fancy PC for Data Science: Use These Cloud Platforms!
You don't need a fancy PC to get started with data science and machine learning. These 5 cloud platforms are easy to set up and free to use.


3. How to Transform Your Data Into a Voice AI Knowledge Assistant
RAIN executives give a full breakdown of the build out and power of AI Voice Assistants.


4. How To use Google Colab with VS Code
Google Colab and VS Code are popular editor tools. Learn how you can use Google Colab with VS Code and take advantage of a full-fledged code editor.


5. 7 Effective Ways to Deal With a Small Dataset
In a real-world setting, you often only have a small dataset to work with. Models trained on a small number of observations tend to overfit and produce inaccurate results. Learn how to avoid overfitting and get accurate predictions even if available data is scarce.


6. Pornhub Growth Hack During Coronavirus Pandemic
The 2019–20 coronavirus pandemic is an ongoing pandemic of coronavirus disease 2019 (COVID-19), caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). The outbreak was first identified in Wuhan, Hubei, China, in December 2019, and was recognized as a pandemic by the World Health Organization (WHO) on 11 March 2020.


7. How to Extract Knowledge from Wikipedia, Data Science Style
As Data Scientists, people tend to think what they do is developing and experimenting with sophisticated and complicated algorithms, and produce state of the art results. This is largely true. It is what a data scientist is mostly proud of and the most innovative and rewarding part. But what people usually don’t see is the sweat they go through to gather, process, and massage the data that leads to the great results. That’s why you can see SQL appears on most of the data scientist position requirements.


8. An Introductory Guide to Variables and Data Types in Go
Hello there! So today we would be learning about Go variables and the different data types associated with Go.

9. What is Image Annotation? – An Intro to 5 Image Annotation Services
Image annotation is one of the most important tasks in computer vision. With numerous applications, computer vision essentially strives to give a machine eyes – the ability to see and interpret the world. At times, machine learning projects seem to unlock futuristic technology we never thought possible. AI-powered applications like augmented reality, automatic speech recognition, and neural machine translation have the potential to change lives and businesses around the world. Likewise, the technologies that computer vision can give us (autonomous vehicles, facial recognition, unmanned drones) are extraordinary.


10. What is One Hot Encoding? Why and When Do You Have to Use it?
One hot encoding is a process by which categorical variables are converted into a form that could be provided to ML algorithms to do a better job in prediction.

11. The Basics Of Natural Language Processing in 10 Minutes
Do you also want to learn NLP as Quick as Possible ? Perhaps you are here because you also want to learn natural language processing as quickly as possible, like me.

12. Random Forest Regression in R: Code and Interpretation
This story looks into random forest regression in R, focusing on understanding the output and variable importance.

13. Automatic Feature Selection in Python: An Essential Guide
Feature Selection in python is the process where you automatically or manually select the features in the dataset that contribute most to your prediction.


14. 6 Biggest Limitations of Artificial Intelligence Technology
While the release of GPT-3 marks a significant milestone in the development of AI, the path forward is still obscure. There are still certain limitations to the technology today. Here are six of the major limitations facing data scientists today.


15. How I built a spreadsheet app with Python to make data science easier
Today I'm open sourcing "Grid studio", a web-based spreadsheet application with full integration of the Python programming language.

16. 10 Machine Learning, Data Science, and Deep Learning Courses for Programmers in 2020
A curated list of courses to learn data science, machine learning, and deep learning fundamentals.

17. Must-Know Theorems for Programmers
Programming is a complex and multifaceted field that encompasses a wide range of mathematical and computational concepts and techniques.


18. An Introduction to the Power of Vector Search for Beginners
An introduction to neural vector search, in comparison to keyword-based search.


19. Top 5 Machine Learning Platforms to Watch in 2022
Machine Learning Operations (MLOps) is a form of DevOps in a growing area. In this article, we'll discuss the top 5 Machine Learning Platforms to watch in 2022.


20. How to Authenticate a User via Face Recognition in Your Web Application
Facial recognition-based authentication to verify a user in a web application is discussed in a beginner-friendly manner using FaceIO APIs.

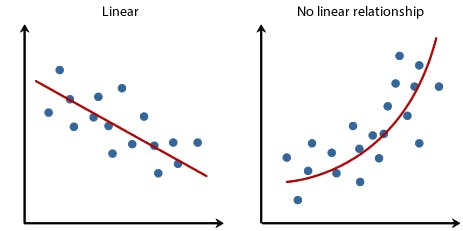
21. Types of Linear Regression
Linear Regression is generally classified into two types:


22. 3 Best Ways To Import External Data Into Google Sheets [Automatically]
Google Sheets is a great tool to use for business intelligence and data analysis. If you want to eliminate manual data imports and save time, then let me will show you how you can automatically connect and import data from external sources into Google Sheets.

23. 160+ Data Science Interview Questions
A typical interview process for a data science position includes multiple rounds. Often, one of such rounds covers theoretical concepts, where the goal is to determine if the candidate knows the fundamentals of machine learning.


24. Benefits of Using IoT and AI Together
The combination of Artificial Intelligence (AI) and the Internet of Things (IoT) has revolutionized the operations of various industries and businesses. IoT coupled with AI is used to make intellectual machines that imitate smart actions and supports in decision making with minimal human intervention. Used together, these two potent technologies enable enterprises to attain true digital transformation.

25. Eliminating Difference Between Business Intelligence analysts, Data Analysts or Data Scientists 🚀
There was a time when the data analyst on the team was the person driving digitalization in an adventurous data quest...and then the engineers took over.

26. Reproducible ML Training Pipelines With dstack And WandB
How to set up reproducible pipelines to track infrastructure, code, data, hyper-parameters, experiment metrics, etc with WandB and dstack integrated together.


27. 4 Valuable Lessons I Learned as a Data Science Student
I never really wanted to learn data science.

28. 3 Best Ways To Import JSON To Google Sheets [Ultimate Guide]
3 ways to pull JSON data into a Google Spreadsheet

29. The Best (and Worst) Punny Jokes Only Data Scientists Will Understand
For the first KDnuggets post on Hacker Noon, we bring you a lighter fare of very nerdy computer humor from the series of self-referential jokes started on Twitter earlier this week. Here are some of our favorites.


If you do understand all of the jokes, then you congratulate yourself on having excellent knowledge of Data Science and Machine Learning! If you have actually laughed at 2 or more jokes, then you have earned MS in Computer Humor! If you just smirked, you probably have a Ph.D. And I have a great joke about AGI, but it will be ready in 10 years.
Enjoy, and if you have more, add them in comments below!
Yann LeCun, @ylecun
30. NLP Tutorial: Topic Modeling in Python with BerTopic
Topic modeling is an unsupervised machine learning technique that can automatically identify different topics present in a document (textual data). Data has become a key asset/tool to run many businesses around the world. With topic modeling, you can collect unstructured datasets, analyzing the documents, and obtain the relevant and desired information that can assist you in making a better decision.


31. Developing Software Quality Metrics as a Data Scientist - 5 Lessons Learned
Software quality metrics are essential tools in ensuring a product provides the best experience to its users. Here are some tips for (not only) data scientists.

32. Technical Data Science Interview Questions: SQL and Coding
A data science interview consists of multiple rounds. One of such rounds involves theoretical questions, which we covered previously in 160+ Data Science Interview Questions.


33. 14 Open Datasets for Text Classification in Machine Learning
Text classification datasets are used to categorize natural language texts according to content. For example, think classifying news articles by topic, or classifying book reviews based on a positive or negative response. Text classification is also helpful for language detection, organizing customer feedback, and fraud detection. Though time consuming when done manually, this process can be automated with machine learning models. The result saves companies time while also providing valuable data insights.

34. Intro to Databases: Using Different Data Models and Representing Databases Visually
As you get into the Databases and Data Science, the first thing that you have to master is the relations between entities in your database. That is important because the data that you use has to be absolutely efficient for its further implementations.


35. Data Science Innovations: 5 Main Obstacles in the Implementation Process and How To Overcome Them
Data science is a rapidly developing sector of study. Its main goal is to translate vast amounts of records into valuable business insights. Implementing data science-based tools into your company can be highly beneficial. AI software is more efficient and accurate than humans have ever been.


36. Unsupervised Data Augmentation
More data we have, better performance we can achieve. However, it is very too luxury to annotate large amount of training data. Therefore, proper data augmentation is useful to boost up your model performance. Authors of Unsupervised Data Augmentation (Xie et al., 2019) proposed Unsupervised Data Augmentation (UDA) assistants us to build a better model by leveraging several data augmentation methods.


37. 10 Best Stock Market Datasets for Machine Learning
For those looking to build predictive models, this article will introduce 10 stock market and cryptocurrency datasets for machine learning.


38. 'Experience is a Double-edged Sword': Kyle Kirwan, CEO of Bigeye
An interview with the founder and CEO of Bigeye, a data observability platform.

39. 9 Best Data Engineering Courses You Should Take in 2023
In this listicle, you'll find some of the best data engineering courses, and career paths that can help you jumpstart your data engineering journey!


40. Data Preprocessing: 6 Necessary Steps for Data Scientists
Hello everyone, I am back with another topic which is Data Preprocessing. This is a part of the data analytics and machine learning process that data scientists spend most of their time on. In this article, I'll dive into the topic, why we use it, and the necessary steps.

41. Text Processing and Sentiment Analysis of Twitter Data
A complete guide to text processing using Twitter data and R.


42. Busting Financial Myths: "The Ignorant Retail Investor"
If you Google "ignorant retail traders," you'll find mentions on the Financial Times, Seeking Alpha, Wired, Berkshire Money Management, The Street, and even The South China Morning Post.


43. Is There a 'GitHub For Data Scientists'?
What if I say that there is a place where you can not only store your Data Science projects but also experiment on them right then and there?


44. Top 10 JavaScript Charting Libraries for Every Data Visualization Need
There're numerous JavaScript charting libraries. To make your life easier, I decided to share my picks. Check out the best JS libraries for creating web charts!


45. A Free Ethical OS Toolkit for Woke AI Enterprises
Are your algorithms transparent those they impact? Is your technology reinforcing or amplifying existing bias?


46. What Books Are We Reading On AI and Machine Learning in 2020?
Whether you are a seasoned professional in this industry or just starting to dip your toes in, there is always more to learn about AI and machine learning.

47. Image Style Transfer And Video Transformation In EbSynth
Using EbSynth and Image Style Transfer machine learning models to create a custom AI painted video/GIF.

48. 6 Best Python-Based Data Science Frameworks
Knowing Python is the most valuable skill to start a data scientist career. Although there are other languages to use for data tasks (R, Java, SQL, MATLAB, TensorFlow, and others), there are some reasons why specialists choose Python. It has some benefits, such as:


49. Top C/C++ Machine Learning Libraries For Data Science
Importance of C++ in Data Science and Big Data

50. How To Plot A Decision Boundary For Machine Learning Algorithms in Python
Classification algorithms learn how to assign class labels to examples (observations or data points), although their decisions can appear opaque.


51. Python for Data Science: How to Scrape Website Data via the Internet's Top 300 APIs
In this post we are going to scrape websites to gather data via the API World's top 300 APIs of year. The major reason of doing web scraping is it saves time and avoid manual data gathering and also allows you to have all the data in a structured form.

52. Top 20 Image Datasets for Machine Learning and Computer Vision
Computer vision enables computers to understand the content of images and videos. The goal in computer vision is to automate tasks that the human visual system can do.

53. How to Get Qualified to Work in Big Data for Decision Intelligence
Decision intelligence, Data Stories, and Data Cloud Services are the three trends that are ranking high in the Data Analytics 2021.


54. Intro to Audio Analysis: Recognizing Sounds Using Machine Learning


55. Data Signals vs. Noise: Misleading Metrics and Misconceptions About Crypto-Asset Analytics
The steady growth in the crypto-asset space has increased the need and popularity of market intelligence/analytics products. However, like any other new asset class, the methodologies and techniques to extract meaningful intelligence about crypto-assets are going to take some time to mature. Fortunately, the crypto market was born in the golden age of data science and machine learning so it has a shot at building the most sophisticated generation of market intelligence products ever seen for an asset class. Paradoxically, it seems that we prefer to remain lazy and come up with half-baked analytics that have the mathematical rigor of a fifth grade class.


56. 11 Best Climate Change Datasets for Data Science Projects
Data is a central piece of the climate change debate. With the climate change datasets on this list, many data scientists have created visualizations and models to measure and track the change in surface temperatures, sea ice levels, and more. Many of these datasets have been made public to allow people to contribute and add valuable insight into the way the climate is changing and its causes.


57. How to Build a Web Scraper With Python [Step-by-Step Guide]
On my self-taught programming journey, my interests lie within machine learning (ML) and artificial intelligence (AI), and the language I’ve chosen to master is Python.


58. What is Natural Language Processing? A Brief Overview
Natural language processing (NLP) is a subfield of artificial intelligence. It is the ability to analyze and process a natural language.


59. NLP Datasets from HuggingFace: How to Access and Train Them
The Datasets library from hugging Face provides a very efficient way to load and process NLP datasets from raw files or in-memory data. These NLP datasets have been shared by different research and practitioner communities across the world.


60. Introduction To Maths Behind Neural Networks
Today, with open source machine learning software libraries such as TensorFlow, Keras or PyTorch we can create neural network, even with a high structural complexity, with just a few lines of code. Having said that, the Math behind neural networks is still a mystery to some of us and having the Math knowledge behind neural networks and deep learning can help us understand what’s happening inside a neural network. It is also helpful in architecture selection, fine-tuning of Deep Learning models, hyperparameters tuning and optimization.


61. Spotify Audio Features Time Series in Additive Spotify Analyzer
There are many articles on analyzing Spotify data and many applications as well. Some are a one-time analysis on individual's music library and some are an app for a specific purpose. This app is different in that it does not do one thing. It is meant to grow and provide a place to add more analysis. This article is about how the audio features time series was created.

62. How GPUs are Beginning to Displace Clusters for Big Data & Data Science
More recently on my data science journey I have been using a low grade consumer GPU (NVIDIA GeForce 1060) to accomplish things that were previously only realistically capable on a cluster - here is why I think this is the direction data science will go in the next 5 years.


63. How to Create Dummy Data in Python
Dummy data is randomly generated data that can be substituted for live data. Whether you are a Developer, Software Engineer, or Data Scientist, sometimes you need dummy data to test what you have built, it can be a web app, mobile app, or machine learning model.

64. How to Perform Emotion detection in Text via Python
In this tutorial, I will guide you on how to detect emotions associated with textual data and how can you apply it in real-world applications.


65. Top 13 Data Visualization Tools for 2023 and Beyond
With the enormity of data, data visualization has become the most sought-after method to depict huge numbers in simpler versions of maps or graphs.


66. Why Are We Teaching Pandas Instead of SQL?
How I learned to stop using pandas and love SQL.


67. Scraping Tweet Replies with Python and Tweepy Twitter API [A Step-by-Step Guide]
A Quick Method To Extract Tweets and Replies For Free

68. Build Your Own Voice Recognition Model with Tensorflow
While I'm usually a JavaScript person, there are plenty of things that Python makes easier to do. Doing voice recognition with machine learning is one of those.


69. An Intro to No-Code Web Scraping
Web scraping has broken the barriers of programming and can now be done in a much simpler and easier manner without using a single line of code.


70. Training an Image Classifier From Scratch in 15 Minutes
Using PyTorch, FastAI and the CIFAR-10 image dataset

71. Top 10 Open Datasets for Linear Regression
On Hacker Noon, I will be sharing some of my best-performing machine learning articles. This listicle on datasets built for regression or linear regression tasks has been upvoted many times on Reddit and reshared dozens of times on various social media platforms. I hope Hacker Noon data scientists find it useful as well!
72. Building A Machine Learning Model With PySpark [A Step-by-Step Guide]
Spark is the name of the engine to realize cluster computing while PySpark is the Python's library to use Spark.

73. 20 Best PyTorch Datasets for Building Deep Learning Models
PyTorch has gained a reputation as a research-focused framework, and these are the Best PyTorch Datasets for Building Deep Learning Models available today.

74. Is GPU Really Necessary for Data Science Work?
A big question for Machine Learning and Deep Learning apps developers is whether or not to use a computer with a GPU, after all, GPUs are still very expensive. To get an idea, see the price of a typical GPU for processing AI in Brazil costs between US $ 1,000.00 and US $ 7,000.00 (or more).


75. 20 Best Machine Learning Resources for Data Scientists
Whether you’re a beginner looking for introductory articles or an intermediate looking for datasets or papers about new AI models, this list of machine learning resources has something for everyone interested in or working in data science. In this article, we will introduce guides, papers, tools and datasets for both computer vision and natural language processing.

76. Machine Learning for ISIC Skin Cancer Classification Challenge
This is part 1 of my ISIC cancer classification series. You can find part 2 here.

77. How to Install the KNIME Analytics Data Science Software
KNIME Analytics is a data science environment written in Java and built on Eclipse. This software allows visual programming for data science applications.

78. Karate Club a Python library for graph representation learning
Karate Club is an unsupervised machine learning extension library for the NetworkX Python package. See the documentation here.


79. How Many Cryptocurrencies Are Simply Following the Market?
In the last few days, we’ve experienced a massive rout in the cryptocurrency market.


80. What is Auditability for AI Systems?
Up until recently, we accepted the “black box” narrative surrounding AI as a necessary evil that could not be extrapolated away from AI as a concept.


81. My Notes on MAE vs MSE Error Metrics 🚀
We will focus on MSE and MAE metrics, which are frequently used model evaluation metrics in regression models.

82. Fintech 2021: How Fintech Companies Use Big Data Effectively?
According to a study, 90% of the whole world’s data was created in the last two years. This sounds quite cool but what does the world do with all that data? How does one analyze it?


83. How Can Machine Learning Predict the Stock Market?
Artificial intelligence is changing the world as we know it. Form self-driving cars to weather predictions. Now it's taking on the stock market. Here's how.


84. Our Data-Driven Approach to Making Sense of the 2020 Presidential Election
In less than five months, the world’s attention will be drawn to the outcome of the US Presidential election.


85. Why Data Quality is Key to Successful ML Ops
In this first post in our 2-part ML Ops series, we are going to look at ML Ops and highlight how and why data quality is key to ML Ops workflows.


86. Basic Understanding of ARIMA/SARIMA vs Auto ARIMA/SARIMA using Covid-19 Data Predictions
Motivation


87. Key Tactics The Pros Use For Feature Extraction From Time Series


88. The Best 50 Sites to Learn About Data Science
Blogs, they’re everywhere. Blogs about travel, blogs about pets, blogs about blogs. And data science is no exception. Data science blogs are a dime a dozen and with so many, where do you start when you need to find the most valuable information for your needs?

89. Variational Autoencoders (VAE): How AI Learns Whether Your Eyes Are Open Or Closed
Classify open/closed eyes using Variational Autoencoders (VAE).

90. "We Know About AI's Ability To Remember, But Forget About Its Ability To Forget." - Valeria Sadovykh
As our world approaches the time where artificial intelligence becomes as widespread as electricity, we sat down with Valeria Sadovykh, a leading expert in the decision making and decision intelligence aspects of AI. Valeria holds a Ph.D. from the University of Auckland Business School and has over 10 years of experience focusing her efforts on emerging technologies with PwC in New Zealand, Singapore, and the US.


91. Last Week in AI
Every week, my team at Invector Labs publishes a newsletter to track the most recent developments in AI research and technology. You can find this week’s issue below. You can sign up for it using this link. Please do so, our guys worked really hard on this.


92. COVID-19: We Need More Than Data, We Need Insights!
TL;DR We are managing the pandemic situation only with part of the data and not necessarily representative of reality. We must take a census of the number of positive and negative cases within a population. The officially reported positive cases contain a bias: they are cases that already manifest the disease in a more or less serious way. In the long term, the strategy of aggressive testing (South Korea model) is the only viable and sustainable to manage coexistence between the virus and the human beings until a vaccine will be available.

93. What Apple And Spotify Know About Me
Unsurprisingly, the data that our apps have collected about us is both impressive and concerning, though it can be very interesting to review and explore it.


94. How Data Selection Impacts Model Performance: An AMA with SiaSearch
SiaSearch is a Berlin-based AI startup on a mission to accelerate computer vision application development.


95. Using Monte Carlo to Explain Why You Don't Win Daily Fantasy Baseball Games
Use Monte Carlo simulation to understand the risk in fantasy baseball. Learn why optimizing a lineup is a tall order.

96. Data Science Teams are Doing it Wrong: Putting Technology Ahead of People
Data Science and ML have become competitive differentiator for organizations across industries. But a large number of ML models fail to go into production. Why?


97. Python Libraries For Data Science
Top Data science libraries introduction of The Python programming language is assisting the developers in creating standalone PC games, mobiles, and other similar enterprise applications. Python has in excess of 1, 37,000 libraries which help in many ways. In this data-centric world, most consumers demand relevant information during their buying process. The companies also need data scientists for achieving deep insights by processing the big data.


98. 7 Effective Ways to Improve Your Content Marketing with AI Tools
Artificial Intelligence (AI) has numerous business use cases and can be applied to customer service, sales, lead generation, and marketing.


99. Reinforcement Learning: A Brief Introduction to Rules and Applications
The brain of a human child is spectacularly amazing. Even in any previously unknown situation, the brain makes a decision based on its primal knowledge. Depending on the outcome, it learns and remembers the most optimal choices to be taken in that particular scenario. On a high level, this process of learning can be understood as a ’trial and error’ process, where the brain tries to maximise the occurrence of positive outcomes.


100. How IBM's Stance on Face Recognition Will Affect the AI Industry
In a letter to congress sent on June 8th, IBM’s CEO Arvind Krishna made a bold statement regarding the company’s policy toward facial recognition. “IBM no longer offers general purpose IBM facial recognition or analysis software,” says Krishna.

101. Kannada-MNIST:A new handwritten digits dataset in ML town
TLDR:


102. 9 Free AI Tools Everyone Needs to Try
Unlock the power of AI with these 9 free tools! Boost productivity, improve decision-making, & enhance your personal life.


103. 20 Data Science Podcasts You Don’t Want to Miss
Podcasts have unequivocally become one of the most dominant forms of media consumption in recent years.


104. 15 Must-read Machine Learning Articles for Data Scientists
As always, the fields of deep learning and natural language processing are as busy as ever. Despite many industries being hindered by the quarantine restrictions in many countries, the machine learning industry continues to move forward.

105. 10 Computer Vision Startups on Product Hunt with the Most Upvotes
From self-driving cars and facial recognition to AI surveillance and GANs, computer vision tech has been the poster child of the AI industry in recent years. With such a collaborative global data science community, the advancements have come both from research teams, big tech, and computer vision startups alike.


106. Quantifying Variability: Variance, Standard Deviation, and Coefficient of Variation
There are many ways to quantify variability, however, here we will focus on the most common ones: variance, standard deviation, and coefficient of variation. In the field of statistics, we typically use different formulas when working with population data and sample data.

107. How I Created a Simpsons Dataset for Instance Segmentation
This post is about creating your own custom dataset for Image Segmentation/Object Detection. It provides an end-to-end perspective on what goes on in a real-world image detection/segmentation project.

108. 5 Best Data Curation Tools for Computer Vision in 2021
In this article, we’ll dive into the importance of data curation for computer vision, as well as review the top data curation tools on the market.


109. Henry Kissinger vs. Artificial Intelligence
Henry Kissinger about AI: ‘You work on the applications, I work on the implications.’


110. RANSAC, OLS, PCA: 3 Ways to Draw a Straight Line Across a Set of Points
How I approached solving an interview task for autonomous driving from 3 different perspectives: RANSAC, PCA, and Ordinary Least Squares (OLS).


111. Exposing Mediocre Teachers at My School using Data - Here's My Failed Attempt
A programmer’s story

112. Gender Prediction Using Mobile App Data
Сreate a model for the gender prediction based on the list of installed applications on a mobile device.

113. Galactica is an AI Model Trained on 120 Billion Parameters
On November 15th, MetaAI and Papers with Code announced the release of Galactica, a game-changer, open-source large language model trained on scientific knowledge with 120 billion parameters.

114. Building Sustainable AI/ML Solutions in the Cloud with Federated Learning
Compared to centralized training and cooling mechanisms adopted at data centers, how can Federated Learning help us combat detrimental environmental impacts?

115. Percentile Approximation Vs. Averages
Get a primer on percentile approximations and why they're useful for time-series data analysis.

116. Asking the Right Questions About Crypto Assets
One of my mentors in artificial intelligence( AI) always says that with modern machine learning technologies you can find almost any answer but the hard thing is to ask the right questions. That principle certainly applies to crypto-assets. As a new financial asset class, crypto-tokens are, more often than not, evaluated using traditional metrics based on price and volume but we can do so much more. In a data-rich universe where blockchains and exchange data generates billions of data points, we can certainly find all sorts of fascinating patterns and factors that explain behaviors in crypto-assets. The hard thing is to know what to look for.


117. 5 Big Data Problems and How to Solve Them
“Big Data has arrived, but big insights have not.” ―Tim Harford, an English columnist and economist

118. 5 Essential Product Classification Papers for Data Scientists
Product categorization/product classification is the organization of products into their respective departments or categories. As well, a large part of the process is the design of the product taxonomy as a whole.

119. 5 Problems That Artificial Intelligence Cannot Yet Solve
Humanity has recently begun to rely more and more on the help of AI. But can we really rely on such technology today?


120. Introducing Our Low Code Machine Learning Platform
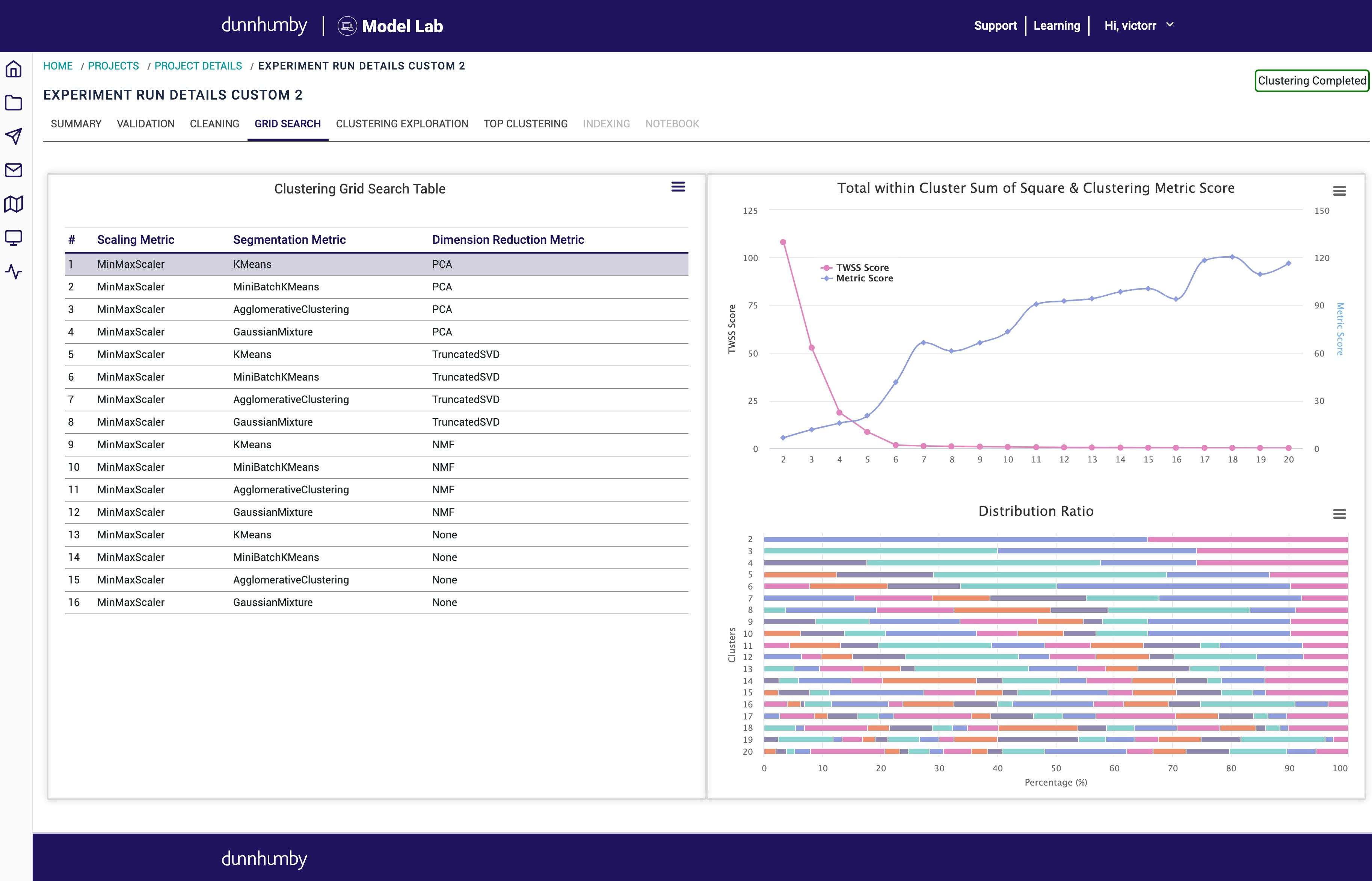
We are very excited to release the free tier of dunnhumby Model Lab as part of our partnership with Microsoft. dunnhumby Model Lab is an application that provides automated pipelines for deploying machine learning algorithms and has been used to build millions of models on behalf of our clients.

121. Granger Causality: Principle of Cause and Effect Explained
... in a world full of data, we can understand the impact with clever methods. Meet Granger causality.

122. Machine Learning Explained in 5 Minutes
Google uses it to provide millions of search results every hour. It helps Facebook guess your next love interest. Even Elon Musk’s Tesla uses it to make self-dr

123. Tips For Using Service Mesh Networks To Leave Your Competition In The Dust
Background and Origin of Service Mesh Network - Istio

124. How To Be A Fantastic Data Scientist: An Expert Shares His Secrets
In the latest episode of our podcast, Machine Learning that Works, I had a great pleasure to talk to Gabriel Preda, a Lead Data Scientist at Endava and a Kaggle Grandmaster.


125. How is Web Crawling Used in Data Science
No-Code tools for collecting data for your Data Science project


126. SpeechPainter: Text-Conditioned Speech Inpainting
We’ve seen image inpainting, which aims to remove an undesirable object from a picture. The machine learning-based techniques do not simply remove the objects, but they also understand the picture and fill the missing parts of the image with what the background should look like. The recent advancements are incredible, just like the results, and this inpainting task can be quite useful for many applications like advertisements or improving your future Instagram post. We also covered an even more challenging task: video inpainting, where the same process is applied to videos to remove objects or people.

127. A Brief Introduction to 5 Predictive Models in Data Science
Predictive Modeling in Data Science is more like the answer to the question “What is going to happen in the future, based on known past behaviors?”

128. Anomaly Detection from Fetal ECG — A Case Study of IOT Anomaly Detection using GAN
In this blog, we discuss about the role of Variation Auto Encoder in detecting anomalies from fetal ECG signals.


129. The Ultimate Toolbox Of ML Startups
Setting up a good tool stack for your Machine Learning team is important to work efficiently and be able to focus on delivering results. If you work at a startup you know that setting up an environment that can grow with your team, needs of the users and rapidly evolving ML landscape is especially important.

130. Demand Forecasting For Retail: A Deep Dive
I know for sure that human behavior could be predicted with data science and machine learning. People lie—data does not. Taking a look at human behavior from a sales data analysis perspective, we can get more valuable insights than from social surveys.


131. What is Data-Centric AI?
What makes GPT-3 and Dalle powerful is exactly the same thing: Data.


132. The Hitchhikers's Guide to PyTorch for Data Scientists
PyTorch has sort of became one of the de facto standard for creating Neural Networks now, and I love its interface. Yet, it is somehow a little difficult for beginners to get a hold of.

133. 17 Open Crime Datasets for Data Science and Machine Learning Projects
For those looking to analyze crime rates or trends over a specific area or time period, we have compiled a list of the 16 best crime datasets made available for public use.


134. A Roadmap For Becoming a Data Scientist
So you want to become a data scientist? You have heard so much about data science and want to know what all the hype is about? Well, you have come to the perfect place. The field of data science has evolved significantly in the past decade. Today there are multiple ways to jump into the field and become a data scientist. Not all of them need you to have a fancy degree either. So let’s get started!


135. Explain Complex Concepts With Minimalistic Drawings With Okso.app
Minimalistic Data Structure Sketches


136. We're collecting AI problem statements to crowdsource solutions to data scientists
As technology penetrates every facet of life, and continues to grow exponentially, the solution potential becomes enormous. At the same time, we're in a world where billions live in poverty, and millions are on the brink of famine. In order to support an ever-growing populace, we need to leave no stone un-turned in the search for solutions. AI provides many potential solutions to humanity's greatest challenges."AI" is a vague, even confusing term. If you hear the phrase "artificial intelligence," you might wonder why there aren't sentient robots walking around, or why everyone isn't in self-driving cars already. The reality is that "AI" is just a marketing term for a set of computational statistical tools, or more simply, algorithms.However, as versatile as mathematics is, so is AI. AI is limited by (primarily) a couple things: data and computational power. Both the data and the compute power we have available are growing exponentially, so AI is becoming more and more powerful.With this increase in data and computational ability, AI is now being used in a wide variety of applications.For example, bitgrit (disclaimer: I'm CEO), collects meaningful AI problem statements to crowd-source solutions to data scientists. Some problem statements include saving animals’ lives, increasing agricultural yield, and speeding up healthcare claims processing.Michael Suttles, CEO at Save All The Pets, explains how data and AI can be used to save shelter animals:


137. Introducing CatalyzeX: A Browser Extension for Machine Learning
Andrew Ng likes it, you probably will too!

138. On the difficulty of creating a data science code of ethics
undefined

139. How to Create a Simple Web Dashboard for Efficient Data Analytics
Dashboard with different visualizations allows you to compare data and show changes and tendencies. In this tutorial I wil explain why and how to build one.

140. The Best Slack Groups for Data Scientists to Join
The online data science community is supportive and collaborative. One of the ways you can join the community is to find machine learning and AI Slack groups.
141. 8 Companies Using Machine Learning in Cool Ways
When asked what advice he'd give to world leaders, Elon Musk replied, "Implement a protocol to control the development of Artificial Intelligence."


142. A Quick Introduction to Machine Learning with Dagster
This article is a quick introduction to Dagster using a small ML project. It is beginner friendly but might also suit more advanced programmers if they dont know Dagster.

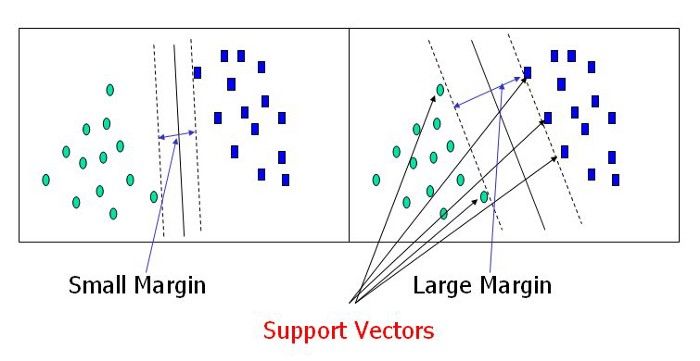
143. Python Library vs. Implementation From Scratch: 7 Things to Consider
The question of from-scratch implementation vs Python library comes up once in a while, no matter the goal of your project.

144. MIDAS: A State-of-the-Art Model for Anomaly Detection in Graphs
In machine learning, hot topics such as autonomous vehicles, GANs, and face recognition often take up most of the media spotlight. However, another equally important issue that data scientists are working to solve is anomaly detection. From network security to financial fraud, anomaly detection helps protect businesses, individuals, and online communities. To help improve anomaly detection, researchers have developed a new approach called MIDAS.
145. MongoDB: Exploring Data Visualization Tools and Techniques
Looking for MongoDB data visualization tool? There are plenty of options but firstly its better to explore what kinds of solutions there are on the market.

146. COVID-19: Perceived Spread vs. True Spread in China, Italy and the US
Here at TimeNet, we’re building a large time series database with the primary aim of benefitting society through access to data. In this post we’ll study different time series representing both the true, and the perceived spread of the coronavirus (COVID-19) pandemic. Daily COVID-19 numbers are currently available on TimeNet.cloud for many countries. We’re expanding these datasets with further variables measuring how we (people) perceive the significance of the pandemic. We use stock market movements and internet search trends to quantify the virus’s perceived spread.

147. How I mastered Python in Lockdown without spending a penny
I always wanted to learn programming. Writing codes, making algorithms always excited me. Being a mechanical engineer, I was never taught these subjects in depth.


148. How to Visualize Bias and Variance
In the process of building a Machine Learning model, there is a trade-off between bias and variance.


149. An Internal Email to Tim Cook and the State of Business Intelligence
We get a glimpse into the inner workings of a valuable company and it turns out it's not all sunshine and rainbows.

150. 9 Free Data Science Courses & Guides For Beginners
We human beings are depending so much on digital and smart devices. And all these devices are creating data at a very fast rate. According to an article on Forbes more than 90% of the world data has been created in past 2 to 3 years.


151. How this Web3 Project is Unlocking a Trillion-Dollar Data Economy with Data NFTs
Learn why data could become the most promising NFT utility that sets the foundation for a valuable trend: Data Finance (DataFi).


152. Hacking Your Marketing Campaigns With Data Science
There is a ton of data points generated from each of your business activities today. A simple email blast to a few thousand recipients generates data pertaining to the open rates, click-through rates and conversion. These data points can further be distilled to infer specific information about the audience demographics that find your message appealing, the subject lines that trigger the user to open your emails, the CTAs that work, and so on.


153. How To Build and Deploy an NLP Model with FastAPI: Part 1
Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.


154. 9 Best Machine Learning, AI, and Data Science Internships in 2022
Here are the Top 9 ML, AI, and Data Science Internships to consider for 2022 if you want to get into any of these very lucrative fields in computer science.

155. How To Create a Python Data Engineering Project with a Pipeline Pattern
In this article, we cover how to use pipeline patterns in python data engineering projects. Create a functional pipeline, install fastcore, and other steps.

156. How to Use Approximate Leave-one-out Cross-validation to Build Better Models
How to use Approximate leave-one-out cross-validation for hyperparameter optimization and outlier detection for logistic regression and ridge regression

157. 3 New Startups That Are Innovating DeFi Data Analysis Technology
Data analysis as a whole is one of the most important industries. Now that DeFi is a full-fledged industry, there is a growing need for valuable data analytics.


158. 5 Top Tech Careers to Consider Studying Towards in 2021
Gain entry into IT with knowledge of data science, engineering, cloud computing, cybersecurity, or devops.


159. Leveraging Data Science in eCommerce: 7 Projects to Try
As an online retailer, how can you improve your business? Of course through providing a better customer experience. An e-commerce company needs to have a well understanding of the following factors:

160. The damaging effects of unplanned work
For practically anyone, unplanned work kills several hours of planned productivity. For creative workers, such as those who write software, it kills days. When the only definition of “done” is “the customer said they were satisfied with the analysis”, you know the scope of your project is going to forever creep until the customer decides to pay attention to something else. When working on something creative like writing code, you experience different levels of productivity. The most productive levels are what some people refer to as “being in the zone”


161. A Step-by-Step Guide to Failing a Data Science Project
As posited by Lev Tolstoy in his seminal work, Anna Karenina: “Happy families are all alike; every unhappy family is unhappy in its own way.” Likewise, all successful data science projects go through a very similar building process, while there are tons of different ways to fail a data science project. However, I’ve decided to prepare a detailed guide aimed at data scientists who want to make sure that their project will be a 100% disaster.

162. How To Predict Election Results using Twitter
Elections play crucial role in all democracies and social media is an important aspect in this process. Presently, political parties increasingly rely on social media platforms like Twitter and Facebook for political communication.The use of social media in political marketing campaigns has grown dramatically over the past few years. It is also expected to become even more critical to future political campaigns, as it creates two-way communication and engagement that stimulates and fosters candidates relationships with their supporters.


163. Covid-19: Analysing The Spread Across Populations
A large portion of mild and asymptomatic cases may go unreported. The data will never be perfect, the true cases are likely much larger as the testing frequency and effectiveness vary in different regions.

164. 5 Types of Machine Learning Algorithms You Should Know
Machine learning has become a diverse business tool to enhance the various elements of business operations. Also, it has a significant influence on the performance of the business. Machine learning algorithms are used widely to maintain competition with different industries. However, there is a different type of algorithms for goals and data sets. The selection of an algorithm depends on user role and the purpose. If you are using Linear regression, then you can quickly implement or train rather than other machine learning algorithms. But the drawback of this algorithm is that it is not applicable for complex predictions. So you should know about the different types of machine learning algorithms for getting better results.


165. How to Think Like a Data Scientist or Data Analyst
Data science is a new and maturing field, with a variety of job functions emerging, from data engineering and data analysis to machine and deep learning. A data scientist must combine scientific, creative and investigative thinking to extract meaning from a range of datasets, and to address the underlying challenge faced by the client.

166. Use plaidML to do Machine Learning on macOS with an AMD GPU
Want to train machine learning models on your Mac’s integrated AMD GPU or an external graphics card? Look no further than PlaidML.

167. Every Way Natural Language is Better Than SQL
Since the dawn of time, humans have communicated through gestures, drawings, smoke, or speech. Along the way, Structured Query Language (SQL) made its way into human life so we could speak to databases. However, it’s time to revert back to our natural language and rethink how we talk to our data.


168. Can Graph Neural Networks Solve Real-World Problems?
In this article, we will learn about GNNs and its structure as well as its applications


169. Machine Learning Magic: How to Speed Up Offline Inference for Large Datasets
Running inference at scale is challenging. See how we speed up the I/O performance for large-scale ML/DL offline inference jobs.


170. Top 40+ Data Science Product Interview Questions
Find the top 40+ product interview questions you must prepare for your next data science interview.

171. 6 Biggest Differences Between Airbyte And Singer
We’ve been asked if Airbyte was being built on top of Singer. Even though we loved the initial mission they had, that won’t be the case. Aibyte's data protocol will be compatible with Singer’s, so that you can easily integrate and use Singer’s taps, but our protocol will differ in many ways from theirs.


172. Dear Aspiring Data Scientists: Skip the Certificates, Do This Instead
If you've been on LinkedIn anytime in the past several months, you've probably come across the infamous "certification post."


173. How I Designed My Own Machine Learning and Artificial Intelligence Degree
After noticing my programming courses in college were outdated, I began this year by dropping out of college to teach myself machine learning and artificial intelligence using online resources. With no experience in tech, no previous degrees, here is the degree I designed in Machine Learning and Artificial Intelligence from beginning to end to get me to my goal — to become a well-rounded machine learning and AI engineer.


174. Mean Reversion Trading Systems and Cryptocurrency Trading [A Deep Dive]
Prices move in a wave like fashion, moving back and forth following a broader trend. While doing so, it often revolves around a mean. It might move across or bounce off the mean. Mean reversion systems are designed to exploit this tendency.

175. Top 9 Free Beginner Tutorials for Machine Learning (ML)
This post includes a round-up of some of the best free beginner tutorials for Machine Learning.

176. 10 Best Image Classification Datasets for ML Projects
To help you build object recognition models, scene recognition models, and more, we’ve compiled a list of the best image classification datasets. These datasets vary in scope and magnitude and can suit a variety of use cases. Furthermore, the datasets have been divided into the following categories: medical imaging, agriculture & scene recognition, and others.

177. 3 Types of Anomalies in Anomaly Detection
An Introduction to Anomaly Detection and Its Importance in Machine Learning


178. No-Code is Eating the World
Recently, Amazon released a new tool, called Honeycode, which lets customers quickly build mobile and web applications — with no coding required. This came a few months after Google’s acquisition of the no-code mobile-app-building platform, AppSheet. While these moves surprised many, they’re in line with a larger trend I’ve observed, one that’s growing strong in all sectors, even amidst economic turmoil.

179. What is an RNN (Recurrent Neural Network) in Deep Learning?
RNN is one of the popular neural networks that is commonly used to solve natural language processing tasks.


180. An Old Statistical Trick Might Help Better Explain the Apparent Correlation Between Bitcoin and Gold
The relationship between Bitcoin and Gold is one of the dynamics that seems to constantly capture the minds of financial analysts. Recently, there have been a series of new articles claiming an increasing “correlation” between Bitcoin and Gold and the phenomenon seems to be constantly debated in financial media outlets like CNBC or Bloomberg.


181. How I Built an Interactive Dashboard Web App to Visualize Boxing Data
I am a huge fan of combat sports, with boxing in particular being my favourite. As much as it may appear as a purely physical sport where your sole objective is to either outbox or knock your opponent out, it is far more strategic that one would expect and incorporates an element psychology. Like a chess game, each punch thrown has to be calculated, recklessly overextending yourself might leave you more vulnerable to a counter punch, while being overly passive and defensive might swing the momentum in your opponent’s favour and not get you enough points to win the fight. If you let self-doubt sink in or are intimidated by your opponent you have already lost the battle. On top of all this, you need to remain respectful of the sport and the life threatening dangers it presents. In the words of of Sugar Ray Leonard, 'you don't play boxing'.


182. 8 Best AI Conferences to Attend in 2022
Here’s the full list of top AI conferences to attend in 2022, from the most technical to business-focused to academic


183. Train a NER Transformer Model with Just a Few Lines of Code via spaCy 3
Transformer models have become by far the state of the art in NLP technology, with applications ranging from NER, Text Classification, and Question Answering


184. A Data Scientist's Guide to Semi-Supervised Learning
Semi-supervised learning is the type of machine learning that is not commonly talked about by data science and machine learning practitioners but still has a very important role to play.

185. Advantages and Disadvantages of Big Data
Big data may seem like any other buzzword in business, but it’s important to understand how big data benefits a company and how it’s limited.

186. Linear Regression and its Mathematical implementation
What is Linear Regression ?

187. No-Code Machine Learning inside Google Sheets
Introduction


188. Pynecone: Web Apps in Pure Python
Pynecone is an open-source framework to build web apps in pure Python and deploy with a single command.

189. Blockchain Technology Improves Data Authentication and Transparency in Healthcare
Blockchain is the secret to trusting the data as it moves into our healthcare ecosystem.

190. Data Set and Data Augmentation for Face Detection and Recognition
When it comes to building an Artificially Intelligent (AI) application, your approach must be data first, not application first.


191. Data Lakehouses: The New Data Storage Model
Data lakehouses are quickly replacing old storage options like data lakes and warehouses. Read on for the history and benefits of data lakehouses.

192. Say Goodbye to SEO - ChatGPT Steals the Show With Smarter Search
Search Engine Optimization (SEO) has been the backbone of an online search for over two decades now. But as Artificial Intelligence (AI) technology moves quickl


193. How to Scrape NLP Datasets From Youtube
Too lazy to scrape nlp data yourself? In this post, I’ll show you a quick way to scrape NLP datasets using Youtube and Python.


194. 5 Best Sentiment Analysis Companies and Tools for Machine Learning
Looking for sentiment analysis companies or sentiment annotation tools? If so, you’ve come to the right place. This guide will briefly explain what sentiment analysis is, and introduce companies that provide sentiment annotation tools and services.


195. How to Build an Image Search Engine to Find Similar Images
After reading this article, you will be able to create a search engine for similar images for your objective from scratch


196. 16 SQL Techniques Every Beginner Needs to Know
This blog post explains the most intricate data warehouse SQL techniques in detail.


197. Introducing ML News
I know.


198. 10 Best Hugging Face Datasets for Building NLP Models
Hugging Face offers solutions and tools for developers and researchers. This article looks at the Best Hugging Face Datasets for Building NLP Models.


199. Why Jupyter Notebooks are the Future of Data Science
How Jupyter Notebooks played an important role in the incredible rise in popularity of Data Science and why they are its future.


200. Software Development Tricks Coding for Beginners and More
This week on HackerNoon's Stories of the Week, we looked at three articles that covered the world of software development from employment to security.

201. Deepmind May Have Just Created the World's First General AI
Gato from DeepMind was just published! It is a single transformer that can play Atari games, caption images, chat with people, control a real robotic arm, and more! Indeed, it is trained once and uses the same weights to achieve all those tasks. And as per Deepmind, this is not only a transformer but also an agent. This is what happens when you mix Transformers with progress on multi-task reinforcement learning agents.


202. How Data Scientists Can Become More Marketable
This headline may seem a bit odd to you. After all, if you’re a data scientist in 2019, you’re already marketable. Since data science has a huge impact on today’s businesses, the demand for DS experts is growing. At the moment I’m writing this, there are 144,527 data science jobs on LinkedIn alone.

203. 5 Use Cases of AI to Show How It Is Transforming the Industry
Although the internet made a lot of things easier for the insurance companies, there were still many pain points left to be addressed.

204. How to Choose the Right Database for your Requirements
Imagine — You’re in a system design interview and need to pick a database to store, let’s say, order-related data in an e-commerce system. Your data is structured and needs to be consistent, but your query pattern doesn’t match with a standard relational DB’s. You need your transactions to be isolated, and atomic and all things ACID… But OMG it needs to scale infinitely like Cassandra!! So how would you decide what storage solution to choose? Well, let’s see!

205. How to Build a Multi-label NLP Classifier from Scratch
Attacking Toxic Comments Kaggle Competition Using Fast.ai


206. How to detect plagiarism in text using Python
Intro


207. Multicollinearity and Its Importance in Machine Learning
Multicollinearity refers to the high correlation between two or more explanatory variables, i.e. predictors. It can be an issue in machine learning too.

208. Time Series Forecasting with TensorFlow.js
Pull stock prices from online API and perform predictions using Recurrent Neural Network & Long Short Term Memory (LSTM) with TensorFlow.js framework


209. 3 Real SQL Questions Asked During Technical Interviews
I love to engage with my readers and learn about what their concerns are when it comes to the technical interview. In this article, I’ll go through a question from a reader and 3real SQL questions that were asked during technical screenings from real companies.

210. Graphs in the 2020s: Databases, Platforms and The Evolution of Knowledge
Graphs, and knowledge graphs, are key concepts and technologies for the 2020s. What will they look like, and what will they enable going forward?


211. How to Do Speech Recognition in Python
In my free time, I am attempting to build my own smart home devices. One feature they will need is speech recognition. While I am not certain yet as to how exactly I want to implement that feature, I thought it would be interesting to dive in and explore different options. The first I wanted to try was the SpeechRecognition library.

212. DecentraMind for Web 3.0 or Against It? — Interview with Mikhail Danieli
DecentraMind by Web 3.0 or for it? — interview with Mikhail Danieli, project visionary and ambassador about the future of the platform and the company.


213. Why Python Is Leading the Charge in Data Analytics
Python is one of the oldest mainstream programming languages, which is now gaining even more ground with a growing demand for big data analytics. Enterprises continue to recognize the importance of big data, and $189.1 billion generated by big data and business analytics in 2019 proves it right.

214. ‘Data Science Is Not a Math Skill but a Life Skill’: Noonies Nominee Kirk Borne
From astrophysics to data science, here's a story of a lifetime journey with modeling the Universe and other dynamic things that move through space and time.


215. Building an AI Red Team to Stop Problems Before They Start
An incredible 87% of data science projects never go live.

216. Best Libraries That Will Assist You In EDA: 2021 Edition
Exploratory Data Analysis (EDA) is an essential step in the data science project lifecycle. Here are the top 10 python tools for EDA.

217. How to Build a Bar Chart Race on COVID-19 Cases in 5 Minutes
Using the new Tableau version 2020.1 onwards.


218. Features Selection by Using Xverse Package
Learn how to apply a variety of techniques to select features with Xverse package.


219. What is the Future for SQL Developers in a Machine Learning World?
Do you know the machine learning global market is estimated to reach $30.6 billion by 2024? This marvellous growth is the outcome of Omni-presence of artificial intelligence and its trending subset; machine learning.


220. The Simplest Way to do Exploratory Data Analysis(EDA) using Python Code
EDA for Data Analysis or Data Visualization is very important. It gives a brief summary and main characteristics of data. According to a survey, Data Scientist uses their most of time to perform EDA tasks.


221. Reinforcement Learning: 10 Real Reward & Punishment Applications
In Reinforcement Learning (RL), agents are trained on a reward and punishment mechanism. The agent is rewarded for correct moves and punished for the wrong ones. In doing so, the agent tries to minimize wrong moves and maximize the right ones.

222. How to Keep Your Machine Learning Models Up-to-Date
Performant machine learning models require high-quality data. And training your machine learning model is not a single, finite stage in your process. Even after you deploy it in a production environment, it’s likely you will need a steady stream of new training data to ensure your model’s predictive accuracy over time.

223. How LZ77 Data Compression Works
How does the ZIP format work?

224. Pycaret: A Faster Way to Build Machine Learning Models
Pycaret is an open-source, low code library in python that aims to automate the development of machine learning models.

225. #Mythbusting 10 Artificial Intelligence Misconceptions
Today, misconceptions about AI are spreading like wildfire.


226. Answering Metric Questions in Product Manager Interviews
Product manager interviews usually include a section on metrics. As a data scientist at Uber, I’ve often given or helped friends prepare for these interviews. The difference between candidates who crush the metric questions and those who struggle turns, as far as I can tell, on whether they have a framework that they can apply.


227. My Experience of Working with PyCharm JetBrains IDE
I always wanted to learn to code but was unable to give ample time because of my schedule. Thanks to Covid19, I started my python journey started recently in the lockdown.


228. Will AI Replace Copywriters?
Nowadays, everyone knows that the universal implementation of AI is drawing nearer and nearer. With the advancements of technology, and the growing demand for automated processes, in due time our world will change before our eyes. Especially with the current pandemic, people have realized how powerful the internet can be, primarily because they have the capacity to work 24/7.

229. 13 Best Datasets for Power BI Practice
In 2022, Gartner named Microsoft Power BI the Business Intelligence and Analytics Platforms leader. These are the 13 Best Datasets for Power BI Practice.


230. Interviews with My Machine Learning Heroes
Meta Article with links to all the interviews with my Machine Learning Heroes: Practitioners, Researchers and Kagglers.

231. Why Data Anomalies are More Important Than You Think
It is easy to be annoyed by strange anomalies when they are sighted within otherwise clean (or perhaps not-quite-so-clean) datasets. This annoyance is immediately followed by eagerness to filter them out and move on. Even though having clean, well-curated datasets is an important step in the process of creating robust models, one should resist the urge to purge all anomalies immediately — in doing so, there is a real risk of throwing away valuable insights that could lead to significant improvements in your models, products, or even business processes.


232. Data Testing for Machine Learning Pipelines Using Deepchecks, DagsHub, and GitHub Actions
A complete setup of a ML project using version control (also for data with DVC), experiment tracking, data checks with deepchecks and GitHub Action

233. Crunching Large Datasets Made Fast and Easy: the Polars Library
Processing large data, e.g. for cleansing, aggregation or filtering is done blazingly fast with the Polars data frame library in python thanks to its design.


234. How Big is BIG DATA Really?
If you have an answer, we’d love to hear from you.


235. Introduction to Great Expectations, an Open Source Data Science Tool
This is the first completed webinar of our “Great Expectations 101” series. The goal of this webinar is to show you what it takes to deploy and run Great Expectations successfully.


236. Using a Relational Database to Query Unstructured Data
Using Relational Database to search inside unstructured data


237. 10 Best Reddit Datasets for NLP and Other ML Projects
In this post, I wanted to share a Reddit dataset list that gained a lot of traction on social media when it was first posted.
238. Where to Learn Machine and Deep Learning for Free

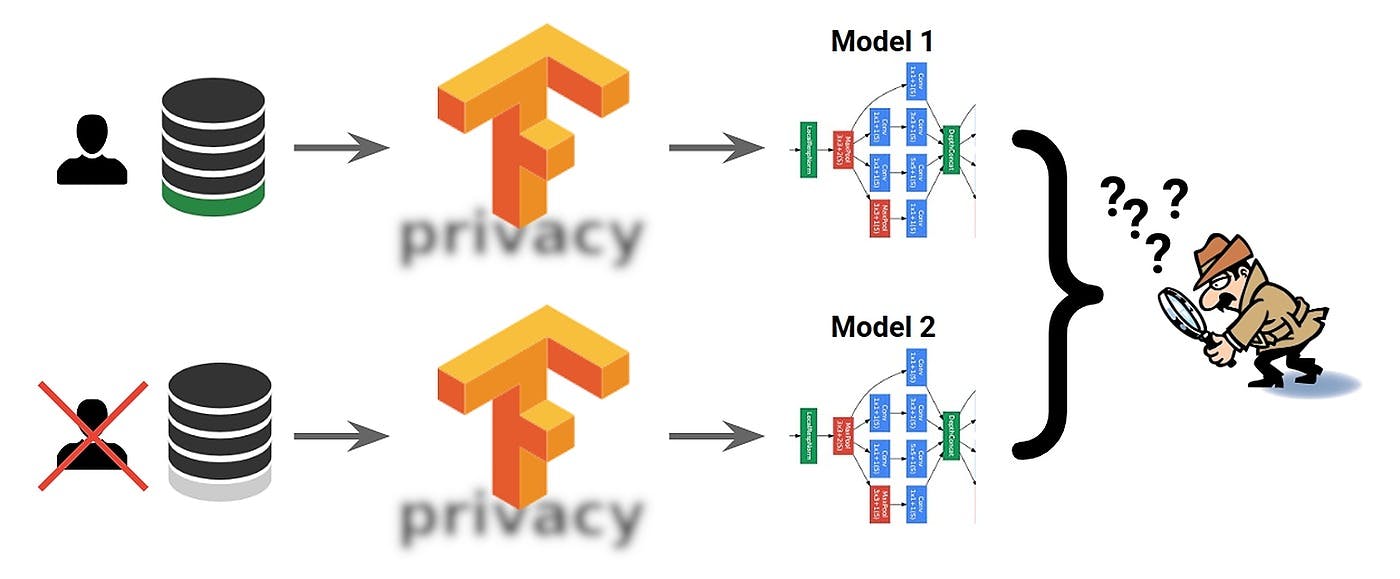
[239. Differential Privacy with Tensorflow 2.0 : Multi class Text Classification
Privacy](https://hackernoon.com/differential-privacy-with-tensorflow-20-multi-class-text-classification-privacy-yk7a37uh) Introduction

240. DreamFusion: An AI that Generates 3D Models from Text
Here’s DreamFusion, a new Google Research model that can understand a sentence enough to generate a 3D model of it.


241. Machine Learning News Roundup - 6 Essential AI Articles of 2019

242. How to Use Data Science to Find the Best Seat in the Cinema (Part I)
From the most popular seats to the most popular viewing times, we wanted to find out more about the movie trends in Singapore . So we created PopcornData — a website to get a glimpse of Singapore’s Movie trends — by scraping data, finding interesting insights, and visualizing them.

243. Polygon data: What it is and how can it be used?
This blog explains about polygon data, its benefits and how it is widely used in geomarketing, indoor mapping, and mobility analysis for orgnaizations.


244. Beat The Heat with Machine Learning Cheat Sheet
If you are a beginner and just started machine learning or even an intermediate level programmer, you might have been stuck on how do you solve this problem. Where do you start? and where do you go from here?

245. 11 Awesome (and Worrisome) Applications of AI
For years AI was touted to be the next big technology. Expected to revolutionize the job industry and effectively kill millions of human jobs, it became the poster child for job cuts. Despite this, its adoption has been increasingly well-received. To the tech experts, this wasn’t really surprising given its vast range of use cases.

246. ML Essentials: Top 10 Lists Every Data Scientist Should Know
Data Science is no doubt the "sexiest" career path of the 21st century, made up of people with strong intellectual curiosity and technical expertise to dig out valuable insights from humongous volumes of data. This helps firms add value by improving their productivity, unlocking insights for better decision making and profit gains, just to mention a few. The knowledge of Data Science is desirable and useful across various industries.

247. Machine Learning 101: How And Where To Start For Absolute Beginners
This post covers all you will need for your Journey as a Beginner. All the Resources are provided with links. You just need Time and Your dedication.


248. BI Analyst Interview Questions And Answers: 2020 Edition
Why you should prepare for BI analyst interview questions?

249. Top Dev Jokes Of 2019
Having fun while developing is necessary for programmers and developers. No matter how much serious or tough the situation is, one should always take things lightly when it comes to software development.


250. Data Preprocessing
At the heart of Machine Learning is to process data. Your machine learning tools are as good as the quality of your data. This blog deals with the various steps of cleaning data. Your data needs to go through a few steps before it is could be used for making predictions.

251. How to Build the Perfect CV to Land a Data Science Role
Looking to make your data scientist resume more attractive to employers?

252. Takeaways And Quotes From The World’s Largest Kaggle GrandMaster Panel


253. How to Structure a PyTorch ML Project With Google Colab and TensorBoard
Let’s build a fashion-MNIST CNN, PyTorch style. This is A Line-by-line guide on how to structure a PyTorch ML project from scratch using Google Colab and TensorBoard


254. Powering the Future: Decentralized Oracles and Metaverse DNA
In the decade-long history of blockchain and distributed ledger technology (DLT), rapid developments have led to consistent advances in the capabilities of decentralized financial platforms. By today’s standards Bitcoin has its limits: it supports value transfer and the storage of metadata within those transfers, but little else. With a block time of 10 minutes and a maximum block size of roughly four megabytes, it is also extremely slow compared to the emergent blockchains of the past few years.

255. Meta's New Model OPT is an Open-Source GPT-3
We’ve all heard about GPT-3 and have somewhat of a clear idea of its capabilities. You’ve most certainly seen some applications born strictly due to this model, some of which I covered in a previous video about the model. GPT-3 is a model developed by OpenAI that you can access through a paid API but have no access to the model itself.

256. Ten Future Technologies That Aren't in the Public Eye (Yet)
CRISPR, Quantum, Graphene, Smart Dust, Digital Twins, the Metaverse… You’ve heard about it all. Seen it all. Read it all. Or have you?

257. How Data Scientists Start Automating Their Tasks With Python
Introduction to automation with python and my top 3 most used code snippets.

258. AI Facts Every Dev Should Know: Artificial intelligence is older than you, probably
The hype around AI is growing rapidly, as most research companies predict AI will take on an increasingly important role in the future.


259. How Machine Learning is Used in Astronomy
Is Astronomy data science?


260. 13 Highest paying Tech Jobs Software Engineers can aim to increase their Pay
If you are a computer science graduate or someone who is thinking of making a career in the software development world or an experienced programmer who is thinking about his next career move but not so sure which field you should go then you have a come to the right place.

261. How to Web Scrape Using Python, Snscrape & HarperDB
Learn how to execute web scraping on Twitter using the snsscrape Python library and store scraped data automatically in database by using HarperDB.

262. Reflecting On My First 5 Months As An Open-Source Contributor
This is the story of how I started contributing to open source, along with 3 solid reasons why you should start contributing to open source too.


263. Retraining Machine Learning Model Approaches
Retraining Machine Learning Model, Model Drift, Different ways to identify model drift, Performance Degradation

264. Top 10 Data Science Project Ideas for 2020
As an aspiring data scientist, the best way for you to increase your skill level is by practicing. And what better way is there for practicing your technical skills than making projects.

265. A Pleasant Way to Kick Off Your Data Science Education- This is CS50
So You Want to Get Into Data Science


266. Regression Analysis on Life Expectancy
Models used: Linear, Ridge, LASSO, Polynomial Regression Python codes are available on my GitHub

267. A Complete Guide To The Machine Learning Tools On AWS
In this article, we will take a look at each one of the machine learning tools offered by AWS and understand the type of problems they try to solve for their customers.


268. AI vs ML: What's the Difference?
Learn the distinctions between AI and ML with vivid examples.


269. Why 87% of Machine learning Projects Fail
This article will serve as a lesson on the shocking reasons for your AI adoption disaster. We see news about machine learning everywhere. Indeed, there is lot of potential in machine learning. According to Gartner’s predictions, “Through 2020, 80% of AI projects will remain alchemy, run by wizards whose talents will not scale in the organization” and Transform 2019 of VentureBeat predicted that 87% of AI projects will never make it into production.

270. How to Create an Engaging README for Your Data Science Project on Github
The README file is the very first item that developers examine when they access your Data Science project hosted on GitHub. Every developer should begin their exploration of your Data Science project by reading the README file. This will tell them everything they need to know, including how to install and use your project, how to contribute (if they have suggestions for improvement), and everything else.


271. Implementing the Weighted Random Algorithm with JavaScript
The Weighted Random algorithm is used to send HTTP requests to Nginx servers. In this article, you'll learn how the Weighted Random algorithm works.


272. How To Build and Deploy an NLP Model with FastAPI: Part 2
Learn how to build an NLP model and deploy it with a fast web framework for building APIs called FastAPI.

273. Using Machine Learning to Recommend Investments in P2P Lending
Introducing PeerVest: A free ML app to help you pick the best loan pool on a risk-reward basis


274. How No-Code Can Rekindle Your Relationship With Data Science
A modern business user’s relationship with data is fairly complicated. It starts with curiosity. “Which of my top users will do X,Y, or Z?” You need a data output to move forward with a decision—except you’re having communication issues.

275. About The Meteoric Rise of the Low Code Data Scientist
If you’re not already using low-code platforms, you will be very soon. Low-code is helping to significantly speed up timelines, while bringing down costs


276. We Built A Coronavirus Map with COVID-19 Data and Travel Restrictions Across All Countries
Back in March my teammates and I switched from our regular tasks working on a travel platform to building a COVID-19 monitoring service. Here is what we’ve managed to get done so far:


277. Implementation of Data Preprocessing on Titanic Dataset

278. A GAN approach To Synthetic Time-Series Data
Although sequential data is pretty common to be found and highly useful, there are many reasons that lead to not leverage it


279. How AI and Robots are Shaping Healthcare
Artificial intelligence (AI), machine learning and data science are really starting to shape the delivery of healthcare services. We see it in almost every significant activity, from the management of patient scheduling through to physically assisting surgery.

280. How To Deploy Metabase on Google Cloud Platform (GCP)?
Metabase is a business intelligence tool for your organisation that plugs in various data-sources so you can explore data and build dashboards. I'll aim to provide a series of articles on provisioning and building this out for your organisation. This article is about getting up and running quickly.

281. Crowdsourcing Data Labeling for Machine Learning Projects [A How-To Guide]
Research suggests that data scientists spend a whopping 80% of their time preprocessing data and only 20% on actually building machine learning models. With that in mind, it’s no wonder why the machine learning community was quick to embrace crowdsourcing for data labeling. Crowdsourcing helps break down large and complex machine learning problems into smaller and simpler tasks for a large distributed workforce.

282. Increase The Size of Your Datasets Through Data Augmentation
Access to training data is one of the largest blockers for many machine learning projects. Luckily, for various different projects, we can use data augmentation to increase the size of our training data many times over.

283. Anscombe’s Quartet And Importance of Data Visualization
Anscombe’s quartet comprises four data sets that have nearly identical simple descriptive statistics, yet have very different distributions and appear very different when graphed. — Wikipedia


284. Why Artificial Intelligence Projects Fail
Over the last few months, I have seen the number of AI projects taken up significantly and most of the folks working on AI projects in their firms are planning to increase their AI initiatives even further over the next 12 months. Many of these initiatives come with high expectations but AI projects are far from fool-proof. In fact, there are predictions that more than half of all AI projects will fail to deliver against their expectations.

285. Bayesian Brain: Is Your Brain a Data Scientist?
Is your Brain a Data Scientist? Yes, according to the Bayesian Brain Hypothesis, your brain is a Bayesian statistician. Let me explain.

286. Summarizing Most Popular Text-to-Image Synthesis Methods With Python
Comparative Study of Different Adversarial Text to Image Methods

287. Building Handwritten Digits Recognizer using Support Vector Machine
Handwriting Recognition:

288. 5 Best AI Articles of the Month

Here are the five best articles related to artificial intelligence in May posted on Hackernoon.
289. Credit Card Fraud Detection via Machine Learning: A Case Study
A machine learning guide on how to identify fraudulent credit card transactions by using the PyOD toolkit.


290. Launching Your Own JavaScript Based Face Recognition Algorithm [A How-To Guide]
JavaScript based face recognition with Face API and Docker.he


291. A Quick Introduction to Python Numpy for Beginners
This tutorial will help you get started with NumPy by teaching you to visualize multidimensional arrays.

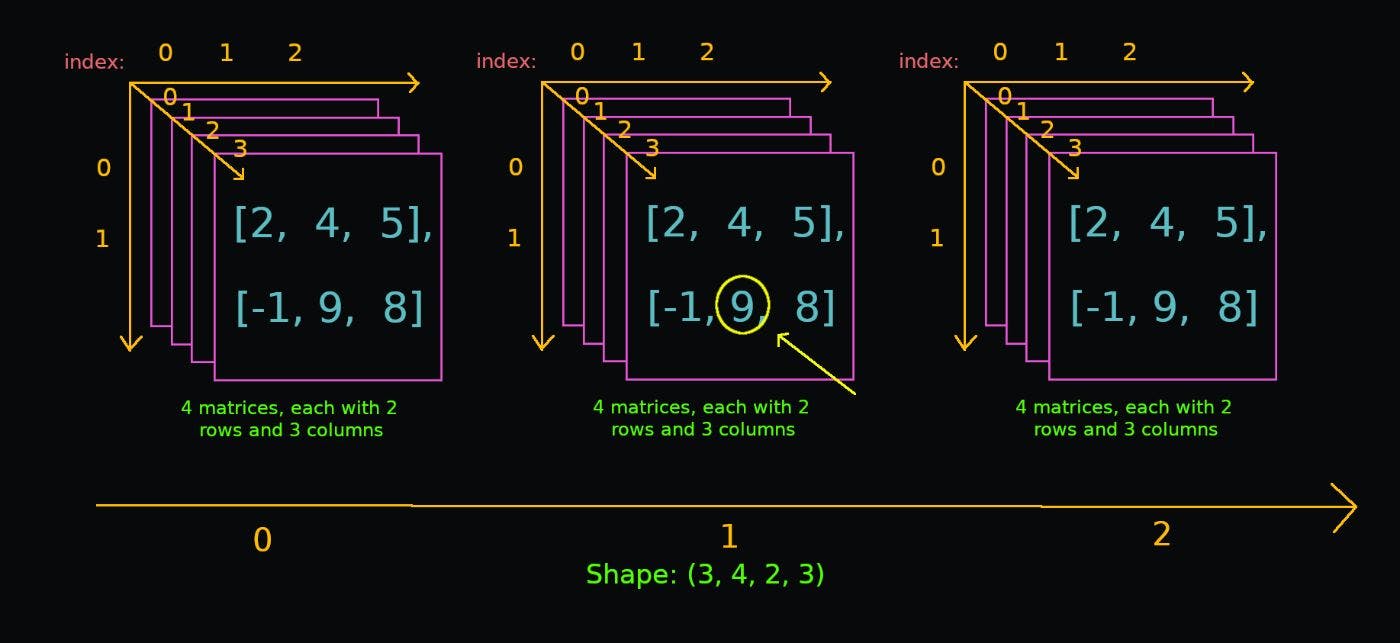
292. The Importance of Hypothesis Testing
Hypothesis tests are significant for evaluating answers to questions concerning samples of data.


293. I Built a Boxing Prediction Web App on Shiny, Here's How
As part of my data-science career track bootcamp, I had to complete a few personal capstones. For this particular capstone, I opted to focus on building something I personally care about - what better way to learn and possibly build something valuable than by working on a passion project.


294. Gain State-Of-The-Art Results on Tabular Data with Deep Learning & Embedding Layers [A How To Guide]
Tree-based models like Random Forest and XGBoost have become very popular in solving tabular(structured) data problems and gained a lot of tractions in Kaggle competitions lately. It has its very deserving reasons. However, in this article, I want to introduce a different approach from fast.ai’s Tabular module leveraging.

295. Using Flask to Build a Rule-based Chatbot in Python
Learn to build AI ruled-based chatbot with a simple tutorial that can be showcased in your Portfolio.


296. 7 Data Analysis Steps You Should Know
To analyze data adequately requires practical knowledge of the different forms of data analysis.

297. Restructure or Recycle: Making the Right Data-driven Decisions
Understanding the difference between restructuring and recycling data allows analysts to make better-educated decisions.

298. 5 Best Machine Learning Books for ML Beginners
Here is a list of the best books to learn machine learning for beginners to help build their careers in the ML Industry.


299. Understanding SQL's Application in Data Science [A Deep Dive]
To learn about SQL, we need to understand how a DBMS works. DBMS or Database Management System is essentially a software to create and manage databases.

300. Busting Data Science Myths: "You Need a PhD, Extensive Python Skills, and Tons of Experience"
DJ Patil and Jeff Hammerbacher coined the title Data Scientist while working at LinkedIn and Facebook, respectively, to mean someone who “uses data to interact with the world, study it and try to come up with new things.”

301. How to Use Streamlit and Python to Build a Data Science App
Web apps are still useful tools for data scientists to present their data science projects to the users. Since we may not have web development skills, we can use open-source python libraries like Streamlit to easily develop web apps in a short time.


302. Going From Not Being Able To Code To Deep Learning Hero
A detailed plan for going from not being able to write code to being a deep learning expert. Advice based on personal experience.


303. 👨🔬️ Top 10 Data Scientist Skills to Develop to Get Yourself Hired
List of Top 10 Data Scientist skills that guaranteed employment. As well as a selection of helpful resources to master these skills


304. Influenza Vaccines: The Data Science Behind Them
Influenza Vaccines and Data Science in Biology


305. An Introduction to Automation in Vision AI
Levels of Annotation Automation


306. Why You Should Stop Your Reading Challenge
Image: Goodreads.com


307. Training Your Models on Cloud TPUs in 4 Easy Steps on Google Colab
You have a plain old TensorFlow model that’s too computationally expensive to train on your standard-issue work laptop. I get it. I’ve been there too, and if I’m being honest, seeing my laptop crash twice in a row after trying to train a model on it is painful to watch.


308. Improve Machine Learning Model Performance by Combining Categorical Features
Learn how to combine categorical features in your dataset to improve your machine learning model performance.

309. What Are Convolution Neural Networks? [ELI5]
Universal Approximation Theorem says that Feed-Forward Neural Network (also known as Multi-layered Network of Neurons) can act as powerful approximation to learn the non-linear relationship between the input and output. But the problem with the Feed-Forward Neural Network is that the network is prone to over-fitting due to the presence of many parameters within the network to learn.

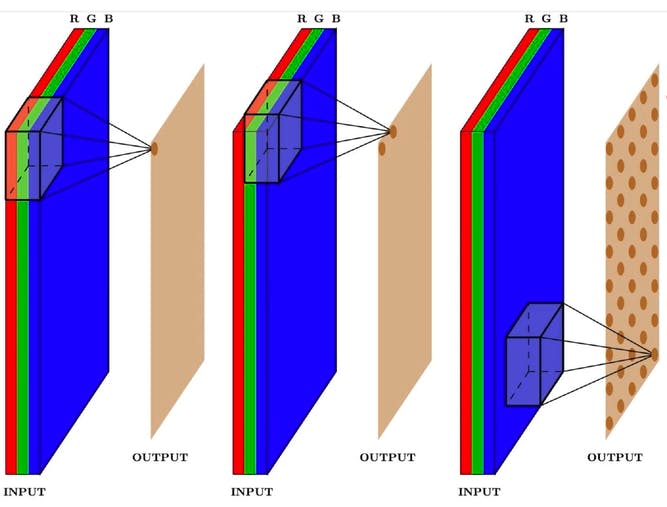
310. 5 Companies Developing Computer Vision Technology in 2020
Computer vision technology is the poster child of artificial intelligence. It is the sector of the industry that gets the most media attention because of the tools and benefits the technology can provide. From autonomous vehicles and drones to cancer detection and augmented reality, technologies that once only existed in science fiction are now at our doorstep.

311. How I Broke Into Data Science
A software engineer’s journey into data science at Yelp and Uber

312. Programming From 8 To 80
Is there a programming language that's good for every user from age 8 to 80? You bet! It's called Smalltalk.


313. Anomaly Detection Strategies for IoT Sensors
Motivation - Algorithms for IoT sensors

314. Driver Drowsiness Detection System: A Python Project with Source Code
Drowsiness detection is a safety technology that can prevent accidents that are caused by drivers who fell asleep while driving.


315. 10 Patterns of Centralized Crypto Exchanges Explained Using Machine Learning and Data Visualizations
Centralized crypto exchanges are the most important black box of the crypto ecosystem. We all use them, we have a love-hate relationship with them, and we understand very little about their internal behavior. At IntoTheBlock, we have been heads down working on a series of machine learning models that help us better understand the internal of crypto exchanges. Recently, we presented some of our initial findings at a highly oversubscribed webinar and I thought it would be elaborate further in some of the ideas discussed there.

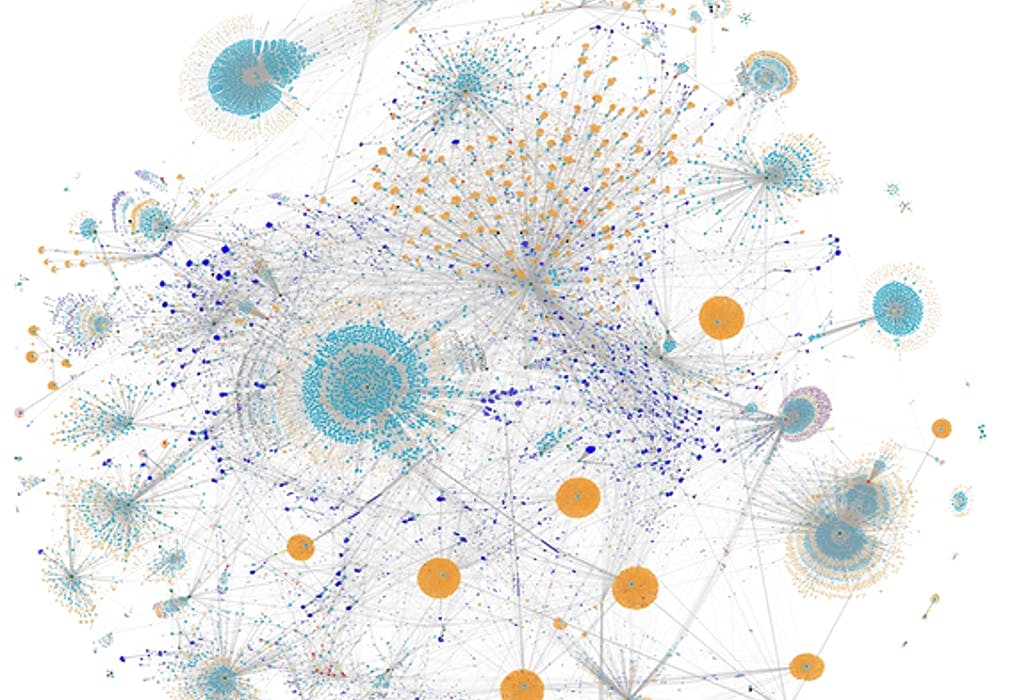
316. How to Deploy Machine Learning Models to the Cloud Quickly and Easily
Machine learning models are usually developed in a training environment (online or offline). And you can then deploy them and use them with live data.

317. Top 20 Twitter Datasets for Machine Learning Projects
It is often very difficult for AI researchers to gather social media data for machine learning. Luckily, one free and accessible source of SNS data is Twitter.

318. Facial Recognition Comparison with Java and C ++ using HOG
HOG - Histogram of Oriented Gradients (histogram of oriented gradients) is an image descriptor format, capable of summarizing the main characteristics of an image, such as faces for example, allowing comparison with similar images.


319. Machine Learning in Cybersecurity: 5 Real-Life Examples
From real-time cybercrime mapping to penetration testing, machine learning has become a crucial part of cybersecurity. Here's how.


320. Intro to Jupiter Notebooks
“Notebooks” are web applications that run on the browser which basically give you, the user, an interface to a virtual machine that runs an out-of-the-box environment. They are based on the Jupyter Notebook project — an open-source project that brings machine learning development to your browser! No more virtual environment set-up hassle from now on. Which is great news since a lot of developers want to deal only with data science projects and not get derailed from that by needing to configure and set up their computers.


321. 6 important Python Libraries for Machine Learning and Data Science
In this guide, we’ll show the must know Python libraries for machine learning and data science.


322. Avengers Ensemble: How Ensemble Modeling Helps You Avoid Overfitting
Ensemble modelling helps you avoid overfitting by reducing variance in the prediction and minimizing modelling method bias.

323. Universal Data Tool: New Skeletal/Pose/Landmark Annotation, Dutch, and Convert Options
For those who haven’t heard of the Universal Data Tool, it is an open-source web or desktop program to collaborate, build and edit text, image, video, and audio datasets with labels and annotations.


324. 5 Things to Watch Out for When Implementing Tableau BI
Has your organization decided to adopt and implement the Tableau BI platform, namely its Tableau Server and Tableau Online versions?

325. Intro to Neural Networks: CNN vs. RNN
In machine learning, each type of artificial neural network is tailored to certain tasks. This article will introduce two types of neural networks: convolutional neural networks (CNN) and recurrent neural networks (RNN). Using popular Youtube videos and visual aids, we will explain the difference between CNN and RNN and how they are used in computer vision and natural language processing.

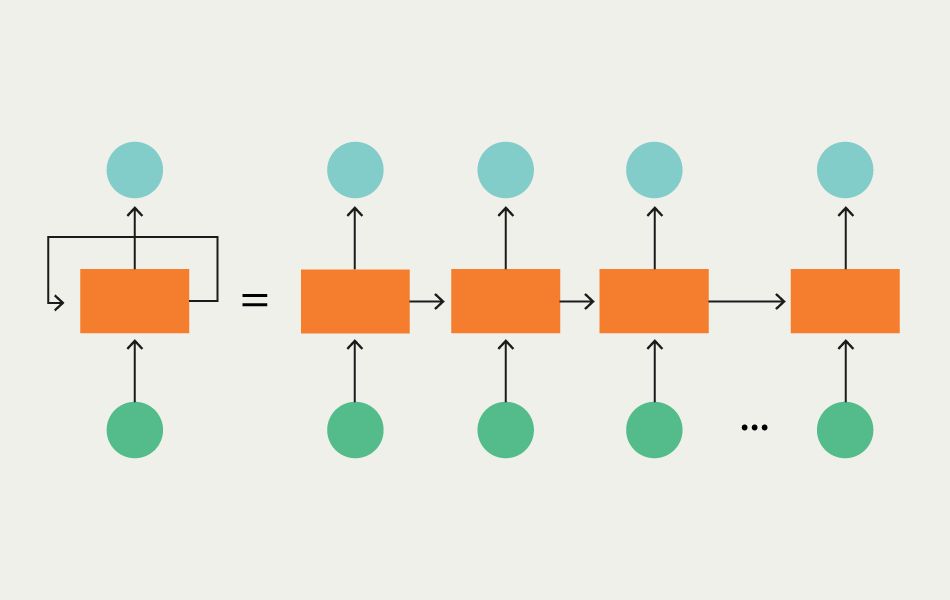
326. The One Data Science Project Idea That’ll Impress Interviewers
Let’s talk about the one and only project you need to build, that’ll help you gain fullstack data science experience, and impress interviewers on your interviews if your goal is to jumpstart your career in data science.


327. How to Manage Machine Learning Products [ Part II]
Best practices and things I’ve learned along the way.


328. 6 Essential Tips to Solve Data Science Projects
Data science projects are focusing on solving social or business problems by using data. Solving data science projects can be a very challenging task for beginners in this field. You will need to have a different skills set depending on the type of data problem you want to solve.


329. Beyond Artificial Intelligence: Providing Insights to Your Customers
<meta name="monetization" content="$ilp.uphold.com/EXa8i9DQ32qy">

330. Data Science in Finance: 5 Ways It Changed the Industry
What’s the Role of Data Science in Finance?

331. COVID-19: "In God We Trust, All Others Must Bring [CLEAN] Data"
In these difficult days for all of us, I’ve heard all sorts of things. From the fake news sent through Whatsapp, like vitamin C can save your life, to holding your breath in the morning to check if you’ve been hit by COVID-19. The mantra that everyone keeps repeating is “stay at home!”, okay fine, but what exactly does “stay home” mean? The question seems ridiculous when you think of a relatively short period, 15 days? A month? But if we look critically at the situation, we surely realize that it won’t be 15 days, and it won’t be a month. It will be a long, long time. Why am I saying this? Because “stay at home” doesn’t protect us from the virus. Staying at home is to protect our health care facilities from collapse. And I’m not saying that this is wrong. I’m just saying that if we want to protect the health care system from collapse, well then we’ll stay home a long, long time. But in doing so we will irreparably damage the economic system by profoundly changing our social and political model. It is inevitable. Let’s face it and not have too many illusions.

332. Dimensionality Reduction Using PCA : A Comprehensive Hands-On Primer
We, humans, are experiencing tailor-made services which have been engineered right for us, we are not troubled personally, but we are doing one thing every day, which is kind of helping this intelligent machine work day and night just to make sure all these services are curated right and delivered to us in the manner we like to consume it.

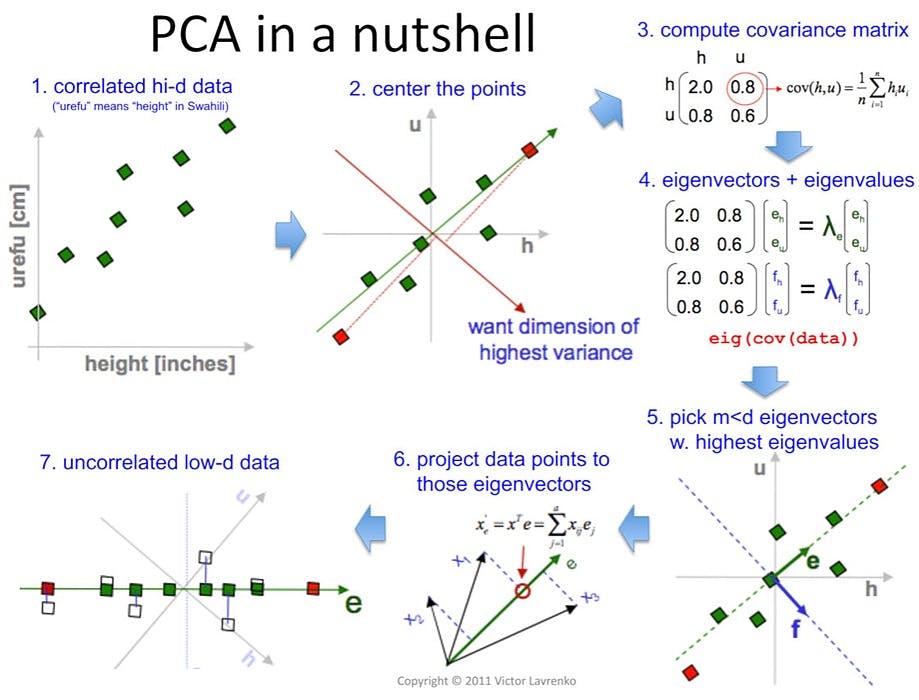
333. How to Build Machine Learning Algorithms that Actually Work
Applying machine learning models at scale in production can be hard. Here's the four biggest challenges data teams face and how to solve them.

334. The Essential Architectures For Every Data Scientist and Big Data Engineer
Comprehensive List of Feature Store Architectures for Data Scientists and Big Data Professionals

335. Database Vs Data Warehouse Vs Data Lake: A Simple Explanation
A data lake is totally different from a data warehouse in terms of structure and function. Here is a truly quick explanation of "Data Lake vs Data Warehouse".

336. Best Machine Learning Books You Should Read: 2020 Edition
These books cover the Introductory level to Expert level of knowledge and concepts in ML. These Books have some core factors about ML. Give them a try. Lets Start.


337. Behaviors Trees in AI: Why you Should Ditch Your Event Framework
In this article, I look into some of the shortages of event-driven programming and suggest behavior trees as an effective alternative, suitable for back/front-end application development.


338. How to Create a Bubble Map with JavaScript to Visualize Election Results
A beginner level tutorial to get started with data visualization by creating an interesting and intuitive JavaScript bubble map


339. Top AI and ML YouTube Channels for Data Scientists to Subscribe to
Subscribe to these Machine Learning YouTube channels today for AI, ML, and computer science tutorial videos.

340. Introductory Guide To Real-time Object Detection with Python
Researchers have been studying the possibilities of giving machines the ability to distinguish and identify objects through vision for years now. This particular domain, called Computer Vision or CV, has a wide range of modern-day applications.

341. 23 Common Data Science Interview Questions for Beginners
In 2012, Harvard Business Review called data scientists the sexiest job of the 21st century. However, correctly answering data science interview questions to get a job as a data scientist is very tricky.


342. How to Build Basic Chatbot Without Coding and Deploy to Websites
Build best automated AI chat bot using Google Dialog flow


343. WTF is Automatic Speech Recognition?
Automatic speech recognition (ASR) is the transformation of spoken language into text. If you’ve ever used a virtual assistant like Siri or Alexa, you’ve experienced using an automatic speech recognition system. The technology is being implemented in messaging apps, search engines, in-car systems, and home automation.

344. 10 Best + Free Machine Learning Courses Collection
Here's a compilation of some of the best + free machine learning courses available online.


345. How POST Requests with Python Make Web Scraping Easier
To scrape a website, it’s common to send GET requests, but it's useful to know how to send data. In this article, we'll see how to start with POST requests.


346. Simulating a Prolonged Cryptocurrency Bear Market with the Monte Carlo Method
Half-way into 2018, it’s become clear that we’ve strayed far away from the jubilant exuberance that characterized the peak months of December and January.


347. THE BEST Photo to 3D AI Model !
As if taking a picture wasn’t a challenging enough technological prowess, we are now doing the opposite: modeling the world from pictures. I’ve covered amazing AI-based models that could take images and turn them into high-quality scenes. A challenging task that consists of taking a few images in the 2-dimensional picture world to create how the object or person would look in the real world.

348. Why Every Software Engineer Should Learn Python?
Hello guys, If you follow my blog regularly, or read my articles here on HackerNoon, then you may be wondering why am I writing an article to tell people to learn Python? Didn’t I ask you to prefer Java over Python a couple of years ago?


349. Python For Beginners: Learning One-Liners On Practice
Like lists comprehensions and lambda functions python one line codes can save a lot of time and space so how you can master them?


350. Essential Guide to Transformer Models in Machine Learning
Transformer models have become the defacto standard for NLP tasks. As an example, I’m sure you’ve already seen the awesome GPT3 Transformer demos and articles detailing how much time and money it took to train.
351. Self-Supervised Machine Learning: The Story So Far and Trends For 2021
Let’s talk about self-supervised machine learning - a way to teach a model a lot without manual markup, as well as an opportunity to avoid deep learning when setting a model up to solve a problem. This material requires an intermediate level of preparation; there are many references to original publications.

352. Machine Learning Trends Businesses Should Know In 2020
Have you ever considered how much data exists in our world? Data growth has been immense since the creation of the Internet and has only accelerated in the last two decades. Today the Internet hosts an estimated 2 billion websites for 4.2 billion active users.


353. A Guide to Scraping HTML Tables with Pandas and BeautifulSoup
How to not get stuck when collecting tabular data from the internet.
354. Reflinks vs symlinks vs hard links, and how they can help machine learning projects
Hard links and symbolic links have been available since time immemorial, and we use them all the time without even thinking about it. In machine learning projects they can help us, when setting up new experiments, to rearrange data files quickly and efficiently in machine learning projects. However, with traditional links, we run the risk of polluting the data files with erroneous edits. In this blog post we’ll go over the details of using links, some cool new stuff in modern file systems (reflinks), and an example of how DVC (Data Version Control, https://dvc.org/) leverages this.


355. What Data Science Has Taught Me
I always tell people that data is not the new oil, instead, it is the new time machine.

356. How to Build Your Own PyTorch Neural Network Layer from Scratch
This is actually an assignment from Jeremy Howard’s fast.ai course, lesson 5. I’ve showcased how easy it is to build a Convolutional Neural Networks from scratch using PyTorch. Today, let’s try to delve down even deeper and see if we could write our own nn.Linear module. Why waste your time writing your own PyTorch module while it’s already been written by the devs over at Facebook?

357. What Happens When You Get Sick Right Now?
We are living in a weird time. Day by day we see more & more people coughing and getting sick, our neighbors, coworkers on Zoom calls, politicians, etc… But here’s when it becomes really, really scary — when you become one of “those” and have no clue what to do. Your reptile brain activates, you enter a state of panic, and engage complete freakout mode. That’s what happened to me this Monday, and I’m not sure I’m past this stage.


358. Building Machine Learning Algorithms That We Can Trust
How to Explain any machine learning model in minutes — with confidence and trust? Here's How:


359. What Data Scientists Should Know About Multi-output and Multi-label Training
Multi-output Machine Learning — MixedRandomForest

360. Unpredictability of Artificial Intelligence
The young field of AI Safety is still in the process of identifying its challenges and limitations. In this paper, we formally describe one such impossibility result, namely Unpredictability of AI. We prove that it is impossible to precisely and consistently predict what specific actions a smarter-than-human intelligent system will take to achieve its objectives, even if we know terminal goals of the system. In conclusion, impact of Unpredictability on AI Safety is discussed.


361. How to Train Computer Vision Models Efficiently
The starting point of building a successful computer vision application is the model. Computer vision model training can be time-consuming and challenging if one doesn’t have a background in data science. Nonetheless, it is a requirement for customized applications.

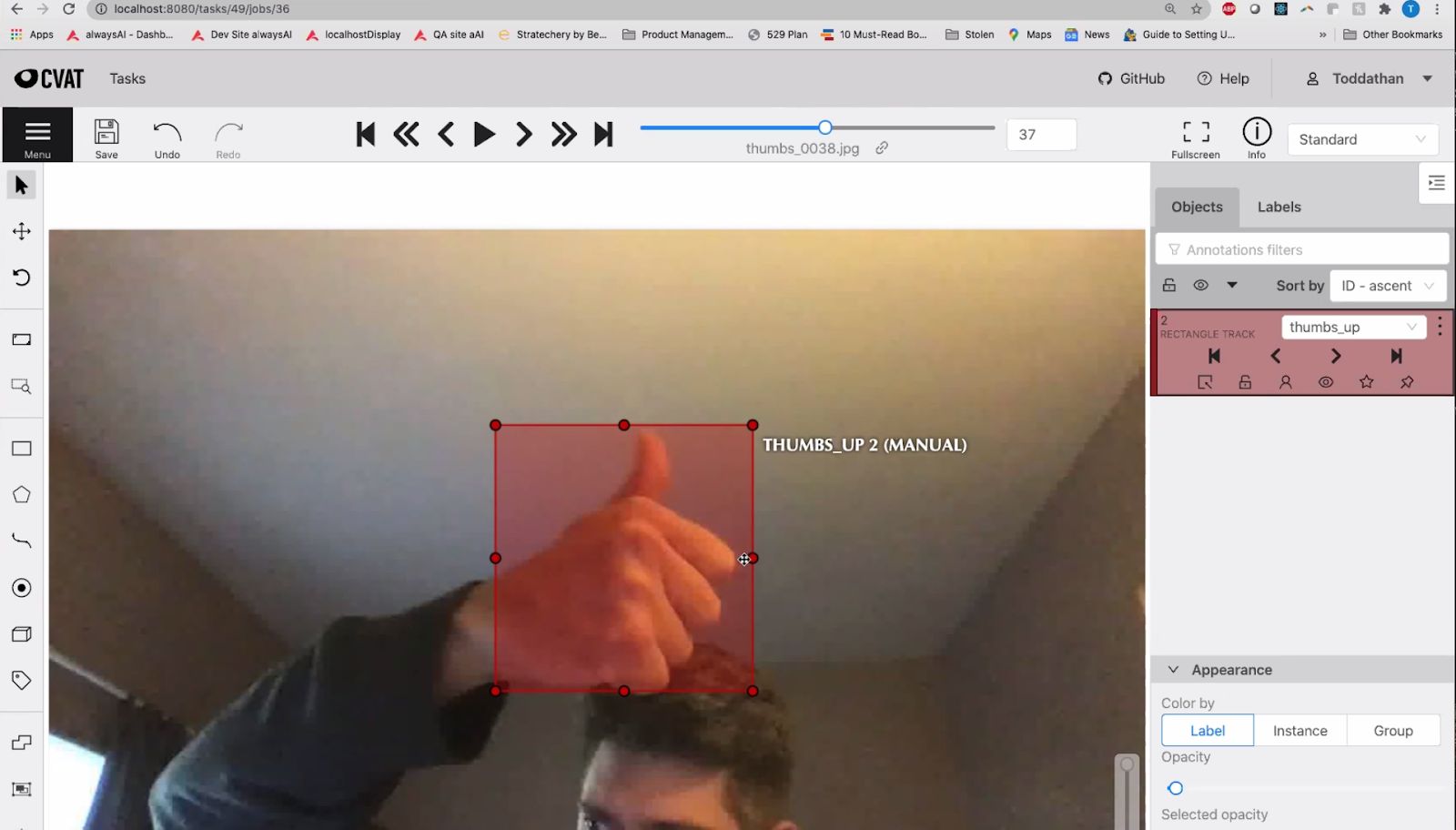
362. Algorithms and Society: A Not-So-Simple Discussion, In Three Parts
Image Source: Unified Infotech


363. Is The Modern Data Warehouse Dead?
Do we need a radical new approach to data warehouse technology? An immutable data warehouse starts with the data consumer SLAs and pipes data in pre-modeled.

364. What Are the Top Startups in Oceania?
At HackerNoon, we pride ourselves on supporting startups because we know how hard it can be to start and run a company.


365. Planning for Your Startup: The Data Team's Guide to 2021
Planning in a startup can feel like an exercise in futility — especially when it comes to data — especially when your data team is small and scrappy.


366. Popular Python Implementations [An Overview]
You read it right. It's all about implementation. Today, we will talk about the different implementations of Python. A heads up on the different kinds, be it Cpython, Brython, you name it.

367. Introducing the Swahili News Dataset for Topic Classification
Swahili (also known as Kiswahili) is one of the most spoken languages in Africa. It is spoken by 100–150 million people across East Africa. Swahili is popularly used as a second language by people across the African continent and taught in schools and universities. In Tanzania, it is one of two national languages (the other is English).

368. Extract Prominent Colors from an Image Using Machine Learning
This article explains how I found a nice and simple algorithm to extract prominent colors out of an image.


369. The Rise of the Planet of the AI
Humans never got chill and will never get. Constantly striving to reach the future faster, we made AI.


370. Data Science with Substance: Best Massive Open Online Courses
Benjamin Obi Tayo, in his recent post "Data Science MOOCs are too Superficial," wrote the following:

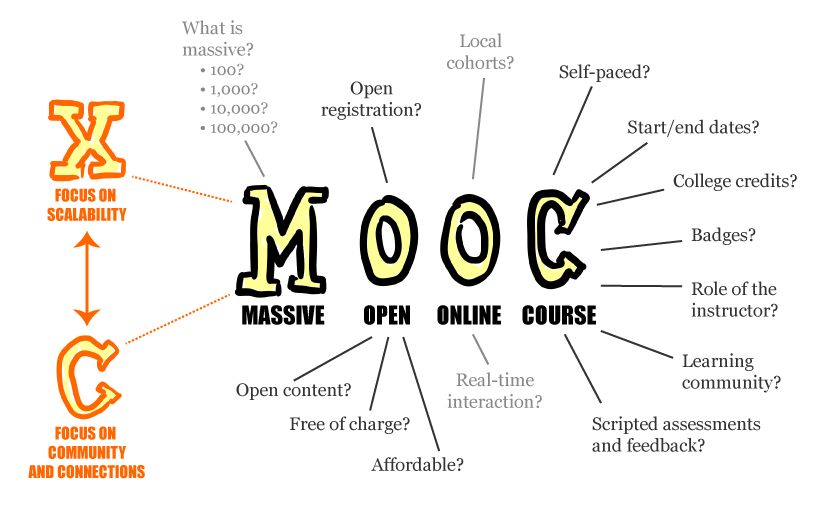
371. Linear Regression vs. Logistic Regression for Classification Tasks
This article explains why logistic regression performs better than linear regression for classification problems, and 2 reasons why linear regression is not suitable:

372. Building Spam Classification Using The Naive Bayes Algorithm
In this article, we scratch spam email classification using one of the simplest techniques called the Naive Bayes classification.
373. 10 Questions to Consider when Setting up a Corporate A.I project
By now, all self-respecting executives have heard of A.I and thought “Mmhm, yeah, I’d like to get myself a piece of that action”. And because they’re executives, they told underlings to get it going, and went back to the golf course. I personally see no problem with that way of doing things, as the underlings then go to consultants such as myself to understand what their boss could have possibly meant by “I want, like, Alexa, but, like, for office chairs” (yes, I have a PowerPoint presentation for that).


374. Amazon Data Science Interview: Window Functions and Aliasing
I have an advanced data science interview question from Amazon today. This question is going to test your date manipulation and formatting skills as well as our window function knowledge.

375. Data Science Feels Like a Fake Entrepreneur in a YouTube Ad
Throw away all your AI/ML bullshit bingo when you cannot understand the world in clean data.


376. How PostgreSQL Aggregation Inspired Timescale Hyperfunctions’ Design
Get a primer on PostgreSQL aggregation, how PostgreSQL´s implementation inspired us as we built TimescaleDB hyperfunctions and what it means for developers.


377. Minecraft May Offer the Best Model for Internet Governance
Looking at today’s Internet, it is easy to wonder: whatever happened to the dream that it would be good for democracy? Well, looking past the scandals of big social media and scary plays of autocracy’s hackers, I think there’s still room for hope. The web remains full of small experiments in self-governance. It’s still happening, quietly maybe, but at such a tremendous scale that we have a chance, not only to revive the founding dream of the web, but to bring modern scientific methods to basic millenia-old questions about self-governance, and how it works.


378. Machine-Learning Neural Spatiotemporal Signal Processing with PyTorch Geometric Temporal
PyTorch Geometric Temporal is a deep learning library for neural spatiotemporal signal processing.


379. How I'd Learn Data Science If I Were To Start All Over Again
A couple of days ago I started thinking if I had to start learning machine learning and data science all over again where would I start?


380. ColorDetection Module: Python Color Detection Algorithms
Images. That's it. Images. As a point of practicality, take a fashion designer (as a forum member vividly described to me at one point). You are given an image or have an image at your disposal that simply tickles your curiosity and want to incorporate it in one of your new lines. Let's swerve a little into the genetics section. Given a petri dish image for instance, with pigmented bacteria or similar organisms, and you would like to find the abundance of that organism or organisms in this specific image. Get the gist?

381. 7 Real-World Applications of AI in Healthcare

382. The Essential Data Cleansing Checklist
After some time working as a data scientist in my startup, I came to a point where I needed to ask for external help with your project.

383. Get Machine Learning Training Data Using The Lionbridge Method [A How-To Guide]
In the field of machine learning, training data preparation is one of the most important and time-consuming tasks. In fact, many data scientists claim that a large portion of data science is pre-processing and some studies have shown that the quality of your training data is more important than the type of algorithm you use.
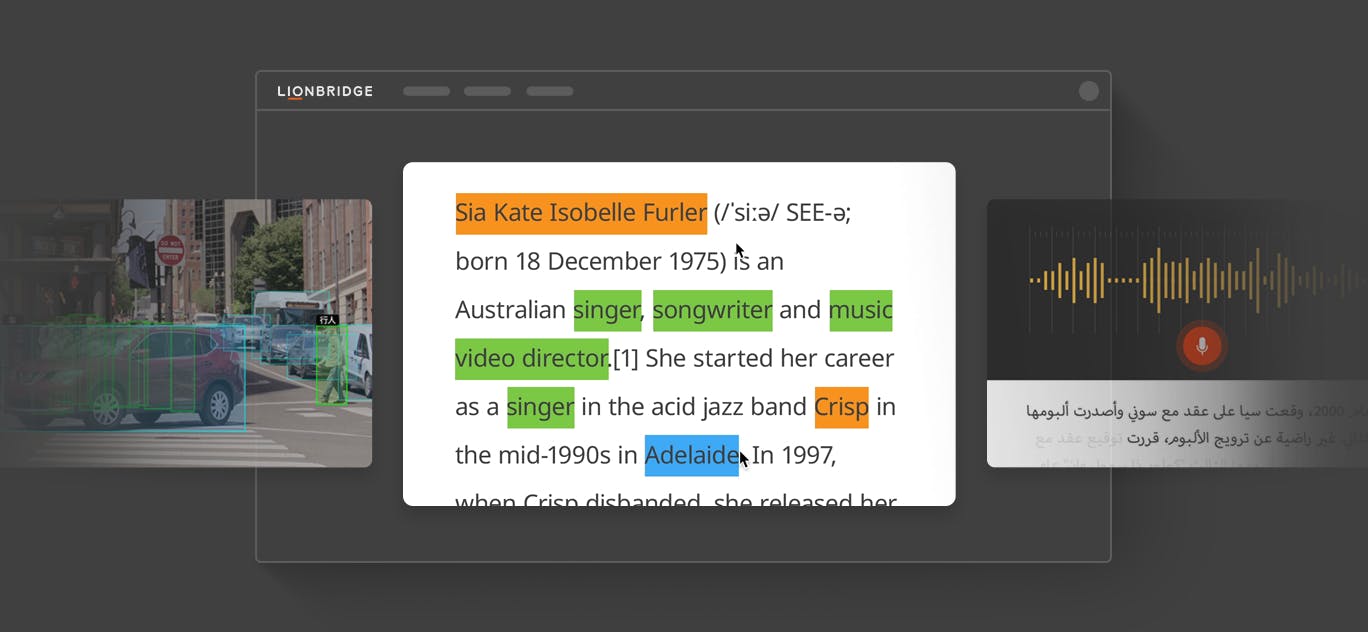
384. Can we be honest about ethics?
The “manifesto for data practices” (datapractices.org), was produced by a Data for Good Exchange, sponsored by Data for Democracy and Bloomberg, promoted by former U.S. Chief Data Scientist DJ Patil. The document’s creators incurred no risk by creating and promoting it, so it should not be surprising that the product fails to live up to its own ethical standards. We won’t fix ethics by fixing those tools, the creators of those tools built systematic bias into their products before deploying them.


385. Reinforcement Learning - The Value Function
Codes and demo are available. This article explores what are states, actions and rewards in reinforcement learning, and how agent can learn through simulation to determine the best actions to take in any given state.


386. I went on a Big Data Spree because of Covid19
Covid19 taken the world by storm. People have been panicking and buying toilet paper like no tomorrow. Celebrities have been making sure to keep us caught up on latest videos of them eating cereal. Anxious teens and twenty year olds have been extra moody.

387. Embeddings in Machine Learning: Everything You Need to Know
Here's a deep dive into the history of machine learning embeddings, common uses, and current infrastructure solutions, including the vector database.


388. Why Do We Use Hexagons And Not Sqaures to Aggregate Location Data
If you are a two-degree marketplace like Uber, you cater to millions of users requesting a ride through your driver partners accepting and fulfilling those requests. For a three-degree marketplace like Swiggy, there is another static component added (like restaurants or stores), where delivery partners pick up the orders.


389. Data Security 101 for First Time Data Labeling Outsourcers
AI project teams using large amounts of data with detailed labeling requirements can be up against the clock. The tools, human resourcing, and QA for maintaining precision can be a challenge. It’s easy to understand why outsourcing is preferred by most project teams. Outsourcing allows you to focus on core tasks.


390. The Rise of Reusable SQL-based Data Modeling Tools and DataOps services
The resurgence of SQL-based RDBMS


391. 6 Places to Start a Career in Data Science in 2022
How to become a data scientist? Want to become a Data Scientist? Here are the resources. Resources to Become a Data Scientist

392. Jeremy Howard’s fast.ai vs Andrew Ng’s deeplearning.ai - Are They That Different From Each Other?
How Not to ‘Overfit’ Your AI Learning by Taking Both fast.ai and deeplearning.ai courses


393. Visualizing the Recent Crypto Selloff
Analyzing the recent cryptocurrency crash from an altcoin perspective. Crypto selloff on heavy momentum after coming off euphoria in the last rally.

394. An Introduction to Data Connectors: Your First Step to Data Analytics
This post explains what a data connector is and provides a framework for building connectors that replicate data from different sources into your data warehouse

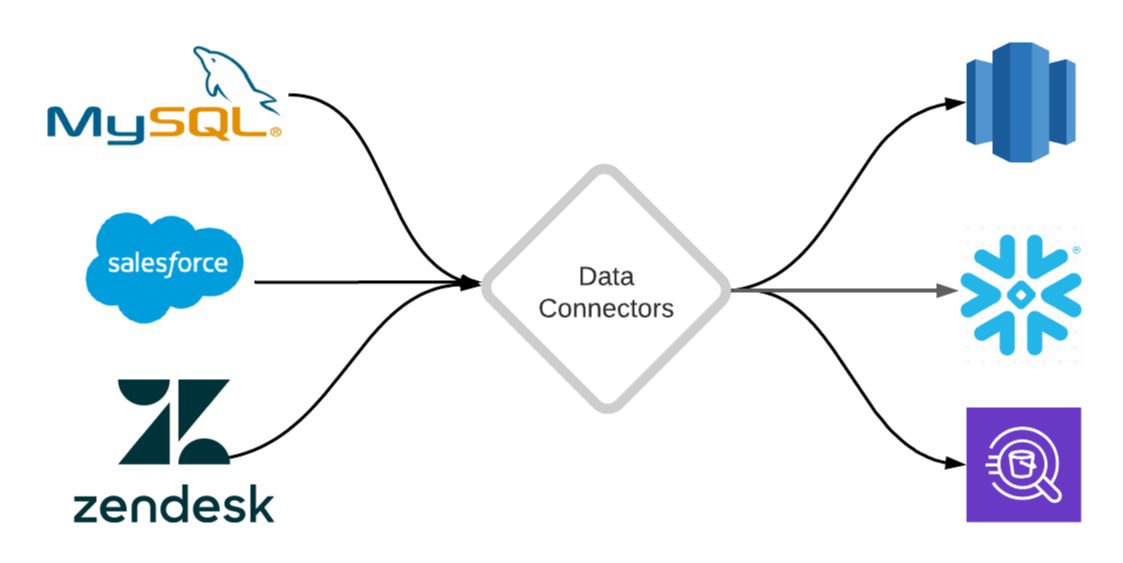
395. How Does Facial Recognition Work with Face Masks? [Explained]
With the spread of COVID-19 wearing face masks became obligatory. At least for most of the population. This created a problem for the current identification systems. For example, Apple’s FaceID struggled to recognize faces with masks.


396. Amazon ML Services: A Deep Dive Into AWS SageMaker
SageMaker is a fully managed service that enables developers to build, train, test and deploy machine learning models at scale.


397. Data Scientists, Software Engineers And The Future of Medicine
The world is changing, especially the way we cure ourselves. The rise of next generation computing, cloud computing technologies, AI, decentralization, etc. have dramatically changed seemingly every industry. Computational Medicine is now an emerging new discipline.

398. Automated Machine Learning for Data Analysts & Business Users
Automated Machine Learning (AutoML) represents a fundamental shift in the way organizations of all sizes approach machine learning & data science.


399. Data Visualization
What is Data Visualization ?


400. Use Up-Sampling and Weights to Address Imbalance Data Problem
Have you worked on machine learning classification problem in the real world? If so, you probably have some experience with imbalance data problem. Imbalance data means the classes we want to predict are disproportional. Classes that make up a large proportion of the data are called majority classes. Those that make up a smaller portion are minority classes. For example, we want to use machine learning models to capture credit card fraud, and fraudulent activities happens approximately 0.1% out of millions of transactions. The majority of regular transactions will impede the machine learning algorithm to identify patterns for the fraudulent activities.


401. How to Perform Data Augmentation with Augly Library
Data augmentation is a technique used by practitioners to increase the data by creating modified data from the existing data.


402. Docker Dev Workflow for Apache Spark
The benefits that come with using Docker containers are well known: they provide consistent and isolated environments so that applications can be deployed anywhere - locally, in dev / testing / prod environments, across all cloud providers, and on-premise - in a repeatable way.

403. Serve Data Models with MLFlow in Production
For organizations looking for a way to “democratize” data science, it is a must that data models are accessible to the enterprise in a very simple way. In our context, this is part of “model operationalization.” There are other solutions out there to serve data models which is a very common problem for data scientists.


404. Training Your Own Text Classification Model From Scratch With Tensorflow Is As Easy As ABC
Hello ML Newb! In this article, you will learn to train your own text classification model from scratch using Tensorflow in just a few lines of code.


405. CVPR 2021 Best Paper Award: GIRAFFE Controllable Image Generation
Using a modified GAN architecture, they can move objects in the image without affecting the background or the other objects!

406. This Neural Network Paints Depressing Russian Cityscapes
Russian doomer neural network creates paintings and music videos. Tutorial. Stylegan2 was trained on thousands of images of soviet architecture.


407. Freeing the Data Scientist's Mind from the Curse of Vectorization - Paging Julia for Rescue
Nowadays, most data scientists use either Python or R as their main programming language. That was also my case until I met Julia earlier this year. Julia promises performance comparable to statically typed compiled languages (like C) while keeping the rapid development features of interpreted languages (like Python, R or Matlab). This performance is achieved by just-in-time (JIT) compilation.


408. Scikit Learn 1.0: New Features in Python Machine Learning Library
Scikit-learn is the most popular open-source and free python machine learning library for Data scientists and Machine learning practitioners. The scikit-learn library contains a lot of efficient tools for machine learning and statistical modeling including classification, regression, clustering, and dimensionality reduction.

409. 5 Data Science Interview Questions via Facebook, Twitch, and Postmates
There are data science interview questions that I’ve collected in the first few months of 2021 from Facebook, Twitch, Postmates, and more.

410. The Ultimate Tutorial On How To Do Web Scraping
Mastering Web-Scraping like a boss. Data Extraction Tips & Insights, Use Cases, Challenges... Everything you need to know🔥

411. What is OpenAI's Whisper Model?
Have you ever dreamed of a good transcription tool that would accurately understand what you say and write it down? Not like the automatic YouTube translation tools… I mean, they are good but far from perfect. Just try it out and turn the feature on for the video, and you’ll see what I’m talking about.

412. Data from a Female Point of View
Why you need more women in data science nowMade with ❤ by Formulate.by

413. Deep Learning is Already Dead: Towards Artificial Life with Olaf Witkowski
Olaf Witkowski is the Chief Scientist at Cross Labs, which aims to bridge the divide between intelligence science and AI technology. A researcher of artificial life, Witkowski started in artificial intelligence by exploring the replication of human speech through machines. He founded Commentag in 2007, and in 2009 moved to Japan to continue research, where he first became interested in artificial life.
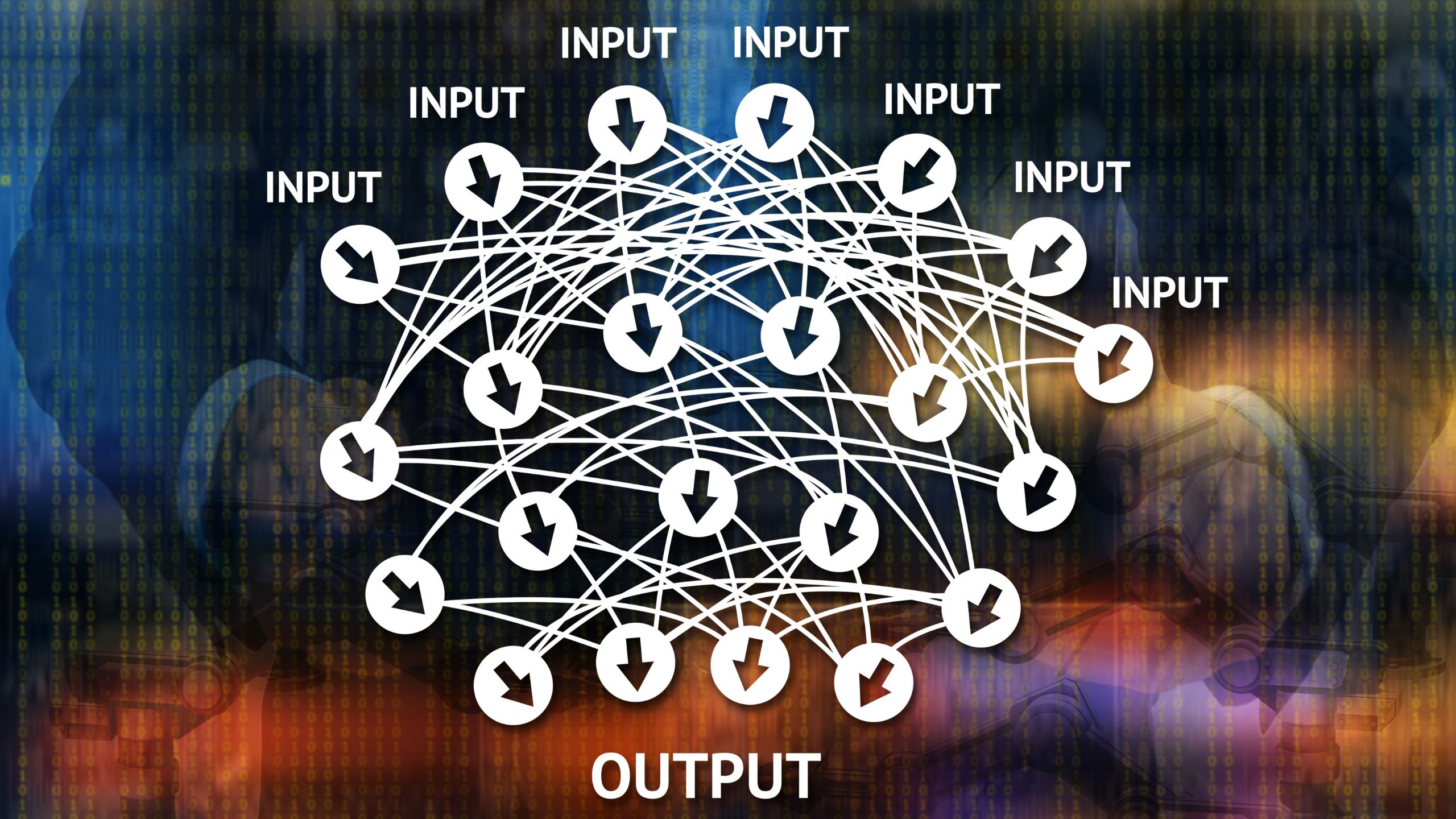
414. Building a Data Management Strategy: Importance, Principles, Roadmap
Already routinely called the currency, the lifeblood, and the new oil of the modern business world, data promises organizations unbeatable competitive advantages.


415. An Outsider's Journey Through Kaggle
There are many great resources for learning data science and machine learning out there, but the one thing that might be missing is a live accounting of a non-technical individual learning these skills. I use the term “outsider” in the title because I don’t feel like I have the typical background that most people do on Kaggle. I am not a machine learning expert, mathematician, or expert computer programmer. I have experience in finance and law, not computer science or statistics.

416. What is a Data Reliability Engineer?
With each day, enterprises increasingly rely on data to make decisions.


417. How to Consolidate Real-Time Analytics From Multiple Databases
Have you ever waited overnight for that report from yesterday’s sales? Or maybe you longed for the updated demand forecast that predicts inventory requirements from real-time point-of-sale and order management data. We are always waiting for our analytics. And worse yet, it usually takes weeks to request changes to our reports. To add insult to injury, you keep getting taxed for the increasing costs of the specialized analytics database.

418. Partial Dependence Plots: How to Discover Variables Influencing a Model
Quick techniques on how to find which variables are influencing the model results and by how much and how to visualize using Partial dependence plots.


419. On Knowledge Graphs and Grakn, with Daniel from Grakn Labs
This AMA featured Daniel Crowe at Grakn Labs - the inventors of Grakn, a database (knowledge graph) technology that serves as the foundation of intelligent sys.


420. How To Productionalize ML By Development Of Pipelines Since The Beginning
Writing ML code as pipelines from the get-go reduces technical debt and increases velocity of getting ML in production.

421. Open-Source COVID-19 ML Datasets; Models; Tools for Data Scientists
A look at machine learning-based approaches to global management of COVID-19—including open source project initiatives supported by Google and more.
422. 10 Key Skills Every Data Engineer Needs
Bridging the gap between Application Developers and Data Scientists, the demand for Data Engineers rose up to 50% in 2020, especially due to increase in investments in AI-based SaaS products.

423. Logistic Regression: Train Model In Python And Use It on Angular Front End
Demo for this article can be found here.


424. How Synthetic Data is Accelerating Computer Vision
In the spring of 1993, a Harvard statistics professor named Donald Rubin sat down to write a paper. Rubin’s paper would go on to change the way that artificial intelligence is researched and practiced, but its stated goal was more modest: analyze data from the 1990 U.S. census, while preserving the anonymity of its respondents.


425. Debunking The Top Myths Surrounding AI
Myths about artificial intelligence range from fearful reports of robots to outlandish expectations of the technology. Today, consumers encounter artificial intelligence continuously through smartphones, customer service centers, websites, and appliances. Surveys show that nearly nine in 10 Americans use some form of artificial intelligence device, and 79% of people report AI having a perceived positive impact on their lives. Despite the overwhelmingly positive uptake of the technology, films, art, and literature have long warned about the potential dangers of AI in science fiction storytelling. So, how much of this is based on reality?

426. Using Python For Finance: How To Analyze Profitability Margin
Learn how to perform a profitability analysis by peer companies using Python

427. Pickling and Unpickling in Python
In this blog, you will learn about the Pickling and Unpickling process, although it is quite simple it is very important and useful.

428. Why Data Science Competitions are Important & How to Get Started
To become a Data Scientist, you have to learn, gain the required skills and practice a lot to get more experience. Participating in data science competitions has been one of the best approaches to help beginners in data science get more experience and finally apply for job opportunities.

429. Foundation Series: Data Science, Psychohistory, and the Future of Humanity
A world where the future of humanity can be predicted through an interdisciplinary science called psychohistory! A data scientist's review of Foundation Series.

430. Global Economic Impact of AI: Facts and Figures
Summarization of Research Insights from Emerj, Harvard Business Review, MIT Sloan, and Mckinsey

431. How Uber Uses AI to Improve Deliveries
How can Uber deliver food and always arrive on time or a few minutes before? How do they match riders to drivers so that you can always find a Uber? All that while also managing all the drivers?!

432. Another Self-Driving Car Accident: New AI Development Lesson To Learn From
(Source: https://blogs.nvidia.com)


433. From Anomalies to Crypto-Strategies: Factor Investing for Crypto-Assets
Let’s do a quick test, try to think about how many times you’ve heard expressions like this:

434. My Weird Career Transition From MBA to Data Science
Yes you read it correctly! I am calling my transition from being an MBA to being the Analytics Manager in a well known consumer retail brand a "WEIRD" one. And why do I say that? Because during my 5 year journey in data science, I have had the opportunity to work with a lot of business stakeholders like marketing head, brand managers, sales heads etc. and many a times they have asked me about my educational background. I would like to think that they asked this because of my ability to present the solutions keeping the business context and execution feasibility in mind. Well, the reason for asking this might be different for every individual, when I tell them that I am an MBA, their reply has always been the same, which is "What made you choose a technical career path after pursuing MBA?" And hence I decided to write this post to share my thoughts over 2 things:


435. Online Dating From A Data Analysis Perspective: A Deep Dive
Love in the time of COVID is a… challenge, to say the least.

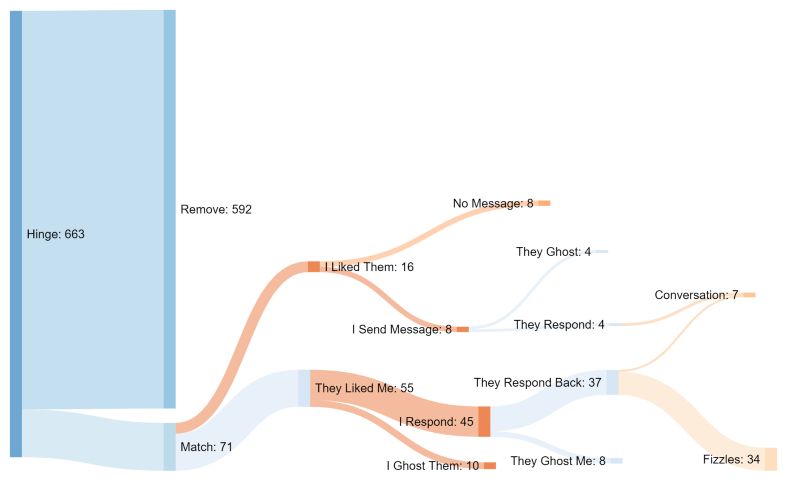
436. 8 Skills Required To Become A Data Scientist
Back in 2016, Glassdoor declared that being a Data Scientist was the best job in America.


437. How to Sort Array Elements: An Essential Guide
I want to describe a common method used to sort array elements in alphabetical and numerical order.


438. How Neural Networks Hallucinate Missing Pixels for Image Inpainting
When a human sees an object, certain neurons in our brain’s visual cortex light up with activity, but when we take hallucinogenic drugs, these drugs overwhelm our serotonin receptors and lead to the distorted visual perception of colours and shapes. Similarly, deep neural networks that are modelled on structures in our brain, stores data in huge tables of numeric coefficients, which defy direct human comprehension. But when these neural network’s activation is overstimulated (virtual drugs), we get phenomenons like neural dreams and neural hallucinations. Dreams are the mental conjectures that are produced by our brain when the perceptual apparatus shuts down, whereas hallucinations are produced when this perceptual apparatus becomes hyperactive. In this blog, we will discuss how this phenomenon of hallucination in neural networks can be utilized to perform the task of image inpainting.


439. Detecting Changes in COVID-19 Cases with Bayesian Models
Bayesian change point model to estimate the date that the number of new COVID-19 cases starts to flatten in different countries.


440. The Effectiveness of AI and ML on Supply Chains Amidst a Global Pandemic
Covid-19 's impact on the supply chain industry has been very predominant. How to mitigate the situation by making the best of different optimization.

441. How To Create a Useful Educational Product for Adults using Motivational Design
The main metric for educational product is it's completition rate. To improve it, one can use the principles of motivational design.

442. The Issue Of Machine Ethics and Robot Rights
Machine ethics and robot rights are quickly becoming hot topics in artificial intelligence/robotics communities. We will argue that the attempts to allow machines to make ethical decisions or to have rights are misguided. Instead we propose a new science of safety engineering for intelligent artificial agents. In particular we issue a challenge to the scientific community to develop intelligent systems capable of proving that they are in fact safe even under recursive self-improvement.

443. The Applications of Python Programming Language
Python is trending as the second most popular programming language in the world and grabbed its position edging out Java.


444. My Favorite Free Excel Courses for Programmers, Data Analysts, and IT Professionals
If you want to learn Microsoft Excel, a productivity tool for IT professionals, and looking for free online courses, then you have come to the right place.


445. Making It Easier To Deploy Machine Learning For All [A Deep Dive]
With the quality of machine learning packages being developed today, testing and creating models couldn’t be easier. Data scientists can simply import their favorite library and have immediate access to dozens of cutting edge algorithms.

446. Machine Learning Consulting: Does Your Business Really Need It?
Written by Oleksii Tsymbal, Chief Innovation Officer at MobiDev.


447. Text Classification Models: All Tips And Tricks From 5 Kaggle Competitions
In this article (originally posted by Shahul ES on the Neptune blog), I will discuss some great tips and tricks to improve the performance of your text classification model. These tricks are obtained from solutions of some of Kaggle’s top NLP competitions.


448. Integrate AI into Data Mapping to Drive Business Decision Making
Prior to analyzing large chunks of data, enterprises must homogenize them in a way that makes them available and accessible to decision-makers. Presently, data comes from many sources, and every particular source can define similar data points in different ways. Say for example, the state field in a source system may exhibit “Illinois” but the destination keeps it is as “IL”.


449. Data Science From Scratch
Data Science, which is also known as the sexiest job of the century, has become a dream job for many of us. But for some, it looks like a challenging maze and they don’t know where to start. If you are one of them, then continue reading.

450. Some Shocking Data Analyses About Stablecoins
Stablecoins are one of the most relevant developments in the crypto ecosystem and one that has been increasingly getting traction. Recently, I presented a session that highlighted some interesting analyses that arise from applying data science methods on stablecoin’s blockchain data. The slide deck and video from the session will be available soon but I thought I share some of the most intriguing data points.

451. What Happened to Hadoop? What Should You Do Now?
by Monte Zweben & Syed Mahmood of Splice Machine


452. How to Start with Web Scraping and Why You Don't Need to Code
Collecting data from the web can be the core of data science. In this article, we'll see how to start with scraping with or without having to write code.

453. The Python Panda Package Tutorial
Key methods to understanding and utilizing pandas


454. How to Manage Machine Learning Products Part I: Why is managing machine learning products so hard?
In my previous article, I talked about the biggest difference that Machine Learning (ML) brings: ML enables a move away from having to program the machine to true autonomy (self-learned). Machines make predictions and improve insights based on patterns they identify in data without humans explicitly telling them what to do. That’s why ML is particularly useful for challenging problems that are difficult for people to explain to machines. It also means that ML can make your products more personalized, more automated, and more precise. Advanced algorithms, massive data, and cheap hardware are enabling ML to become the main driver of GDP.


455. AutoScraper and Flask: Create an API From Any Website in Less Than 5 Minutes
In this tutorial, we are going to create our own e-commerce search API with support for both eBay and Etsy without using any external APIs.


456. Content-Based Recommender Using Natural Language Processing (NLP)
A guide to build a movie recommender model based on content-based NLP: When we provide ratings for products and services on the internet, all the preferences we express and data we share (explicitly or not), are used to generate recommendations by recommender systems. The most common examples are that of Amazon, Google and Netflix.

457. Understanding The Concept of Clustering In Unsupervised Learning
What is hierarchical clustering in unsupervised learning?

458. Creativity in Data Analytics is About More than Data Visualization
I recently attended a networking event where I spoke to a range of graduates who were looking at prospective careers in the data science and adjacent spaces.

459. Why Python is Best Programming Language for Data Science & Machine Learning?
If you want to become a Data Scientist and are curious about which programming language should you learn then you have come to the right place.

460. Your Guide to Natural Language Processing (NLP)
Everything we express (either verbally or in written) carries huge amounts of information. The topic we choose, our tone, our selection of words, everything adds some type of information that can be interpreted and value extracted from it. In theory, we can understand and even predict human behaviour using that information.

461. How a Data Scientist Sees a Deck of Cards
The Data Scientist Creativity Paradox

462. How to Generate Synthetic Data?
A synthetic data generation dedicated repository. This is a sentence that is getting too common, but it’s still true and reflects the market's trend, Data is the new oil. Some of the biggest players in the market already have the strongest hold on that currency.

463. LegalTech - An Overview and Prospective Future
A primer to understand how technology is poised to disrupt law


464. Fixing the Cold Start Problem in Recommender Systems
A cold start problem is when the system cannot draw any inferences for users or items about which it has not yet gathered sufficient information. Simply put, if you have no or less initial data, what recommendation is the system supposed to give to the user?


While recommender systems are useful for users who have some previous interaction history, the same might not be the case for a new user or a newly added item. The problem is that in both cases we don’t have any history to base the recommendations on.
465. 3 Easy Ways to Improve The Performance Of Your Python Code
I. Benchmark, benchmark, benchmark


466. Top 12 Javascript Libraries for Machine Learning
Rapidly evolving technologies like Machine Learning, Artificial Intelligence, and Data Science were undoubtedly among the most booming technologies of this decade. The s specifically focusses on Machine Learning which, in general, helped improve productivity across several sectors of the industry by more than 40%. It is a no-brainer that Machine Learning jobs are among the most sought-after jobs in the industry.

467. Federal Biometrics: How Does the Government Use Biometrics Data?
468. We Kinda Bypassed Firebase's Paywall: Here's How
Some time ago, a few friends and I decided to build an app. We duck-taped our code together, launched our first version, then attracted a few users with a small marketing budget.

469. The Art of Data Storytelling: How to Make Your Data Impactful
Data is everywhere: whether you choose a new location for your business or decide on the color to use in an ad, data is an invisible advisor that helps make impactful decisions. With quite a number of resources to choose from, data is becoming more accessible, day by day. But as soon as it has been collected, one inevitable question arises: how do I turn this data into insights that can be acted upon?


470. Google's New AI Creates Summaries of Your Documents in Google Docs
Google recently announced a new model for automatically generating summaries using machine learning, released in Google Docs that you can already use.

471. Deconstructing a Serverless Cloud OS
Responding to the Serverless Revolution

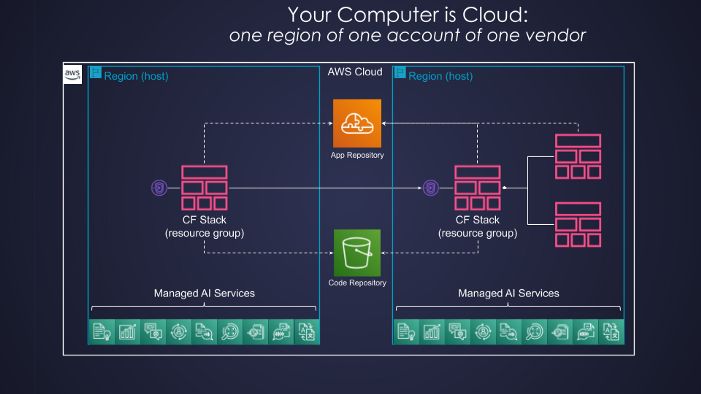
472. 5 Upcoming Online Machine Learning Conferences in 2020
Machine learning conferences have always played an important role in the world of data science. They're a place to announce new research, discuss current issues, and connect with the community. They also help to promote new areas of research and development through Q&A sessions, workshops, and tutorials.


473. An A-Z Guide to Decision Trees
In the beginning, learning Machine Learning (ML) can be intimidating. Terms like “Gradient Descent”, “Latent Dirichlet Allocation” or “Convolutional Layer” can scare lots of people. But there are friendly ways of getting into the discipline, and I think starting with Decision Trees is a wise decision.


474. TikTok: A Ticking Time Bomb?
One of the most popular apps of 2019, TikTok ruled the download charts in both the Android and Apple markets. Having more than 1.5 billion downloads and approximately half a billion monthly active users, TikTok definitely has access to a trove of users. With that large user base comes a hidden goldmine: their data.

475. Data Science Training and Data Science - Machine Learning With Python
The requirement for its stockpiling also grew as the world entered the period of huge information. The principle focal point of endeavors was on structure framework and answers for store information. When frameworks like Hadoop tackled the issue of capacity, preparing of this information turned into a challenge. Data science began assuming a crucial job to take care of this issue. Information Science is the fate of Artificial Intelligence as It can increase the value of your business.


476. America's Secret Pager Giant
Early January 2022, I spontaneously bought a pager. I looked into the US pager market, and to my surprise...

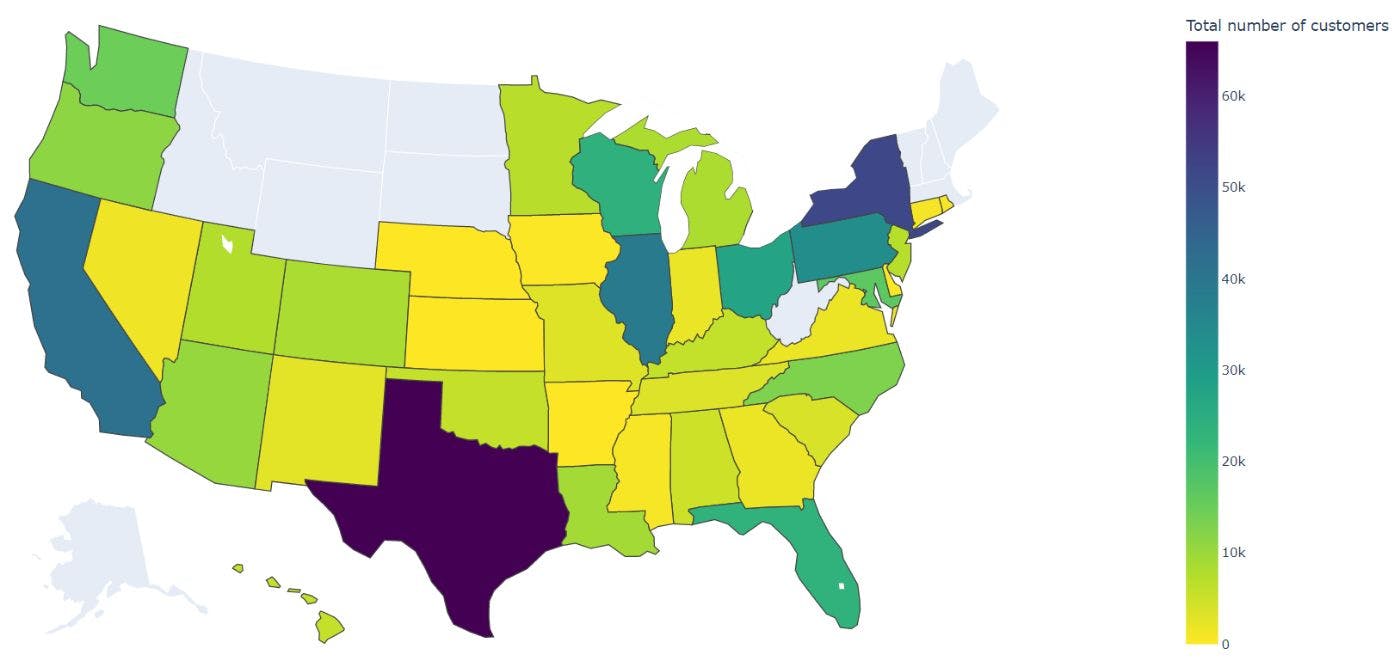
477. “AI Sells, Data Delivers!”
Context

478. Start With Machine Learning
We all have to deal with data, and we try to learn about and implement machine learning into our projects. But everyone seems to forget one thing... it's far from perfect, and there is so much to go through! Don't worry, we'll discuss every little step, from start to finish 👀.
479. How to use Python Seaborn for Exploratory Data Analysis
This is a tutorial of using the seaborn library in Python for Exploratory Data Analysis (EDA).

480. Scikit-Learn 0.24: Top 5 New Features
For any data scientists & machine-learning engineers use scikit-learn for different machine learning projects here are 5 best new features in scikit-learn 0.24


481. How LZ78 Compression Algorithm Works
How does the GIF format work?

482. Introduction 5 Different Types of Text Annotation in NLP
Natural language processing (NLP) is one of the biggest fields of AI development. Numerous NLP solutions like chatbots, automatic speech recognition, and sentiment analysis programs can improve efficiency and productivity in various businesses around the world.

483. Exploring the Top Data Science and Machine Learning (DSML) Platforms of 2022
Exploring Data Science and Machine Learning (DSML) Platforms
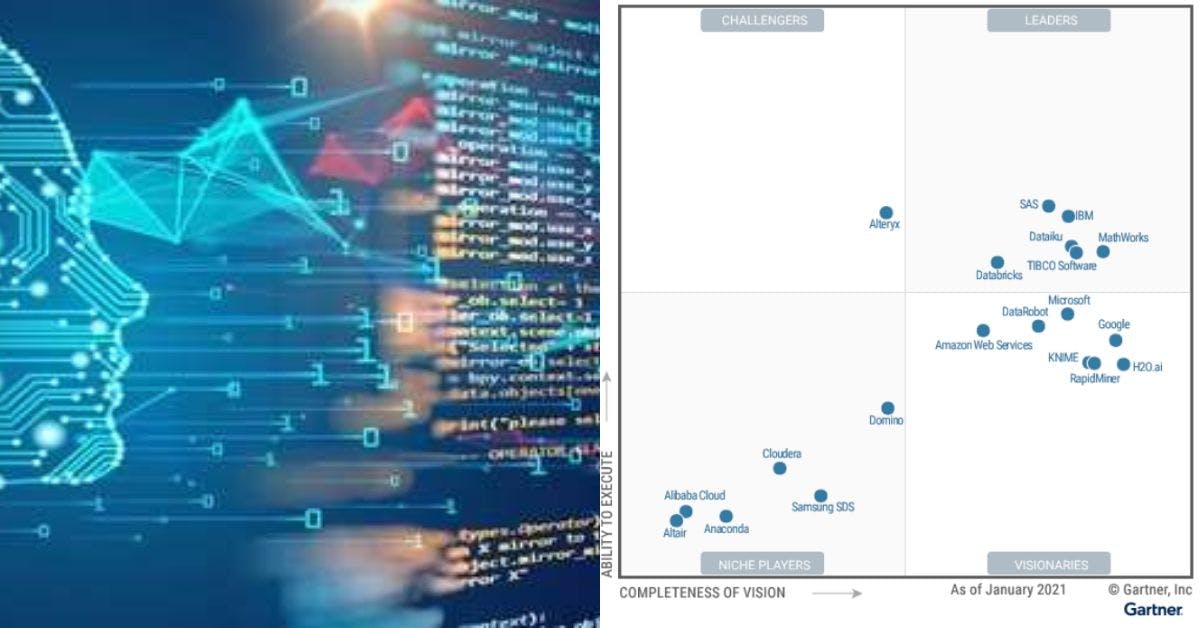
484. Corona: Seven Ways to Smash the Curve Now
Everyone knows they need to act now to stop the coronavirus.


485. How to Play Chess Using a GPT-2 Model
OpenAI’s transformer-based language model GPT-2 definitely lives up to the hype. Following the natural evolution of Artificial Intelligence (AI), this generative language model drew a lot of attention by engaging in interviews and appearing in the online text adventure game AI Dungeon.

486. Image Segmentation: Tips and Tricks from 39 Kaggle Competitions
Imagine if you could get all the tips and tricks you need to hammer a Kaggle competition. I have gone over 39 Kaggle competitions including

487. Data Science As A Career: 12 Steps From Beginner to Pro
12 steps for those looking to build a career in Data Science from scratch. Below there is a guide to action and a scattering of links to useful resources.


488. Democratizing AI: How Difficult Can it Be?
There are a number of similarities when we talk about some of the top names worldwide including Google, Facebook, Microsoft, Amazon, etc.

489. Loan Risk Prediction Using Neural Networks
A Step-by-Step Guide (With a Healthy Dose of Data Cleaning)

490. Why I'm in love with Julia
In this article I'm going to make a case why people serious about creating machine learning algorithms and high performance data science programming should use Julia rather than Python.

491. Scraping with Selenium 101: The Big Hole on Data Scientists Toolset [Part 1]
Usually forgotten in all Data Science masters and courses, Web Scraping is, in my honest opinion a basic tool in the Data Scientist toolset, as is the tool for getting and therefore using external data from your organization when public databases are not available.

492. 4 Tips To Become A Successful Entry-Level Data Analyst
Companies across every industry rely on big data to make strategic decisions about their business, which is why data analyst roles are constantly in demand.


493. Scrape And Compare eCommerce Products Using Proxy Scraper
In this post, we are going to learn web scraping with python. Using python we are going to Scrape websites like Walmart, eBay, and Amazon for the pricing of Microsoft Xbox One X 1TB Black Console. Using that scraper you would be able to scrape pricing for any product from these websites. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.


494. How AI Could Save the 3D Printing Industry and the Future of Machines
3D printing is a billion-dollar market with a variety of use cases- from healthcare, replicas to architecture, airplane parts.


495. Using Data to Predict Bike Share Demand In London Without Code
2019 is a strange time for transportation. People are riding weird scooters around and using their cellphones to order rides. New York City and London have begun taxing cars that enter city centers in order to cut down on drivers. Transportation alternatives have emerged such as Zipcar, Lime, Bird, and a variety of eBikes or bike shares have increased tremendously proving it’s time to get your rental fleet ready.

496. 21 Best Coursera Courses and Certificates for IT Professionals to Learn Data Science and Cloud
Here are the top 20 Coursera Courses and Certifications to Learn Data Science, Cloud Computing, and Python.

497. 7 Types of Data Bias in Machine Learning
Data bias in machine learning is a type of error in which certain elements of a dataset are more heavily weighted and/or represented than others. A biased dataset does not accurately represent a model’s use case, resulting in skewed outcomes, low accuracy levels, and analytical errors.

498. Four Novel Machine Learning Methods for Analyzing Blockchain Datasets
Using machine learning to analyze blockchain datasets is a fascinating challenge. Beyond the incredible potential of uncovering unknown insights that help us understand the behavior of crypto-assets, blockchain datasets presents very unique challenges to a machine learning practitioner. Many of these challenges translate into major roadblocks for most traditional machine learning techniques. However, the rapid evolution of machine intelligence technologies has enabled the creation of novel machine learning methods that result very applicable to the analysis of blockchain datasets. At IntoTheBlock, we regularly experiment with these new methods to improve the efficiency of our market intelligence signals. Today, I would like to provide a brief overview of some novel ideas in the machine learning space that can yield interesting results in the analysis of blockchain data.


499. Building a Monte Carlo Markov Chain Pipeline Using Luigi
A few months ago I was accepted into a data science bootcamp - Springboard, for their data science career track. As part of this bootcamp I had to work on Capstone projects that would help build my portfolio, show my ability to extract, clean up data, build models and extract insights from said models. For my first project I opted to build a Monte Carlo Markov Chain pipeline initially with the objective of building a multi-touch attribution model that would help me understand conversion rates from different states in the signup process and use that to understand which channels appeared to deliver the greatest conversion rates for users coming through a given landing page and transitioning through the different signup states defined in my dataset.


500. Top 10 Data Science Libraries in Python
Data Science Libraries that will shine this year.


501. Semantic Search Queries Return More Informed Results
In this article, you will learn what a vector search engine is and how you can use Weaviate with your own data in 5 minutes.

502. 10 Data Science and Machine Learning Libraries for Python

503. 3 Data Distributions for Counts in Layman’s Terms
Counts are everywhere, so no matter your background, these data distributions will come in handy.

504. PULSE: Photo Upsampling Makes Blurry Faces 60 Times Sharper
The new PULSE: Photo Upsampling algorithm transforms a blurry image into a high-resolution image.

505. What Is Weaviate And How To Create Data Schemas In It
What is a Weaviate schema, why you need one and how to define one to store your own data.

506. Use the 80/20 Rule with Moderation
The 80/20 rule, a.k.a. Pareto principle, has been perpetuated along the lines: "80% of the effects come from 20% of the causes." Different cases where the rule emerges have been studied, in the last century, by great personalities such as Vilfredo Pareto (land ownership in Italy), George Kingsley Zipf (word frequency in Languages), and Joseph M. Juran (quality management in industries). Working as a Data Scientist, I have seen enough of the 80/20 rule being invoked in business meetings followed by a round of applause 👏👏👏. Also, I have read numerous LinkedIn posts alike. Most times, it is just a reckless stretch of the rule. But what is the danger here, if any? After all, profits matter more than mathematical and statistical rigor.

507. How to Get Started with Data Version Control (DVC)
Data Version Control (DVC) is a data-focused version of Git. In fact, it’s almost exactly like Git in terms of features and workflows associated with it.

508. Top 10 On-Demand IT Certifications With Highest Pay: 2020 Edition
Information Technology (IT) certification can enrich your IT career and pave the way for a profitable way. As the demand for IT professionals increases, let's look at 10 high-paying certifications. The technology landscape is constantly changing and the demand for information technology certification is also getting higher. Popular areas of IT include networking, cloud computing, project management, and security. Eighty percent of IT professionals say certification is useful for careers and the challenge is to identify areas of interest. Let's take a look at the certifications that are most needed and the salaries that correspond to them.

509. Web Scraping with python
In this post, we are going to scrape Yahoo Finance using python. This is a great source for stock-market data. We will code a scraper for that. Using that scraper you would be able to scrape stock data of any company from yahoo finance. As you know I like to make things pretty simple, for that, I will also be using a web scraper which will increase your scraping efficiency.

510. How To Implement 3D Human Pose Estimation System In AI Fitness Apps
“Is it possible for a technology solution to replace fitness coaches? Well, someone still has to motivate you saying “Come On, even my grandma can do better!” But from a technology point of view, this high-level requirement led us to 3D human pose estimation technology.


511. Analyzing Data From U.S. Road Accidents With Data Visualization
In this article, we would be analyzing data related to US road accidents, which can be utilized to study accident-prone locations and influential factors.


512. How I Analyzed One Million Voter Records in Manhattan
What if you could instantly visualize the political affiliation of an entire city, down to every single apartment and human registered to vote? Somewhat surprisingly, the City of New York made this a reality in early 2019, when the NYC Board of Elections decided to release 4.6 million voter records online, as reported by the New York Times. These records included full name, home address, political affiliation, and whether you have registered in the past 2 years. The reason according to this article was:

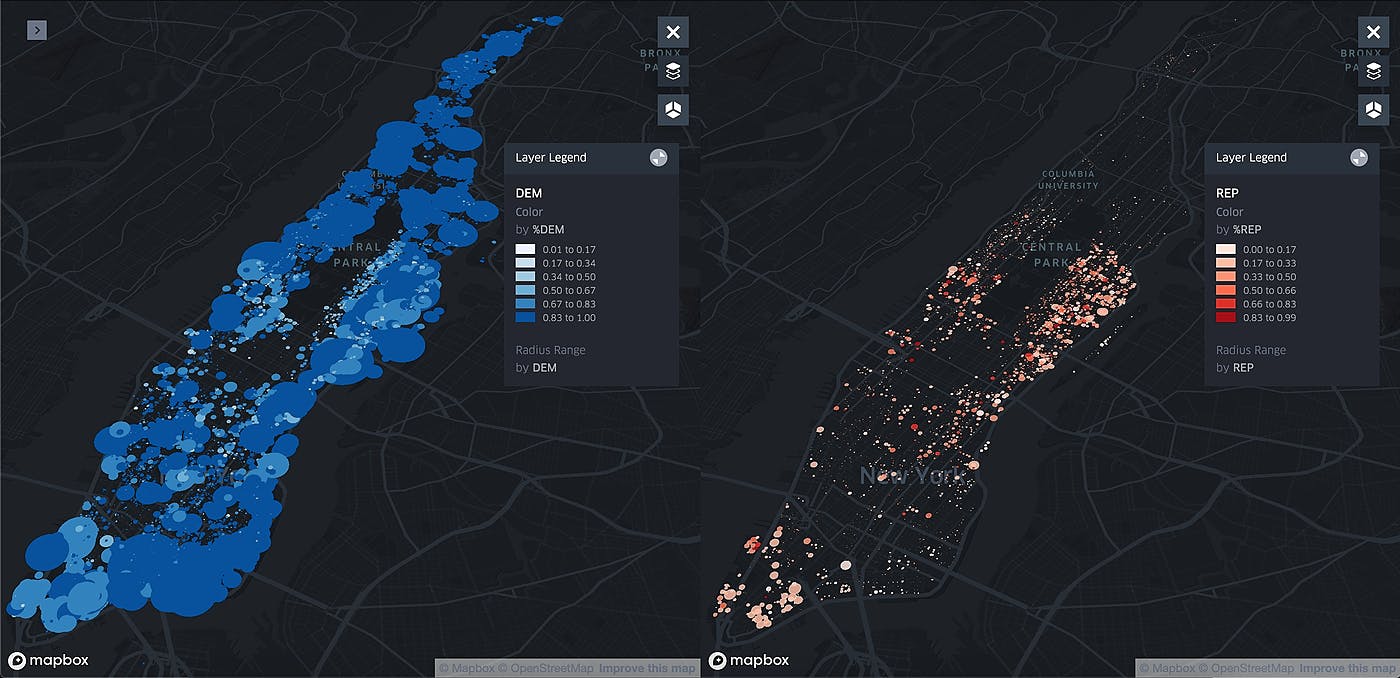
513. How BitMEX Wallets Impact the Price of Bitcoin
Part of building a profitable trading strategy is quickly testing novel ideas. These tend to be the money makers in the rare case that they prove useful once you can integrate them into your strategy.


514. Twitter Sentiment Analysis for the 2019 Lok Sabha Elections
Introduction


515. Top 6 CI/CD Practices for End-to-End Development Pipelines
Maximizing efficiency is about knowing how the data science puzzles fit together and then executing them.

516. 5 Papers on Face Recognition Every Data Scientist Should Read
Facial recognition, is one of the largest areas of research within computer vision. This article will introduce 5 face recognition papers for data scientists.

517. Essential Programming: Sorting Algorithms
The next task in your calendar, the ranking position of your favorite sport team in the league, the contact list in your cell phone, all of these have an order. Order matters when we process information. We use order to make sense of our lives and to optimize our decisions. Imagine looking for a word in a dictionary with a mixed alphabetical order, or trying to find the cheapest product in a disordered pricing list. We order stuff to make more sound decisions (which in reality is an illusion), and this makes us more confident on the results.

518. Therapy as a Service, Sex and Other Coping Mechanisms While Homebound
I remote-chat this afternoon with Stefan van Tulder, founder of Talent Data Labs and one of the best brains I know in the field of Behavioural Science, Quantitative Psychology and Psychometrics. He’s born in Amsterdam and is currently home-bound in his lovely apartment in the historic museum quarter.

519. How To Become A Data Scientist: Skills & Courses To Learn Data Science
The necessary skills to build a Data Scientist’s profile are business intelligence, statistical knowledge, technical skills, data structure, and more.

520. Graph Algorithms, Neural Networks, and Graph Databases
Year of the Graph Newsletter, September 2019


521. The Ultimate Guide to Strategic Thinking for Data Scientists
While HBR declared "Data Scientist" the sexiest job of the 21st century, let's admit that the prevailing view is that it's a geeky, highly-technical field.

522. The Essential Guide to Data Augmentation in NLP
There are many tasks in NLP from text classification to question answering, but whatever you do the amount of data you have to train your model impacts the model performance heavily.

523. AI and Machine Learning for Manufacturing Industry: Use Cases
Artificial Intelligence(AI) has already proven to solve some of the complex problems across the wide array of industries like automobile, education, healthcare, e-commerce, agriculture etc. and yield greater productivity, smart solutions, improved security and care, business intelligence with the aid of predictive, prescriptive and descriptive analytics. So what can AI do for Manufacturing Industry?

524. A Beginner Guide to Incorporating Tabular Data via HuggingFace Transformers
Transformer-based models are a game-changer when it comes to using unstructured text data. As of September 2020, the top-performing models in the General Language Understanding Evaluation (GLUE) benchmark are all BERT transformer-based models. At Georgian, we often encounter scenarios where we have supporting tabular feature information and unstructured text data. We found that by using the tabular data in these models, we could further improve performance, so we set out to build a toolkit that makes it easier for others to do the same.


525. Future of Marketing: How Data Science Predicts Consumer Behavior
Gradually, as the post-pandemic phase arrived, one thing that helped marketers predict their consumer behavior was Data Science.


526. Top 25 Quotes from ML Heroes Interviews (+ an exciting announcement!)
Re-boot of “Interview with Machine Learning Heroes” and collection of best pieces of advice


527. 10 Best African Language Datasets for Data Science Projects
A list of African language datasets from across the web that can be used in numerous NLP tasks.


528. The Bitcoin Mempool: Where Transactions Take Flight
One of Bitcoin’s strengths and the thing that makes it unique in the finance world is its radical transparency. Blockchain data is like a window, you can see right through it.


529. Using GANs to Create Anime Faces via Pytorch
Most of us in data science have seen a lot of AI-generated people in recent times, whether it be in papers, blogs, or videos. We’ve reached a stage where it’s becoming increasingly difficult to distinguish between actual human faces and faces generated by artificial intelligence. However, with the current available machine learning toolkits, creating these images yourself is not as difficult as you might think.

530. Methods and Plugins to Spot Deepfakes and AI-Generated Text
With the emergence of incredibly powerful machine learning technologies, such as Deepfakes and Generative Neural Networks, it is much easier now to spread false information. In this article, we will briefly introduce deepfakes and generative neural networks, as well as a few ways to spot AI-generated content and protect yourself against misinformation.

531. 7 Challenges in Marketing AI & Machine Learning Solutions
This article will help our readers to identify and understand the challenges faced by the AI development companies to market the AI & ML products.

532. Top 5 AI Articles of February 2022 Every Data Scientist Should Read
Here are the five best articles related to artificial intelligence in February, hoping they will make you want to learn more and visit their website.
533. How To Meaningfully Interpret COVID-19 Data

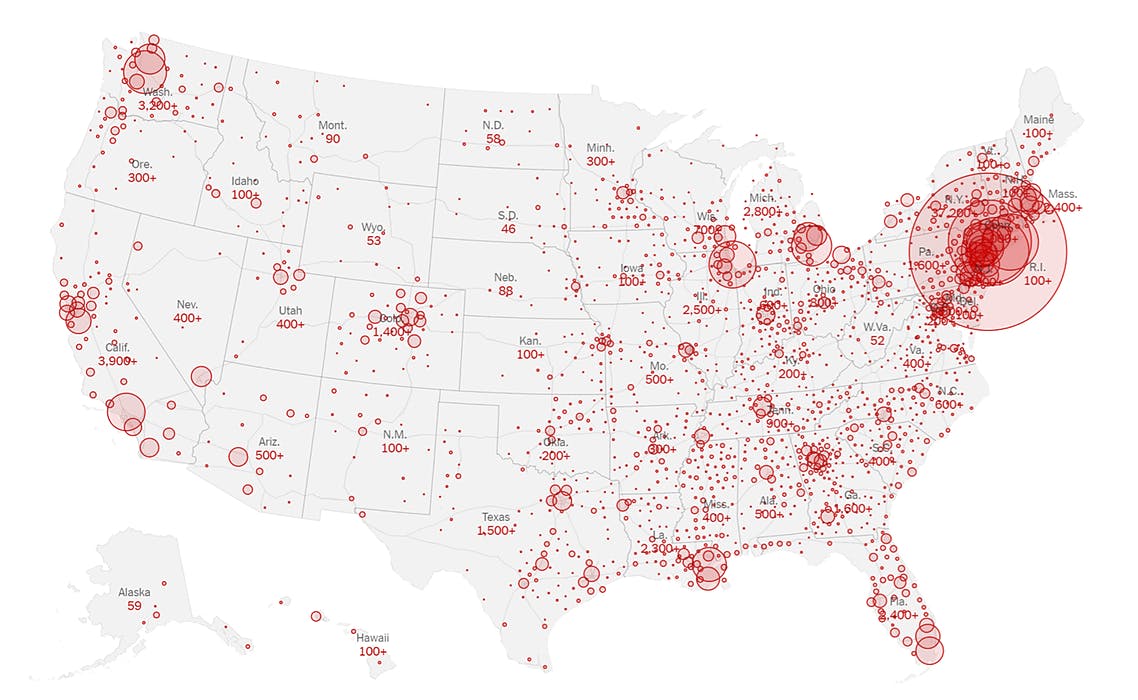
534. The Ethical AI Libraries that are Critical for Every Data Scientist to Know
With the exponential rise in applications of AI, Data Science, and Machine Learning these are the critical Ethical AI Libraries to know.

535. Realistic Face Manipulation in Videos With AI
You've most certainly seen movies like the recent Captain Marvel or Gemini Man where Samuel L Jackson and Will Smith appeared to look like they were much younger. This requires hundreds if not thousands of hours of work from professionals manually editing the scenes he appeared in. Instead, you could use a simple AI and do it within a few minutes.


536. HDTree: A Customizable and Interactable Decision Tree Written in Python
Introducing a customizable and interactable Decision Tree-Framework written in Python


537. A Complete(ish) Guide to Python Tools You Can Use To Analyse Text Data
Exploratory data analysis is one of the most important parts of any machine learning workflow and Natural Language Processing is no different.

Thank you for checking out the 537 most read stories about Data Science on HackerNoon.
Visit the /Learn Repo to find the most read stories about any technology.










